

| ИНФОРМАЦИЯ | |
© Воеводин Вл.В.
Курс лекций
"Параллельная
обработка данных"
Одним из наиболее популярных средств программирования компьютеров с общей памятью, базирующихся на традиционных языках программирования и использовании специальных комментариев, в настоящее время является технология OpenMP. За основу берется последовательная программа, а для создания ее параллельной версии пользователю предоставляется набор директив, процедур и переменных окружения. Стандарт OpenMP разработан для языков Фортран, С и С++. Поскольку все основные конструкции для этих языков похожи, то рассказ о данной технологии мы будем вести на примере только одного из них, а именно на примере языка Фортран.
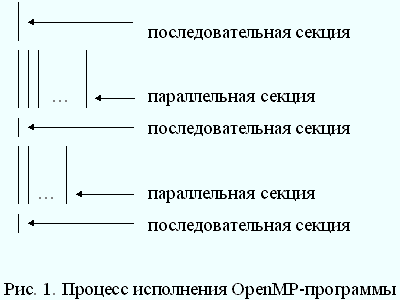
Как, с точки зрения OpenMP, пользователь должен представлять свою параллельную программу? Весь текст программы разбит на последовательные и параллельные области (см. рис.1). В начальный момент времени порождается нить-мастер или "основная" нить, которая начинает выполнение программы со стартовой точки. Здесь следует сразу сказать, почему вместо традиционных для параллельного программирования процессов появился новый термин - нити (threads, легковесные процессы). Технология OpenMP опирается на понятие общей памяти, поэтому она, в значительной степени, ориентирована на SMP-компьютеры. На подобных архитектурах возможна эффективная поддержка нитей, исполняющихся на различных процессорах, что позволяет избежать значительных накладных расходов на поддержку классических UNIX-процессов.
Основная нить и только она исполняет все последовательные области программы. При входе в параллельную область порождаются дополнительные нити. После порождения каждая нить получает свой уникальный номер, причем нить-мастер всегда имеет номер 0. Все нити исполняют один и тот же код, соответствующий параллельной области. При выходе из параллельной области основная нить дожидается завершения остальных нитей, и дальнейшее выполнение программы продолжает только она.
В параллельной области все переменные программы разделяются на два класса: общие (SHARED) и локальные (PRIVATE). Общая переменная всегда существует лишь в одном экземпляре для всей программы и доступна всем нитям под одним и тем же именем. Объявление же локальной переменной вызывает порождение своего экземпляра данной переменной для каждой нити. Изменение нитью значения своей локальной переменной, естественно, никак не влияет на изменение значения этой же локальной переменной в других нитях.
По сути, только что рассмотренные два понятия: области и классы переменных, и определяют идею написания параллельной программы в рамках OpenMP: некоторые фрагменты текста программы объявляется параллельными областями; именно эти области и только они исполняются набором нитей, которые могут работать как с общими, так и с локальными переменными. Все остальное - это конкретизация деталей и описание особенностей реализации данной идеи на практике.
Рассмотрим базовые положения и основные конструкции OpenMP. Все директивы OpenMP располагаются в комментариях и начинаются с одной из следующих комбинаций: !$OMP, C$OMP или *$OMP (напомним, что строка, начинающаяся с одного из символов '!', 'C' или '*' по правилам языка Фортран считается комментарием). В дальнейшем изложении при описании конкретных директив для сокращения записи мы иногда будем опускать эти префиксы, хотя в реальных программах они, конечно же, всегда должны присутствовать. Все переменные окружения и функции, относящиеся к OpenMP, начинаются с префикса OMP_ .
Описание параллельных областей. Для определения параллельных областей программы используется пара директив
!$OMP PARALLEL < параллельный код программы > !$OMP END PARALLEL
Для выполнения кода, расположенного между данными директивами, дополнительно порождается OMP_NUM_THREADS-1 нитей, где OMP_NUM_THREADS - это переменная окружения, значение которой пользователь, вообще говоря, может изменять. Процесс, выполнивший данную директиву (нить-мастер), всегда получает номер 0. Все нити исполняют код, заключенный между данными директивами. После END PARALLEL автоматически происходит неявная синхронизация всех нитей, и как только все нити доходят до этой точки, нить-мастер продолжает выполнение последующей части программы, а остальные нити уничтожаются.
Параллельные секции могут быть вложенными одна в другую. По умолчанию вложенная параллельная секция исполняется одной нитью. Необходимую стратегию обработки вложенных секций определяет переменная OMP_NESTED, значение которой можно изменить с помощью функции OMP_SET_NESTED.
Если значение переменной OMP_DYNAMIC установлено в 1, то с помощью функции OMP_SET_NUM_THREADS пользователь может изменить значение переменной OMP_NUM_THREADS, а значит и число порождаемых при входе в параллельную секцию нитей. Значение переменной OMP_DYNAMIC контролируется функцией OMP_SET_DYNAMIC.
Необходимость порождения нитей и параллельного исполнения кода параллельной секции пользователь может определять динамически с помощью дополнительной опции IF в директиве:
!$OMP PARALLEL IF( <условие> )Если <условие> не выполнено, то директива не срабатывает и продолжается обработка программы в прежнем режиме.
Мы уже говорили о том, что все порожденные нити исполняют один и тот же код. Теперь нужно обсудить вопрос, как разумным образом распределить между ними работу. OpenMP предлагает несколько вариантов. Можно программировать на самом низком уровне, распределяя работу с помощью функций OMP_GET_THREAD_NUM и OMP_GET_NUM_THREADS, возвращающих номер нити и общее количество порожденных нитей соответственно. Например, если написать фрагмент вида:
IF( OMP_GET_THREAD_NUM() .EQ. 3 ) THEN < код для нити с номером 3 > ELSE < код для всех остальных нитей > ENDIF ,то часть программы между директивами IF:ELSE будет выполнена только нитью с номером 3, а часть между ELSE:ENDIF - всеми остальными. Как и прежде, этот код будет выполнен всеми нитями, однако функция OMP_GET_THREAD_NUM() возвратит значение 3 только для нити с номером 3, поэтому и выполнение данного участка кода для третьей нити и всех остальных будет идти по-разному.
Если в параллельной секции встретился оператор цикла, то, согласно общему правилу, он будет выполнен всеми нитями, т.е. каждая нить выполнит все итерации данного цикла. Для распределения итераций цикла между различными нитями можно использовать директиву
!$OMP DO [опция [[,] опция]:]которая относится к идущему следом за данной директивой оператору DO.!$OMP END DO ,
Опция SCHEDULE определяет конкретный способ распределения итераций данного цикла по нитям:
Выбранный способ распределения итераций указывается в скобках после опции SCHEDULE, например:
!$OMP DO SCHEDULE (DYNAMIC, 10)В данном примере будет использоваться динамическое распределение итераций блоками по 10 итераций.
В конце параллельного цикла происходит неявная барьерная синхронизация параллельно работающих нитей: их дальнейшее выполнение происходит только тогда, когда все они достигнут данной точки. Если в подобной задержке нет необходимости, то директива END DO NOWAIT позволяет нитям уже дошедшим до конца цикла продолжить выполнение без синхронизации с остальными. Если директива END DO в явном виде и не указана, то в конце параллельного цикла синхронизация все равно будет выполнена. Рассмотрим следующий пример, расположенный в параллельной секции программы:
!$OMP DO SCHEDULE (STATIC, 2) DO i = 1, n DO j = 1, m A( i, j) = ( B( i, j-1) + B( i-1, j) ) / 2.0 END DO END DO !$OMP END DOВ данном примере внешний цикл объявлен параллельным, причем будет использовано блочно-циклическое распределение итераций по две итерации в блоке. Относительно внутреннего цикла никаких указаний нет, поэтому он будет выполняться последовательно каждой нитью.
Параллелизм на уровне независимых фрагментов оформляется в OpenMP с помощью директивы SECTIONS : END SECTIONS:
!$OMP SECTIONS < фрагмент 1> !$OMP SECTIONS < фрагмент 2> !$OMP SECTIONS < фрагмент 3> !$OMP END SECTIONSВ данном примере программист описал, что все три фрагмента информационно независимы, и их можно исполнять в любом порядке, в частности, параллельно друг другу. Каждый из таких фрагментов будет выполнен какой-либо одной нитью.
Если в параллельной секции какой-то участок кода должен быть выполнен лишь один раз (такая ситуация иногда возникает, например, при работе с общими переменными), то его нужно поставить между директивами SINGLE : END SINGLE. Такой участок кода будет выполнен нитью, первой дошедшей до данной точки программы.
Одно из базовых понятий OpenMP - классы переменных. Все переменные, используемые в параллельной секции, могут быть либо общими, либо локальными. Общие переменные описываются директивой SHARED, а локальные директивой PRIVATE. Каждая общая переменная существует лишь в одном экземпляре и доступна для каждой нити под одним и тем же именем. Для каждой локальной переменной в каждой нити существует отдельный экземпляр данной переменной, доступный только этой нити. Предположим, что следующий фрагмент расположен в параллельной секции:
I = OMP_GET_THREAD_NUM() PRINT *, IЕсли переменная I в данной параллельной секции была описана как локальная, то на выходе будет получен весь набор чисел от 0 до OMP_NUM_THREADS-1, идущих, вообще говоря, в произвольном порядке, но каждое число встретиться только один раз. Если же переменная I была объявлена общей, то единственное, что можно сказать с уверенностью - мы получим последовательность из OMP_NUM_THREADS чисел, лежащих в диапазоне от 0 до OMP_NUM_THREADS-1 каждое. Сколько и каких именно чисел будет в последовательности заранее сказать нельзя. В предельном случае, это может быть даже набор из OMP_NUM_THREADS одинаковых чисел I0. Предположим, что все процессы, кроме процесса I0, выполнили первый оператор, но затем их выполнение по какой-то причине было прервано. В это время процесс с номером I0 присвоил это значение переменной I, а поскольку данная переменная является общей, то одно и тоже значение затем и будет выведено каждой нитью.
Целый набор директив в OpenMP предназначен для синхронизации работы нитей. Самый распространенный способ синхронизации - барьер. Он оформляется с помощью директивы
!$OMP BARRIER .Все нити, дойдя до этой директивы, останавливаются и ждут пока все нити не дойдут до этой точки программы, после чего все нити продолжают работать дальше.
Пара директив MASTER : END MASTER выделяет участок кода, который будет выполнен только нитью-мастером. Остальные нити пропускают данный участок и продолжают работу с выполнения оператора, расположенного следом за директивой END MASTER.
С помощью директив
!$OMP CRITICAL [ (<имя_критической_секции>) ] ... !$OMP END CRITICAL [ (< имя_ критической_секции >) ],оформляется критическая секция программы. В каждый момент времени в критической секции может находиться не более одной нити. Если критическая секция уже выполняется какой-либо нитью P0, то все другие нити, выполнившие директиву для секции с данным именем, будут заблокированы, пока нить P0 не закончит выполнение данной критической секции. Как только P0 выполнит директиву END CRITICAL, одна из заблокированных на входе нитей войдет в секцию. Если на входе в критическую секцию стояло несколько нитей, то случайным образом выбирается одна из них, а остальные заблокированные нити продолжают ожидание. Все неименованные критические секции условно ассоциируются с одним и тем же именем.
Частым случаем использования критических секций на практике является обновление общих переменных. Например, если переменная SUM является общей и оператор вида SUM=SUM+Expr находится в параллельной секции программы, то при одновременном выполнении данного оператора несколькими нитями можно получить некорректный результат. Чтобы избежать такой ситуации можно воспользоваться механизмом критических секций или специально предусмотренной для таких случаев директивой ATOMIC:
!$OMP ATOMIC SUM=SUM+Expr .Данная директива относится к идущему непосредственно за ней оператору, гарантируя корректную работу с общей переменной, стоящей в левой части оператора присваивания.
Поскольку в современных параллельных вычислительных системах может использоваться сложная структура и иерархия памяти, пользователь должен иметь гарантии того, что в необходимые ему моменты времени каждая нить будет видеть единый согласованный образ памяти. Именно для этих целей и предназначена директива
!$OMP FLUSH [ список_переменных ].Выполнение данной директивы предполагает, что значения всех переменных, временно хранящиеся в регистрах, будут занесены в основную память, все изменения переменных, сделанные нитями во время их работы, станут видимы остальным нитям, если какая-то информация хранится в буферах вывода, то буферы будут сброшены и т.п. Поскольку выполнение данной директивы в полном объеме может повлечь значительных накладных расходов, а в данный момент нужна гарантия согласованного представления не всех, а лишь отдельных переменных, то эти переменные можно явно перечислить в директиве списком.
Мы не будем далее разбирать конструкции данной технологии, желающие найти полные тексты спецификаций OpenMP для языков Фортран, C и C++ могут обратиться к сайту http://www.openmp.org/.
Чем привлекательна технология OpenMP? Можно отметить несколько моментов, среди которых стоит особо подчеркнуть два. Во-первых, технология изначально спроектирована таким образом, чтобы пользователь мог работать с единым текстом для параллельной и последовательной программ. В самом деле, обычный компилятор на последовательной машине директивы OpenMP просто "не замечает", поскольку они расположены в комментариях. Единственным источником проблем могут стать переменные окружения и специальные функции, однако для них в спецификациях стандарта предусмотрены специальные "заглушки", гарантирующие корректную работу OpenMP-программы в последовательном случае - нужно только перекомпилировать программу и подключить другую библиотеку. Другим достоинством OpenMP является возможность постепенного, "инкрементного" распараллеливания программы. Взяв за основу последовательный код, пользователь шаг за шагом добавляет новые директивы, описывающие новые параллельные секции. Нет необходимости сразу писать параллельную программу, ее создание ведется последовательно, что упрощает и процесс программирования, и отладку.
 Содержание курса Содержание курса |
Следующая лекция. Система
параллельного программирования Linda. |
Лаборатория Параллельных Информационных Технологий, НИВЦ МГУ