|
|
|
Close Help | ||||||||||||||
|
|
|
Close Help | ||||||||||||||
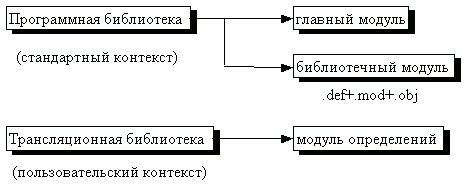
Разделяют логическую структуру и физическую структуру модуля.
[C]
В С можно выделить следующие типы модулей:
Инкапсуляция означает ограничение доступа данных.
Абстрактный тип данных (АТД) - это тип данных, в которых инкапсуляция максимальна. Поэтому абстрактный тип данных это только множество операций, определенных пользо-вате-лем. Любые языки, которые имеют операции над указателями, позволяют взламывать защиту.
[Модула-2]
Программа на Модуле-2 представляет собой:
|
+ |
|
Локальный модуль может быть внутри другого, но в Обероне Вирт отказался от локального модуля. Стандартная схема разделения определения, реализации и использования (РОРИ) задает схему программирования снизу вверх (Модула-2 заставляет писать в линеечку).
DEFINITION MODULE имя FROM имя_модуля IMPORT список_имен; список _объявлений; END имя.Можно импортировать все имена из модуля
IMPORT имя_модуля;но тогда все имена надо будет квалифицировать по полной программе: имя_модуля.имя.
IMPLEMENTATION MODULE имя; списки_импорта; объявления/определения; [BEGIN операторы ] END имя.
Тело может отсутствовать, а определения видны только внутри модуля.
[Pascal]
В Turbo Pascal модуль определений и реализаций слиты воедино в понятие Unit.
unit имя; interface ... implementation ... [begin операторы] end.
[Модула-2]
В Модула-2 есть понятие скрытого типа данных opaque. Если объявляется новый тип без указания базового, то считается закрытым.
TYPE имя;Работать с такими типами можно только через объявленные функции в модуле определений.
DEFINITION MODULE STACKS TYPE STACK; PROCEDURE INIT (VAR S : STACK); PROCEDURE PUSH (VAR S : STACK; X : INTEGER); PROCEDURE POP (VAR S : STACK) : INTEGER; END STACK. MODULE M IMPORT STACKS; VAR A : STACKS.STACK; BEGIN STACKS.INIT (A); STACKS.PUSH (A,1); ... END M.
Но из-за простоты скрытый тип данных становится ущербным, компилятор не может произвести распределения памяти, так как нет модуля реализаций. Следовательно, единствен-ная возможность: скрытым типом может быть только либо тип pointer, либо integer. Таким образом вся скрытость летит в полную горбатость. Теперь у программиста будет болеть голова: как же ему реализовать стек, чтобы элементы были либо pointer либо integer?
IMPLEMENTATION MODULE STACKS; ... TYPE StackRec = RECORD B : ARRAY [1..StackSize] OF INTEGER; TOP : [1..StackSize]; END; STACK = POINTER TO StackRec; END.
Но кто за нас проинициализирует TOP на единицу, отведет память под массив? Для этого необходимо по старинке вызывать функцию INIT. А кто проконтролирует нас, что мы проинициализируем STACK и отведем память, Таким образом простота приводит к концеп-туаль-ной бесполезности АТД в Модуле-2. Поэтому такой красивый язык не прижился, но профессор Вирт двинулся дальше и уже работал над Обероном.
[Оберон]
В Обероне программа представляет собой такой текст, который нельзя использовать сразу без некоторых инструментов. Вместо 4-х типов модулей в Обероне только 1 тип модуля.
MODULE имя; определения [BEGIN операторы] ENDДля того, чтобы экспортировать имя, надо при его определении ставить * после него
TYPE STACK* = RECORD B : ARRAY[1..StackSize] OF INTEGER; TOP : [1..StackSize]; END; PROCEDURE PUSH* (...); PROCEDURE POP* (...); PROCEDURE INIT* (...); ...
Чтобы вытащить интерфейс из такого модуля - запарился, поэтому в Обероне есть инструмент, который проходит по тексту и выделяет интерфейс в модуль определений, осуществляет проекцию. При этом те имена, после которых стоят *, сгруппируются в файл определений (интерфейса).
DEFINITION MODULE STACKS TYPE STACK = RECORD END;¬ PROCEDURE PUSH (...); ... END STACKS.Вот вам и закрытый тип данных, то есть с реализацией АТД проблем не будет. Мы можем контролировать доступ к переменным. При этом механизме
... = RECORD F1 : T1; F2*: T2; F3 : T3; END;спроецируется в
... = RECORD F2 : t2 END;
[Ада]
Модульная структура в Ada основана на понятии пакет, при этом используется принцип разделения определения и реализации.
Пакет®спецификация
®Тип пакета
package имя_пакета is объявления; ... ¬объявление [приватная часть] end имя_пакета; package body имя_пакета is объявления/расширения; [begin ¬реализация тела опрераторы] end имя_модуля.
Если убрать информацию о раздельной компиляции, то модули на Ada можно слить в один. Ada позволяет использовать вложенные пакеты.
package P1 is package body P1 is
... ...
package p2 is package body P2 is
... ® ...
end P2; end P2;
... ...
end P1; end P1;
Тела пакетов закрыты, поэтому можно экспортировать имена, описанные только в объяв-лении. Доступ к именам осуществляется путем квалификации имени через точку, но они потенциально видимы только после конца описания пакета. Вспомним, что Ada может переопределять (перекрывать) функции.
type T is ... function "+"(X,Y : T) return;
® ...
x,y : P.T;
z : P.T;
Но писать прямо z:=x+y; - нельзя, а надо: z:=P."+"(x,y);. Естественно, вся прелесть пере-крытия улетучивается, поэтому возникла необходимость другого механизма видимости имен. После спецификации нужно указать
use список_модулей;Таким образом после этой конструкции можно красиво писать z:=x+y;. Если два пакета P1 и P2 вложены и в P2 определен x, то после строк
use P1; use P2;имя x становится видимым.
В Turbo Pascal все модули равноправны, и если два имени объявлены в двух модулях, то оба имени становятся невидимыми (если нужен доступ, надо квалифицировать имена) и все становится просто. А в Ada из-за огромного нагромождения простых в принципе правил, да еще плюс иерархия какая-то, можно просто сломать ногу и проломить черепную коробку.
[Ада]
Для реализации АТД необходима инкапсуляция, сокрытие данных, для этого нужно воспользоваться механизмом приватной части
package Stacks is
type Stack is private;
procedure Push (S : inout Stack; X : in integer);
procedure Pop (S : inout Stack; X : out integer);
private:
type Stack is record
B : array [1..100] of integer;
T : integer range 1..100 := 1
end record;
end Stacks;
Здесь можно воспользоваться возможностью сделать начальное присваивание, мини-ини-ци-ализация.
[C++]
В С++ функции логического модуля выполняет класс, а концепция физического модуля (файл) в принципе отсутствует. Мы знаем, сто в С++ существует 3 уровня доступа к данным: public, protected и private. Для того, чтобы иметь доступ к закрытым полям данных существует механизм дружественного доступа. Класс может разрешить классу не наследнику или посторонней функции получить дос-туп к своим полям.
class X{
...
friend class Y
или
friend прототип_функции;
...
}
Но friend - это не "дырка" в концепции языка, потому что дети класса Y уже не смогут пользоваться полями X, только сам класс Y.
Различают следующие виды трансляции:
Следует понимать два контекста: стандартный (из встроенных таблиц) и пользовательский (из объявлений в программе).
В качестве абстракции выступает процедура или функция, а конкретизация означает - собственно вызов процедуры или функции. Связь между абстракцией и конкретизацией происходит статически, а виртуальные методы связываются динамически. Типы данных и объект связываются статически во всех языках, кроме Lisp и некоторых реализаций Basic. В объектном коде содержится необходимая информация об именах
имя | класс | размер | доступ
| |
данные/команды общий/закрытый
Связь производится компоновщиком (редактором связей) на последнем этапе, и все link-еры умеют работать только с этой моделью объектного кода (начиная с 50-х годов). Вот и мучаются программеры всего мира с именами своих объектов.
Из-за того, что в С подключаемый модуль может описывать
тип данных;
набор функций;
набор операций.
А включающий модуль содержит копии описаний типов и констант, то в С пролазит понятие структурной эквивалентности. Для удобства программирования на С впоследствии вынуждены были появится такие утилиты, как make и lint.
Зависимая компиляция подразумевает одностороннюю связь между модулями
Недостаток зависимой компиляции - это плохая поддержка программирования снизу вверх.
[Ada]
Для описания импортируемых имен нужно воспользоваться констукцией
with <список_имен>; [use <список_имен>;] ...
Это односторонняя связь: экспортер не знает ничего о клиентах, а импортер должен точно указывать своих экспортеров. Можно описать двустороннюю связь
package P is
...
end P;
...
package body P is
procedure T() is separate;
package P1 is separate
...
end P1;
...
end P;
Теперь где-нибудь потом можно написать тело пакета и функции
separate (P) procedure T is ... end T; separate (P) package body P1 is ... end P1;
Это позволяет программировать сверху вниз
В 1968 году статья Дейкстры всемирно обругала оператор goto. Дейкстра утверждал, что для структурного программирования нельзя использовать этот оператор, так как каждый элемент структурированной программы должен иметь строго один вход и строго один выход. При этом он говорил, что достаточно для программирования следующих конструкций
while E do s if e then s if e then s1 else s2 case repeat for
В 1974 году Кнут тоже в своей статье написал о goto и структурном программировании, причем он утверждал, что оператор goto можно использовать в структурном програм-ми-ро-вании, не нарушая семантики структурного значения, для обработки исключительных ситу-аций.
В традиционных языках мы встречали попытки модифицировать обычный оператор goto: break, continue, return. А профессор Вирт оказался круче - он попросту вообще отказался от оператора goto в языках Модула-2 и Оберон.
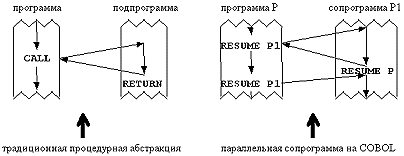
В Модуле-2 для обеспечения сопрограммной работы существует стандартная функция
TRANSFER (VAR P1, P2 : ADDRESS);где P1 и P2 - контексты процессов. Но чтобы создать контексты нужно использовать функцию
NEWPROCESS (P : PROCEDURE; VAR K : ADDRESS; N : CARDINAL);
При вызове процедур используют следующие способы передачи параметров:
В следующих языках для статической параметризации используют:
Ada - родовые сегменты;
С++ - шаблоны (типы и функции).
[Ada]
Рассмотрим родовые пакеты языка Ada, если у нас есть пакет Stack
package Stacks is
type Stack is record
body : array [1..100] of integer;
top : integer := 1;
end record;
... процедуры
end Stacks
то поменять тип стека параметрически нельзя. Раньше (в С) использовали
void * для хранения данных различных типов. Использовать макропроцессор
для параметризации типов не разумно из соображений эффективности.
Поэтому в Ada сделали некоторые допущения:
generic <параметры> <пакет> (спецификация) ... <тело_пакета>
Эта спецификация может быть определена и в отдельном модуле. Перепишем тело нашего пакета стеков
generic
type T is private;
StackSize : integer := 100;
package GStack is
type Stack is record
body : array [1..100] of T;
top : integer := StackSize;
end record;
... процедуры
end GStack
тогда работать с ним нужно так
with GStack; use GStack; package P is ... package IntStacks is new GStack (integer, 128); ...Таким образом мы объявили новый пакет - целые стеки, а переменная
v : IntStacks.GStackпеременная типа IntStack.
Напишем пример скалярного умножения массива
generic type T is digits <> з точность еще не определена function GScal (A, B : array (range <>) of T);но так нельзя, так как тип массива анонимный и фактический параметр не формализуются, поэтому надо
generic type T is digits <> type ArrT is array (range <>) of T; function GScal (A, B : ArrT) return T; ... type Float_Arr is array (range <>) of float; function FScal is new FScal (float, FloatArr); ...
Хотели один параметр - получили два!? Попытаемся еще обобщить для целых типов, булевских или других (Т - должен быть произвольным).
generic type T is private; type ArrT is array (range <>) T; with function "+"(A, B : T) return T is (<>); with function "*"(A, B : T) return T is (<>); with GScal (A, B : ArrT) return T; ... function FloatScal () is new GScal (float, FloatArr, "+", "*");компилятор из контекста догадается, что + и * - вещественные, так как мы указали is (<>).
Перечислим типы подходящие в качестве формальных
1. Общие
type T is private; type T is limited private; (если не надо производить операции + или *)
2. Вещественные type T is digits <>;
3. Регулярные type ArrT is array (range<>) of T;
4. Дискретные type DT is range <> of T;
5. Фиксированные type FT is delta T is range <>;
6. Параметр-процедура with function ... return ... [is(<>)]
7. Параметр-переменная имя тип;
Единственный способ передавать параметры-функции - это использовать родовую функцию, например, в задаче интегрирования разных функций.
Критические потребности подразумевают однородность родовых сегментов вплоть до раздельной компиляции (следствие: независимость компиляции определения от конкрети-зации), а также надежность (квазистатический контроль).
[C++]
Шаблоны придают программированию удобство, генерация будет зависеть от контекста конкретизации (естественно усложняется разработка компилятора). Страуструп начал работу над шаблонами в 1986 году, стандартная библиотека шаблонов появилась только через 10 лет, экспериментальная система появилась в 1990 году.
template <список_типовых_параметров> прототип_функции;
Например
template <class T> void Swap(T& a, T& b);
Скомпилировать полностью в данном случае нельзя, так как ничего не известно о типе Т. Поэтому проводят проверку статическую и динамическую, единственное требование - хотя бы один из параметров должен быть типа, указанного в списке типовых параметров. Все конкретизации шаблона имеют то же имя, компилятор различает из только по профилю параметров: swap (i,j); или swap <int> (i,j);.
С неявными преобразованиями вообще тяжело для полнопрофильных конкретизаций:
int i; char c; swap (i, c); ¬ так не пойдет, а надо: swap(i, c);
Так слово explicit перед конструктором X(int) указывает, что это не конструктор преоб-ра-зо-вания, а просто конструктор с параметром типа int. Проблемы возникают также и на курорте, если тело шаблона описано в подключаемом файле. Механизм Smart-компиляции предполагает дополнительную обработку объектного кода перед сборкой редактором связей.
template <список_типовых_параметров, параметры_константы> спецификация_класса;
Например
template <class T> class vector
{
T* body;
int size;
public:
Vector (int);
~Vector(int);
T& operator[](int);
T& elem(int);
}
vector <int> - конкретизация типа.
vector <int> v(10);
vector <int> a(25);
можно параметризовать и длину вектора
template <class vector T, int n> class vector T body[n]; int size; public: Vector (int); T& operator[](int); T& elem(int); } vector <int,25>a; vector <int,10> v;
Деструктор в принципе уже не нужен, так как вектор в массиве, но нужно генерировать для каждой конкретизации по 2 функции ([] и elem), потому что размер вектора определяется константой. Директива typename <имя> означает, что <имя> является именем неизвестного типа. Ее используют в шаблонах, когда Т еще не известен (причем тоже не известно, описан ли в нем Х).
typename T::X; T::X a;
Исключения - аварийная ситуация.
В Visual Basic : ON ситуация оператор
На исключительную ситуацию вешается обработчик, осуществляющий ремонт на месте. При возникновении ошибки мы не знаем, где она произошла. В Unix-е все системные вызовы возвращают целое значение, если оно меньше 0 - ошибочная ситуация, иначе - нормальная.
int имя_вызова (...);Например
if ((fd=open(...))<0)
{ обработка ошибочной ситуации }
else
{ нормальная ситуация }
Но этот метод плох тем, что логика аварийного кода не отделена от логики нормальной работы, текст программы увеличивается экспоненциальным образом. Можно использовать setjump(...) и longjump(...), но опять же пропадает структурированность обработчика, он вырождается в "пластырь".
Основные принципы обработки исключений в современных языках:
Проблемы при обработке исключений
[Ada]
exception - якобы тип данных.
Описание
имя_исключения : exception;
Существует зарезервированные идентификаторы исключений RANGE_EXCEPTION, ...
Оператор raise возбуждает исключение
raise имя_исключения;
После выполнения исключение распространяется. То есть, если в Р2 нет соответствующего обработчика, то исключение распространяется на Р1 и т.д. Вызов Р2 становится эквивалентным вызову raise. Если исключение не обрабатывается, то и в Р, то выдается посмертный дамп и адская программа завершается. Набор ловушек помещается в конце программного кода.
заголовок
объявления
begin
операторы when ex1|ex2|...|exn
exception операторы_обработки
набор_ловушек ¬------------ when others
end операторы_обработки
Этот принцип называется динамической ловушкой. В теле ловушки можно просто указать оператор raise, если обработчик до конца не справился с исключением, то, указав raise, мы распространим его не уровень выше.
[C++]
В языке С++ исключения сопоставлены типам, а в Java все исключения выходят из класса Troughable. Для снижения накладных расходов с С++ исключения могут возбуждаться только внутри блока try {...} набор_ловушек;
try
{ операторы; }
catch (тип) catch (тип имя) ¬ присутствует информация об объекте
{ блок_реакции } или { блок_реакции }
Блок
catch (...) {}
ловит все исключения. Оператор
throw выражение;является эквивалентом оператора raise. Тип выражения определяет возбуждаемое исключение.
throw 1; // исключение типа int throw "message";// исключения типа char*
Ловушки должны описываться только в блоке try, а не где-нибудь в другом месте. Если нет блока try и вызван throw, то это эквивалентно abort. Если нет соответствующей ловушки дл я данного исключения, то исключение распространяется выше, иначе считается, что исклю-чения обработано, и выполнение продолжается с точки, находящейся сразу за блоком try. если ловушка-обработчик сама не может справится с исключением, то нужно указать throw без параметров, и исключение распространится выше.
При возникновении исключения происходит свертка стека: стек не освобождается корректным образом от сломавшихся объектов, а перед этим вызываются их деструкторы. Можно использовать функцию set_terminate
typedef void(* PVF) (void); PVF set_terminate (PVF);для выдачи посмертного дампа. Можно указать шаблон ожидаемых исключений
прототип блок; прототип throw (список_имен_типов); блок
Если произойдет неожиданное исключение, то программу не имеет смысла продолжать, но можно что-то напоследок в назидание выдать
PVF set_unexpected (PVF);
[Java]
В Java, если функция возбуждает исключение, она должна предупредить об этом ком-пилятор
class C
{ ...
void f() throws (MyExc)
{ ... trow MyEsc(); ...}
}
Объекты объединяются в классы по однотипным характеристикам поведения. Классовое поведение не зависит от конкретного объекта. Объектные языки (Ada) обладают понятием объект (состояние, поведение). Язык С в грубом приближении тоже можно назвать объект-ным. Объектным языкам не хватает принципа уникальности типа объекта, что есть ООЯП, а также нет полиморфизма, когда объект реагирует по разному на одно и то же сообщение в зависимости от текущего типа объекта. ООЯП реализует все концепции традиционных языков, а к тому же концепцию разнотипных объектов (принадлежащих разным классам), полимор-физма, наследования, динамического связывания методов (виртуальные функции).
При наследовании наследуются свойства класса и могут добавляться новые.
[Оберон]
Расширение типа - наследование, динамическое связывание типов появилось только в Оберон-2. В Обероне расширяемым является только тип запись.
TYPE T = RECORD TYPE T1 = RECORD(T)
X : INTEGER; ® Z : INTEGER;
Y : REAL; ® END;
END; |
производный тип
Присваивание базовому типу производного корректно, обратное присваивание не позволяет определить поле Z. Аналогично присваивание указателей и ссылок, а следовательно, и параметры-переменные, проверяется на корректность.
Попробуем реализовать неоднородный контейнер, напишем разнородный стек.
Модуль определений, сгенерированный Обероном:
DEFINITION Stacks
TYPE
Stack = RECORD END;
PROCEDURE Open (VAR S : STACK);
PROCEDURE Push (VAR S : Stack; P : Node);
PROCEDURE Pop (VAR S : Stack; VAR P : Node);
...
END Stacks;
Модуль реализаций:
MODULE Stacks
TYPE
Node* = POINTER TO Node_Desc;
Stack* = RECORD N : Node END;
Node_Desc* = RECORD Next : Node END;
...
END Stacks;
Клиентский модуль
MODULE M;
IMPORT Stacks;
TYPE
T = RECORD (Stacks : Node_desc)
i : INTEGER;
END;
PT : POINTER TO T;
VAR
S : Stacks.Stack;
p : PT;
Stacks.Open (S);
p := NEW (PT);
p.i := 3;
Stacks.Push (S,P);
...
Но у Pop будут проблемы с идентификацией типа. Pop-ом надо доставать только базовый тип, а потом разбираться, что мы достали. Динамическая проверка типа производится с помощью стражей типа
P is PT
Результат логического типа, поэтому можно использовать его в условных конструкциях. Поэтому, если
W = RECORD (Stacks.Node_desc) Z : REAL; ENDТогда можно написать
IF P1 is PT THEN P1(PT).i = ... ELSIF P1 is PW THEN P1(PW).z := ... END;
Запись P1( T') означает, что надо трактовать тип P1 как T'. Можно провести групповую проверку типа, но проблема модификации кода из-за большого количества переключателей остается.
WITH P1 : PT DO P1.i := ... ... END;При анализе возможностей языка удобно разобрать модель графического редактора.
TYPE
Figure = POINTER TO Figure_Desc;
Figure_desc = RECORD
Next : Figure;
X, Y : INTEGER;
END;
...
В другом модуле можно написать
TYPE
Line = PONTER TO Line_Desc;
Line_Desc = RECORD (Figure_Desc)
X2, Y2 : INTEGER;
END;
Rect = POINTER TO RectDesc;
Rect_Desc = RECORD (Figure_Desc)
H, W : INTEGER;
END;
...
Процедура отрисовки
PROCEDURE DrawLine (R : Line); PROCEDURE DrawRect (R : Rect); PROCEDURE Draw... ( ... ); ...Процедура отрисовки всех объектов
PROCEDURE DrawAll;
VAR P : Figure;
BEGIN
P := List;
WHILE P#NIL DO
IF P is Line THEN
DrawLine (P(Line))
ELSEIF P is Rect THEN
DrawRect (P(Rect))
ELSEIF
...
END;
P := P.Next
END
END;
Наследование дает возможность выводить новые фигуры и с небольшими изменениями кода выполнять их отрисовку. Но нет перекрытия имен и из-за сложной модифицируемости программы (куча переключателей) все преимущества теряются. Оберон кроме защищенности не дает ничего нового по сравнению с С. В отчаянной попытке исправить положение Н. Вирт предложил концепцию обработчиков.
TYPE
DrawProc = PROCEDURE (P.Figure);
MoveProc = PROCEDURE (P.Figure : Figure; DX, DY : INTEGER);
...
Figure_Desc = RECORD
Next : Figure;
X, Y : INTEGER;
Draw : DrawProc;
Move : MoveProc;
END;
PROCEDURE DrawLine (P : FIGURE)
...
BEGIN
WITH P.Line DO Я аналогично и в DrawRect
...
END
END DrawLine ;
Тогда отрисовка всех фигур станет приятней
PROCEDURE DrawAll;
BEGIN
P := List;
WHILE P#NIL DO
P.Draw (P);
P := P.Next;
END
END DrawAll;
В данном случае DrawAll не надо переписывать при добавлении новой фигуры. Таким образом вручную моделируется полиморфизм, что опять же небезопасно - тот ли указатель передаем, правильно ли проинициализирован обработчик?
[C++]
Если класс X наследует класс Y, память будет распределена линейным образом
Присваивание сыну отца запрещено в целях надежности и логичности, причем проверяется корректность и для указателей и ссылок. Конструкторы и деструкторы не наследуются авто-матически по концепции языка (а члены-функции наследуются). При наследовании, в отличие от Оберона, можно переопределять поля (данные и методы), при этом с помщью квалифи-ка-ции можно обращаться к исходным полям в классе предке. В С++ применимо множественное наследование
class T : public T1; public T2
{ ... };
При этом классы Т1 и Т2 должны быть не родственными, проблемы возникают, когда необходим доступ к полям предков.
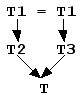
Чтобы объект Т1 не дублировался в памяти, нужно использовать ключевое слово virtual.
class T2 : virtual public T1; class T3 : virtual public T1; class T : public T2, public T3;
В стандарте С++ ничего не упоминается, какую модель памяти должен использовать компилятор. Но линейная схема, по словам Страуструпа, не так уж плоха для С++ и вполне эффективна, только пришлось немного уточнить некоторые моменты. Проблема возникает при множественном наследовании. Метод языка SmallTalk, использующий цепную модель, не совсем эффективен по скорости, но эффективно использует память. Пример:
a) X ® Y
X& x=y; // тут всё понятно
б) X,Y ® Z
Y& y=z; // а тут начинается мухлёж
Компилятор должен преобразовать адреса, в данном случае это произойдёт статически на этапе компиляции. Но если модель наследования более сложна:
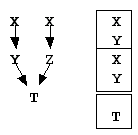 - память используется не эффективно
- память используется не эффективно
Поэтому для предотвращения дублирования объектов в памяти используют виртуальное наследование:
class Y : public virtual X{..};
class Z : public virtual X{..};
class T : public Y, public Z{..};
В данном случае получится, что объект класса X не будет дублироваться, даже если написать:
class T : public virtual X, public Y, public X
{..};
Во всех современных языках наследование идёт монотонно, то есть при наследовании не происходить сужение свойств объекта класса.
[Java]
Java - чисто объектно-ориентированный язык, поэтому все классы выводятся из корневого класса Object. Понятие логический модуль представлено классами и пакетами, а физический модуль - пакетами
package имя1.имя2. ... ---- имена полные import класс/интерфейс ---- в качестве имён можно использовать сетевые адреса.
В программе должна быть функция main, аналогичная функции main из C++.
class C1
{
public static int main (String[] arg)
}
Количество элементов не надо указывать, так как у массива есть атрибут - длина.
arg.length
Глобальных функций нет, есть только статический эквивалент глобальных. Как и в C++ есть 3 вида доступа к данным:
public - аналогично C++, доступны всюду, где доступен класс;
protected - в функциях-членах производных классов;
private - только в функциях-членах данного класса.
Если употребляется ключевое слово final, то это означает, что у данного класса не может быть наследников. Таким образом получается, что:
final int i=3фактически определяет константу. Введение слова final вызвано проблемами надёжности, эффективности и прагматичности (не надо динамически искать метод объекта).
Кстати об исключениях,
finally {..};
эквивалентно
catch(...) { .. };
в С++, то есть перехватывает все остальные исключения.
Понятие деструктор в полной своей мере отсутствует. Так как удалением объектов управляет сборщик мусора, поэтому метод finalize (); вызывается не тогда когда мы предполагаем. Можно в самом методе указать для вызова метода базового класса слово super:
super.finalize();
В данном случае слово super эквивалентно слову inherited в Borland Pascal. Если мы имеем:
int[] a1;
int[] ia2;
ia1 = new int[15]; // только теперь объект
// массив существует
ia2 = ia1; // массив не копируется, только ссылки
ia1 = null; // ссылка ia1 заглушается
ia2 = new int[5]; // первый массив повисает
Теперь надо ждать, когда сборщик мусора найдёт потерянный массив и вызовет метод finalize(), если он у нас есть.
При присваивании
ia1 = ia2;происходит копирование ссылочное, поверхностное, поэтому нужно перекрыть оператор "=". Аналогично, для глубокого сравнения объектов нужно переопределить метод equals.
В базовом классе Object все функции-члены открыты, так как из него выходят все остальные классы. Функция
public int hashCode ();вырабатывает число для своего объекта, что облегчает и стандартизирует работу с хеш таблицами.
С помощью
public final class setClass ();можно динамически определять тип объекта. Имеется возможность произвести клонирование объекта, то есть произвести глубокую копию:
protected Object clone ();
Объект может запретить клонировать себя, указав, что clone возбуждает исключение CloneNotSupportedException
class X
{ ...
Object clone() throws CloneNotSupportedException {
CloneNotSupportedException;
}
...
}
В Java существует понятие интерфейс, интерфейсы не содержат тел объектов
interface имя
{ список_описаний;
список_прототипов_функций;
}
class NEWCLASS extends OLDCLASS implements
список_интерфейсов;
Это удобно для обеспечения множественного наследования. Класс, который наследует интерфейсы, но не все из них реализованы, считается абстрактным. Специальное слово abstract указывает на это. Если мы создадим свой класс "множество", то клиенты не должны беспокоиться о внутренней реализации представления самого множества.
class MySet extends Slist implements Set
{
список_функций;
}
...
interface Set
{ ... }
[Оберон-2]
В Оберон-2 Н. Вирт добавил механизм динамического связывания типов, чем вывел свой язык в ранг объектно-ориентированных.
TYPE FIGURE=POINTER TO FIGURE_DESC;
FIGURE_DESC = RECORD NEXT:FIGURE END;
TYPE LINE = POINTER TO LINE_DESC;
LINE_DESC = RECORD (FIGURE_DESC)
X1,Y1,X2,Y2 : INTEGER
END;
...
PROCEDURE (P:FIGURE) Draw();
PROCEDURE (P:FIGURE) Move(DX, DY : INTEGER);
...
DEFINITION
TYPE FIGURE_DESC = RECORD
NEXT : FIGURE;
PROCEDURE Draw();
PROCEDURE Move(DX, DY : INTEGER);
END;
Вот и попался профессор Вирт, он сам ругал описания классов в С++ и SmallTalk, а здесь мы видим, что вместе с полями описываются свои методы объекта. И указываемый параметр Р в описании базовых функциях Draw и Move есть не что иное как параметр this, который в С++ передаётся автоматически по умолчанию. Тогда соответственно функция отрисовки всех объектов будет безопасна и изящна
PROCEDURE DRAWALL
VAR P : FIGURE;
BEGIN
P := LIST;
WHILE P#NIL DO
P.Draw ();
P = P.NEXT
END;
END DRAWALL;
Её тело не надо перекомпилировать при изменении типов объектов. Не смотря на то что базовые функции Draw и Move абстрактны, тела их надо описать (по семантике).
PROCEDURE (P:FIGURE) Draw() BEGIN ERROR() END;
[С++]
Если объявлены 2 класса:
class X
{ virtual int f(); };
class Y
{ virtual int f(); };
то при выполнении следующего фрагмента будет подразумеваться, что
X::f() Y::f() X *px; | | Y *py; Ї Ї px = py; px->f(); py->f();А если:
Y::f()
class X Ї
{ virtual int f(); };
class Y
{ virtual int f(int); }; // oops!
то компилятор обижается и запрещает статическое перекрывание.
Напомним, что виртуальными могут быть только функции-члены. В С++ функции не могут менять свою виртуальность случайно. Удачное толкование для термина overriding - перео-пре-де-ление - "подмена" функционального свойства. Если нет виртуальных методов в классе, то размещение в памяти будет идентично структурам (линейная). Поэтому
class Complex
{
double Re, Im;
double Abs();
...
};
эквивалентно по присваиванию полей структуре
struct Complex
{
double Re, Im;
};
Это обстоятельство удобно для совместимости с программами на С.
Вспомним о статическом перекрытии имён.
class Y:X
{
int g();
virtual int g(double);
...
}
py->g(); py->g(int);
Компилятор по профилю параметров определит какая функция должна вызываться. Подводный камень проявляется, если в классе X функция g определена как
virtual int g(int);Тогда при исполнении
px = py; px->g(10);произойдёт неявное преобразование типов, что нам совсем не требуется. Единственное, что сделано для безопасности, так это то, что перекрываемые функции должны возвращать значения одинакового типа.
Если имеется критический класс, от которого зависят все классы проектов, то, чтобы не производить перекомпиляцию всего проекта при изменении критического класса, надо объявить все функции-члены виртуальными в этом классе.
class Struct
{
virtual op1();
virtual op2();
...
virtual ~Struct(); // виртуальный деструктор
virtual *clone();
};
а в другом классе Struct_Impl файла struct_impl.cpp
class Struct_Impl : Struct
{
op1() {...};
op2() {...};
...
struct *clone() {...};
};
Таким образом виртуальными функциями мы описали чистый интерфейс с
объектом. Для создания объекта конструкция struct x; не пройдёт, нужно
создавать объект в дина-ми-че-ской памяти. Для этого мы описали метод
clone();, который будет создавать объект
Struct *px = Struct::clone();Для удаления объекта нужно вызвать деструктор
delete pxЕсли он не описан как виртуальный, то не произойдёт глубокого удаления. Подобъекты, на которые ссылается этот объект, не будут удалены, что не нужно, так как при этом останется мусор в динамической памяти.
Чем мы платим? В памяти появляется таблица виртуальных методов ТВМ. Если архитектура не оптимизирована для косвенных вызовов, то на каждый вызов виртуального метода тратится на 6-8 инструкций больше. Виртуальный метод в общем случае по своей природе не может быть inline типа, кроме того случая, когда метод не наследуется и не перекрывается. Но по памяти накладные расходы для каждого объекта минимальны, в начало добавляется ссылка на свою ТВМ.
Допустим мы имеем следующее
class X
{ ТВМ X
virtual f();
virtual g();
};
class Y:X
{
f();
virtual h();
};
class Z:Y
{
g();
h();
virtual y();
}
Хотя ТВМ создаётся для каждого класса, но для всех объектов этого
класса она одна общая. В простейшем случае ТВМ состоит из указателей на
тела методов. В нашем случае получится следующее
| ТВМ X | ТВМ Y | ТВМ Z | |||||||||
|
|
|
Можно отметить, что все указатели на виртуальные методы ТВМ упорядочены, имеют одинаковое смещение от начала. Таким образом удобно производить обращение к ТВМ.
px = py; px -> f();Загрузчик лезет в Y и вызывает Y::f(), но вызов px->h() - забракуется компилятором статически на стадии компиляции, так как в классе X не объявлена функция h().
Проблема заключается в том, что в ТВМ надо поместить указатель на тело метода, вспомним наш класс Struct. А если функция виртуальная, то на что должен указывать указатель? Писать пустые NULL заглушки бессмысленно, так как вызов их ошибочен по сути потому, что должны вызываться-то методы класса реализаций. Поэтому нужно использовать абстрактный метод.
virtual op1()=0; - pure function
Так называемая "чистая" виртуальная функция. При этом в ТВМ помещается не NULL, а в действительности указатель на диагностирующую функцию времени выполнения. Так как абстрактную функцию могут нечаянно вызвать через прямое обращение к базовому классу. Абстрактный класс нельзя явным образом инициализировать, только через указатель.
К недостаткам нужно отнести то факт, что при большом количестве типов много места занимают множественные ТВМ объёмного содержания (например, 144 обработчика сооб-щений в системе Windows).
[Java]
В С++ понятие абстрактного класса размыто, так как он, класс, может содержать, как мы уже видели, поля и методы (например, конструкторы). А в Java в принципе нельзя вызвать абст-рак-тный метод - для защиты перед словом class ставиться слово abstract. В Java запрещено множественное наследование объектов, только иерархическое. Но интерфейсы могут иметь несколько предков, так как они абстрактны и ничего не реализуют. Например
// класс наследует С и реализует интерфейсы class C1 extends C implements I1, I2, ... , IN // интерфейс наследует интерфейсы interface I extends I1, I2, ... , IN
[С++]
Поговорим о множественном наследовании, почему Страуструпу пришлось его реализовать в языке С++, а в других языках его фактически нет? Не столько проблемы по размещению в памяти, линейное размещение прекрасно нас удовлетворяет, сколько другие проблемы, связанные с эффективностью исполнения. Если у нас
class X
{ ... }
class Y
{ virtual f();
virtual g();
}
class Z: X, Y
{ virtual f(); }
Начало X совпадает с началом Z, а начало Y не совпадает. Следовательно, нужно динамически модифицировать адрес, добавлять смещение. А с виртуальными функциями еще деликатней.
Z* pz; ... pz -> f(); // ® Z::f(); pz -> g(); // ® Y::f();Каждой из этих функций передается указатель this, для функции f он правильный, а для g - не правильный. Его необходимо сдвинуть на Y, иначе он затрет X. А если
Y* py; py -> f(); py -> g();
Указатель py может указывать и на объект Z, что тогда делать - приходиться еще одну ТВМ.
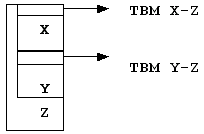
|
|
Эти ТВМ отличаются от ранее рассмотренных тем, что в них, кроме адреса, еще заносится дельта для указателей this.
Причина появления множественного наследования объясняется возникшей проблемой транзита информации от корня к листьям. Стремление сделать базовый класс наиболее универ-сальным делает его очень раздутым, и все это растет от отца к потомкам. Для эффек-тивного программирования принято, что множественно наследуются интерфейсы, а классы насле-дуют-ся единичным наследованием.
[С++]
В Обероне мы использовали стражи типа для определения текущего типа, но большие программы из-за большого количества переключателей программы неудобочитаемы. В С++ стандартными приемами можно также реализовать динамическое определение типа объекта.
enum ClasID { CLASS1, CLASS2, ... }
...
class Base
{ virtual ClassID getClassID()=0;
...
}
Нужно в классах-наследниках переопределить метод getClassID(), который будет выдавать соответствующее значение ClassID. На первый взгляд это надежно, но стоит ошибиться в реализации метода getClassID, и компилятор не сможет проконтролировать.
If (p->getCkassID()==CLASS2)
{ class2* p1 = (class2 *) p;
...
}
Это очень похоже на обероновских стражей типа. Паскалевский typeof(e1) выдает только ссылку на ТВМ. Но if typeof(e1)=typeof(e2) работает эффективно, так как у е1 и е2 либо разные, либо одинаковые ТВМ соответственно. Поэтому можно просто добавить ссылку на свойства объекта, это можно сделать, подключив typeinfo.h.
class type_info
{ const char* name;
bool operator==(const type_info&);
bool operator!=(const type_info&);
before (const type_info&)
...
};
Для безопасного преобразования p1¬p2 нужно проверить, совпадает ли p2 с p1 или наследует ли p2 p1? Можно использовать следующие механизмы С++ (стандарт).
Общий синтаксис:
кл_слово <T> (e);
Безопасное преобразование:
dynamic_cast <T> (e); // безопасное динамическое преобразование
Если T<e , то dynamic_cast возвратит ссылку на преобразованный к типу T объект e, иначе возвратит NULL.
static_cast <T> (e); // небезопасное статическое преобразование
Эквивалентно обычному статическому преобразованию (T)e.
reinterpret_cast <T> (e);
Преобразование в не совместимый тип: литры - в килограммы. Вся ответственность по последствиям на программисте. Но ведь когда мы распечатываем значение указателя, мы же переводим его в целый, так что это не просто желание внести ненадежность в язык.
[Java]
В отличие от С++, в Java есть стандартная функция getClass, позволяющая получить полную информацию о классе. В Java компоновка является частью процесса выполнения программы, поэтому в байт-коде JIT-компилятору передается вся информация об объектах.
Так как Java - чисто объектно-ориентированный язык, все методы динамические по природе (по жизни), поэтому понятно для чего есть слово final.
final class C
{ void f() {...};
...
};
C x; x.f();
- тут сразу понятно, что имеется в виду только C::f(), так как метод f()
никем не может быть наследован. Поэтому, если у вас классный
JIT-компилятор, то он может в данном случае существенно увеличить
скорость выполнения байт-кода, иногда даже дело доходит до
inline-подстановки.
[SmallTalk]
Как и в языке Java в SmallTalk имеется главный класс - Object, из него выводятся все остальные классы. В SmallTalk реализована не линейная модель распределения памяти под объекты.

Так как язык чисто объектно-ориентированный, то все методы виртуальные (динамиче-ские). ТВМ немного отличается от ранее рассмотренных тем, что в ней не указывается имя класса, в котором реализовано тело метода, а указан профиль его параметров.
| Имя f | Профиль параметров . . . |
Пусть объекту Z посылается сообщение, которое должен обработать метод f. Если в ТВМ Z имеется строка о методе f и профиль параметров соответствует вызову, то метод Z::f вызывается. Иначе происходит поиск подходящего описания в ТВМ по иерархии до базового супер-класса Object, если поиск безуспешен, то динамически выдается сообщение об ошибке. Причем, если в Java компилятор может статически определить правильность профиля парамет-ров вызова, то SmallTalk это может сделать только динамически, пройдя до суперкласса, таким образом на вызов метода тратится много временных ресурсов.
Такой ультрадинамизм позволяет программе динамически во время выполнения производить подмену обработчика. В Java можно менять реализации интерфейсов, но все равно они заранее статически определены, и при загрузки новой реализации JIT-компилятор сможет проверить профили параметров во всех вызовах.
Следовательно, основные недостатки SmallTalk:
Но благодаря своей гибкости этот язык быстро распространился в научной среде.
[Java]
При создании нового экземпляра класса нужно использовать оператор new. Но для интер-фейсов подобную операцию делать не нужно, так как new выводит новый объект, а интерфейс один на весь класс. Все данные если и есть в интерфейсе являются по умолчанию final static, и, следовательно, могут существовать вне зависимости от существования объектов реализации, чего мы, в принципе, от них и ожидаем.
interface Colors
{ int blue = 1;
int red = 4;
int f();
}
class X implements Colors
{...}
X x; Colors i;
i = x // теперь можно писать i.red
i.f() // вызовется X::f()
Мы знаем, что все параметры в Java передаются по значению, поэтому для реализации, например, функции swap придется воспользоваться классами-оболочками!? Известно, что в С++: С тебе - отдельно, и ++ - отдельно. А в Java имеются как бы интегрированные пакеты, например, пакет java.lang, соответственно, и интегрированные классы. Так для числовых типов имеем:
int ® Int, long ® Long, double ® Double, ... и так далее.
void Swap (Long a, Long b) {...};
У классов-оболочек есть конструкторы преобразования, которые преобразуют a и b в класс Long и мы можем уже менять значение по ссылке. В Java нельзя перекрывать операции "+" и "=", но класс string свою операцию "+". Класс string содержит метод tostring, поэтому следующая запись имеет право на существование
x = y + " " + z;
Она эквивалентна
x = y.tostring + " " + z.tostring;
[Ada95]
Ада исповедует концепцию уникальности типа, поэтому перед создателями Ada95 стояла задача сохранить совместимость со старыми программами и добавить концепцию ООП. В можно программировать, придерживаясь нескольких парадигм. При помощи нового служеб-ного слова tagged можно указывать компилятору, что данный объект тэгированный, то есть у него есть некоторая дополнительная запись. Так
type Point is tagged ¬ такая запись может быть расширена
record
X, Y : integer;
end record;
type Rect is new Point with
record
W, H : integer;
end record;
Но Point и Rect несовместимы по присваиванию по концепции уникальности типа. Для реализации ООП пришлось ввести понятие расширенный класс - ClassWide. Тогда получаем, что Rect принадлежит расширенному классу Point'Class, а для процедур с обобщенными пара-метрами ослабляется запрет несовместимости типов. Если
procedure P (X:in Point'Class); ... begin Draw(X); ... end;то произойдет динамическое связывание метода.
procedure Draw (A:in Point'Class);
В С++ и Java существует 3 уровня доступа, в Ada - только 2, на уровне пакетов. Для расширения пакета, наследования его, необходим доступ к его полям, клиентского взаимо-действия не достаточно. Для это введено понятие дочерние пакеты
package P.P1 is type T1 is new T with private; ... private ... end P1;
Дочерний пакет при компиляции вставляется внутрь базового пакета, поэтому ему доступ-ны все поля базового пакета.