|
|
|
Close Help | ||||||||||||||
|
|
|
Close Help | ||||||||||||||
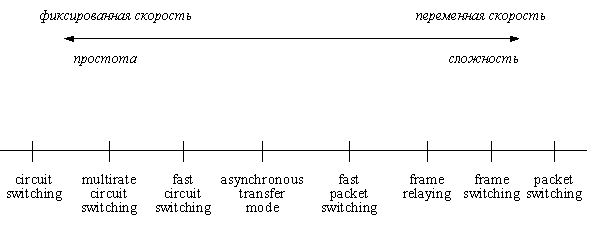
Рис.1. Спектр технологий коммутации
На рис.1 представлен спектр технологий коммутации. Из него видно, что режимы передачи, располагающиеся в центре оси, являются наиболее оптимальными в смысле сложности реализации и возможности работы с переменными скоростями, т.е. представляют "золотую середину". Системы быстрой коммутации пакетов охватывают несколько альтернатив, все они представляют пакетную коммутацию с минимальным набором функций, реализуемых сетью. Наиболее известной сегодня разновидностью является АТМ - асинхронный режим передачи. Акроним "асинхронный" означает, что реализуется асинхронное взаимодействие между тактовой частотой передатчика и приемника. Разница между этими частотами сглаживается за счет вставки\удаления пустых\неассоциированных пакетов в информационный поток, т.е. пакетов, не содержащих полезной информации.
Главное достоинство режимов, расположенных в середине оси, в том, что они предоставляют возможность передачи любых видов служб независимо от того, какую скорость они требуют, требований качества и импульсивности трафика.
Действительно, режим коммутации каналов приспособлен для работы на постоянной скорости передачи (имеется в виду, конечно, цифровая передача), и не допускается никаких всплесков нагрузки. Если же пользователь все же генерирует в какой-то момент более интенсивный поток данных, то он все равно при входе в систему будет ограничен скоростью работы системы, естественно, с потерей качества. С другой стороны, система пакетной коммутации очень хорошо может работать с переменной скоростью передачи, не ограничивая в принципе абонента по скорости (за исключением того, что поток от абонента физически не может пройти по имеющимся каналам из-за ограниченной пропускной способности линий связи), однако, механизмы реализации этого режима слишком сложны и технология коммутации такова, что не все виды сервиса можно с ее помощью обслужить, поскольку задержка передачи данных произвольная, чего нельзя допускать при передаче некоторых типов сигналов, например, видеосигнала. Как можно заключить из рис.1 технология АТМ вобрала в себя достоинства систем, расположенных на обоих краях оси, правда, не избежала и некоторых присущих им обоим недостатков. Например, статистическое уплотнение соединений в линии выполняется менее эффективно, чем в системе классической пакетной коммутации. Это выражается в том, что если абонент заказал пропускную способность для своего соединения, но фактически ею не пользуется, то она не может быть предоставлена под вновь устанавливаемое соединение - система считает, что абонент может начать ее использовать в любой момент, и, поэтому, не может установить еще одно соединение под уже заказанные, но неиспользуемые ресурсы. В этом есть нечто от системы коммутации каналов. Правда, в отличие от последней, неиспользуемые в описываемом случае ресурсы системы могут отводиться под уже установленные соединения, чего нет в коммутации каналов. Однако преимущества системы АТМ, выражающиеся в способности передавать трафик любого типа с гарантированным качеством, перевешивают некоторые недостатки. Эти преимущества были главными для МККТТ, чтобы определить АТМ как режим передачи будущих широкополосных сетей. Внедрение технологии АТМ позволит добиться следующих преимуществ.
Итак, перечислив главные достоинства универсальной сети, перейдем непосредственно к рассмотрению основ построения АТМ.
В случае, если на какой-либо линии между узлами или между пользователем и сетью возникают ошибки, или линия временно перегружена, что вызывает отбрасывание пакетов, в узле не предпринимается никаких действий для исправления возникающих сбоев (например, запросов на повторные передачи ошибочных пакетов). Процедуры защиты от ошибок на канале можно убрать из-за того, что каналы в сети очень высокого качества. По этой причине невозможно использовать в сети АТМ аналоговые каналы, поскольку на них никогда нельзя добиться такого низкого уровня ошибок, при котором из сети можно было бы выкинуть эти функции. Приемлемым для АТМ является канал, уровень ошибок на котором не выше 10-8. Что касается ошибок, вызванных потерей данных в узлах коммутации, то вероятность таких событий удерживается на допустимом уровне за счет очень точного резервирования ресурсов системы под каждый абонентский поток. Системы управления потоком также не реализуются. Разумеется, необходимо как-то распределять ресурсы между пользователями, и в данном случае это делается с помощью анализа количества незанятой пропускной способности каналов и последующем статистическом прогнозе о длине очередей пакетов на доступ к каналу. Эти вероятные размеры очередей не должны будут выйти за пределы имеющейся у узла памяти. Все это позволяет обеспечивать заданную частость переполнений памяти, вызывающих потери пакетов. В результате вполне достижимой оказывается величина вероятности потери пакета на уровне 10-8-10-12.
Уже говорилось, что ошибки при передаче и при переполнении памяти приводят к потерям различного рода - простые поражения битов данных, потери пакетов и вставки пакетов. Поражения единичных битов связаны, как правило, с шумами в канале и с рассинхронизацией. В сетях коммутации каналов не предпринимается никаких действий внутри сети для исправления таких ошибок, тогда как в классической пакетной коммутации вводится механизм повторных передач. В системе АТМ как и в телефонной сети все проблемы по устранению подобных ошибок перекладываются на плечи абонента, т.е. на протокол из конца в конец.
Ошибки типа вставки и потери пакетов связаны с ошибками, наложившимися на заголовок данных, что типично для всех пакетных сетей. В сети АТМ предпринимаются некоторые действия по исправлению подобных ошибок, но делается это по совершенно другому принципу, чем в обычных пакетных сетях. Так, если в пакетных сетях все это можно исправить с помощью повторной передачи недоставленных пакетов, то в сети АТМ этого делать уже нельзя, поскольку каждый переспрос данных вызовет большую задержку передачи, которая в общем случае недопустима. Поэтому вводится система кодирования с исправлением ошибок, но только по отношению к заголовку пакетов. Восстановление потерянных вследствие переполнений памяти пакетов здесь не производится, но зато реализуются некоторые превентивные действия по минимизации самой возможности такого переполнения, основаннные на том, что на этапе установления соединения проверяется, имеется ли в наличии достаточное количество ресурсов сети. Конечно, невозможно заранее предсказать, какой интенсивности поток будет исходить от абонента в течение всего времени соединения, и, поэтому, потери пакетов достаточно типичны для сетей АТМ в силу того, что у сети нет средств по управлению абонентским потоком, однако величину этих потерь удается удерживать в допустимых пределах за счет того, что система работает по принципу ориентации на соединения (connection-oriented). Это значит, что перед началом обмена данными проводится этап установления соединения, в котором можно оговорить допустимые параметры трафика. Управление абонентским потоком реализовать достаточно сложно, поскольку это требует оперативного обмена служебной информацией непосредственно во время передачи данных и обработка этой информации будет требовать времени и вносить задержку. Хотя, в форматах пакетов АТМ, которые мы будем рассматривать ниже, предусмотрена возможность для вставки в них такой служебной информации, но сама процедура пока не реализована.
Перед тем, как начать передачу данных, выполняется фаза установления соединения, во время которой в сети отводятся под это соединение определенные ресурсы. Если необходимых ресурсов в системе нет, соединение получает отказ. По этой причине вероятность переполнения памяти в узле, а значит, вероятность потерь пакетов, удерживается на очень низком уровне - 10-8-10-12. По окончании соединения ресурсы возвращаются в систему. Это позволяет системе гарантировать минимальный уровень потерь пакетов и, соответственно, максимальное качество. При этом под соединение отводится не жесткое значение пропускной способности, а статистические значения, т.е. среднее и максимальное значение потока. Поэтому вероятность переполнения памяти все-таки присутствует.
Уже говорилось, что размер поля данных в пакетах АТМ должен быть достаточно маленьким. Однако, необходимо было определить, какой именно. Прежде всего дебаты разгорелись вокруг вопроса, делать ли пакет переменной или постоянной длины. Первым предложением было сделать пакеты фиксированной длины размером всего 16 байт. На самом деле как у переменной, так и у постоянной длины есть свои выгоды и недостатки. При этом исходили из оценки эффективности использования канала, затрат на коммутацию, сложности реализации и задержки.
Ясно, что с точки зрения использования канала переменная длина пакета предпочтительнее, поскольку если сообщение короткое или его длина не кратна фиксированному размеру пакета, то потребуется дополнять последний пакет до полного объема, на что уходит пропускная способность. Кроме того, при постоянной длине пакета придется вводить дополнительные функции в заголовок данных для того, чтобы определять, где именно в составе пакета кончаются пользовательские данные и начинаются биты заполнения (впрочем, это можно делать и на более высоком уровне).
С другой стороны, чем длиннее сообщение, тем это преимущество переменной длины менее заметно, поскольку доля вносимой избыточности становится малой по сравнению с пользовательскими данными - ведь дополнять объем поля данных до фиксированного размера придется только последнему пакету. Если же пакет переменной длины, то все равно придется вносить особые функции в заголовок с целью определения границ пакета наподобие того, как это делается в процедуре HDLC. Тем более, что все равно нужно как-то ограничивать максимальную длину - нельзя же допускать размер пакета, исчисляемый килобайтами!
В целом можно сказать, что с точки зрения эффективности использования канала переменная длина пакета выгоднее, чем постоянная, правда, очень незначительно.
Что касается затрат на коммутацию, и сложности реализации, то на это влияют два основных фактора: скорость обработки данных и требования по размеру памяти.
Скорость обработки зависит от объема операций и времени, отводимой на это. Одной из важных функций системы АТМ является обработка заголовка. Предположим, что заголовок обрабатывается независимо от того, используется ли переменная или постоянная длина пакета. Для того, чтобы работать в реальном времени, необходимо успеть обработать заголовок пакета за время приема следующего пакета. Если система рассчитана на работу со скоростью 150 Мбит/сек, то при длине пакета 53 байта это время составит 2.8 мксек. Если же представить себе систему с переменной длиной пакета, то ориентироваться по скорости обработки нужно на наихудший случай, т.е. когда пакет имеет минимальную длину, например, 10 байт. В этом случае при той же скорости заголовок должен быть полностью обработан за 533 наносекунды, т.е. требования по быстродействию значительно ужесточаются.
Что касается требований по управлению памятью, то в случае фиксированной длины пакета резервировать память гораздо проще. В случае переменной длины, резервировать память пришлось бы в расчете на максимальную длину, что менее производительно и экономно, или же динамически резервировать память побайтно, что значительно сложнее.
В отношении задержки можно сказать, что она напрямую зависит от длины пакета, и эта длина не может быть очень большой, поскольку в противном случае задержки передачи возрастают. Действительно, когда поток битов от пользователя поступает в сеть, то при формировании пакета первый бит должен ждать, пока придет последний, и только когда объем накопленной информации будет достаточным для заполнения пакета, он будет отправлен в канал. Следовательно, чем больше пакет, тем дольше будет информация ожидать в передатчике момента начала передачи. Поэтому при больших длинах пакетов становится проблематичной передача видео и голоса. Поэтому, даже, если и делать пакеты переменной длины, она сможет варьироваться в очень узких пределах.
Таким образом, преимущества переменной длины пакета над постоянной ничтожны, и в результате МККТТ остановился на принятии пакетов фиксированной длины. Ввиду этого возникла необходимость называть этот блок данных по-другому, поскольку существующее слово "пакет" означает блок данных произвольной длины. Остановились на слове "cell" , что в дословном переводе означает "ячейка".
Когда МККТТ выбирал конкретное значение длины селла, то при этом принималась во внимание использование канала, задержка передачи и сложность реализации. С точки зрения использования канала лучше сделать селл побольше, т.к. при этом доля служебной информации - заголовки - уменьшается, однако, чем больше длина селла, тем больше задержка в сети. Далее, чем больше длина селла, тем больше времени у системы на обработку заголовка, что упрощает построение коммутатора, но при этом ему требуется большая память, которая чем больше, тем медленнее. Все дебаты по выбору длины селла вращались вокруг диапазона между 32 и 64 байтами.
На задержку коммутации влияет во многом соотношение между длиной заголовка и длиной поля данных. Эта зависимость представлена на рис.2. Расчеты производились исходя из скорости каналов в 150 Мбит/сек. По оси абсцисс отложено отношение длины поля данных к длине заголовка. Попробуем физически объяснить поведение этих графиков.
При росте длины поля L увеличивается время обслуживания селлов в очереди, т.е. увеличивается задержка. Это происходит потому, что требуется больше времени для считывания данных из очереди и записи в нее. С другой стороны, при очень маленьких значениях L время обработки увеличивается из-за того, что селлов становится очень много, и объем заголовка относительно возрастает, следовательно, возрастает и время обслуживания, поскольку нужно изучить много таких заголовков.
В результате долгих дебатов, когда обсуждалось два предложения - сделать поле данных селла 32 или 64 байта, было принято решение выбрать середину - 48 байт, на которые накладываются еще пять байт заголовка - итого 53 байта.
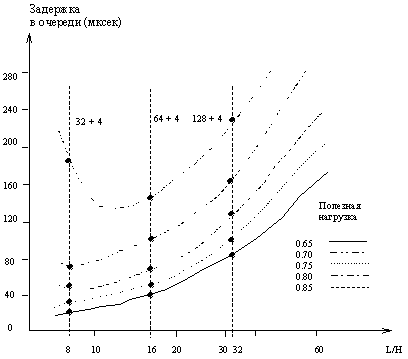
Рис. 2. Зависимость задержки в очереди от соотношения длин поля данных и заголовка пакета при различных значениях нагрузки
Уже говорилось, что основной характеристикой АТМ является ограничение функций системы по обработке заголовка. Основой этого является то, что АТМ - это принципиально система, ориентированная на предварительное установление соединения - как и Х.25. Значит, не нужно в каждом селле анализировать адреса абонентов. Каждое соединение, как и в Х.25 идентифицируется уникальным номером. В системе отсутствует защита от ошибок, которая вынесена на процедуру из конца в конец и реализуется в рамках пользовательской службы (если это требуется). Отсутствует также механизм управления потоком. Таким образом, основной функцией заголовка остается только анализ идентификатора виртуального соединения и маршрутизация в соответствии с ним. Для этой цели имеется два раздельных идентификатора - идентификатор виртуального канала (virtual channel identifier - VCI) и идентификатор виртуального пути (virtual path identifier - VPI). При этом VCI определяет динамически создаваемые соединения, а VPI - статически создаваемые. Под идентификатор VCI в формате заголовка отводится 16 бит. Присвоение VCI выполняется на этапе установления соединения, и этот номер, так же, как и логические каналы в системе Х.25, меняются от участка к участку. Может показаться странным: зачем вводить два разных идентификатора для одного и того же соединения. Дело в том, что при проектировании технологии АТМ предполагалось, что в рамках одного сеанса связи можно делать несколько различных соединений. Например, при телевещании по одному VCI можно передавать видеосигнал, а по другому - звук. Можно привести еще множество примеров такого рода. Кроме того, при необходимости можно в рамках одного сеанса устанавливать новые соединения, например, если два абонента во время разговора хотят обменяться факсами или файлами данных. Таким образом, в рамках абонентского соединения можно оперативно создавать и убирать виртуальные каналы, т.е. регулировать пропускную способность. Поэтому VC являются динамическими. Впрочем, процедура динамического создания VC в рамках соединения до сих пор не описана с точки зрения управления. Пока это только теоретическая возможность. Более того, существующие сегодня узлы коммутации устанавливают все свои соединения только по единственному виртуальному пути - VPI=0. Это значит, что фактически для идентификации соединений используется только один идентификатор - номер виртуального канала. Это значит, что между парой абонентов, конечно, можно установить более одного соединения, но с точки зрения сети это будут совершенно не связанные друг с другом соединения. Другими словами, современные узлы коммутации являются коммутаторами VC, а не VP.
На рис. 4 приведен самый общий пример установления виртуального пути между пользователем А и пользователем С, в рамках которого организуется 2 индивидуальных соединения, каждый со своим номером VC. Из рисунка видно, что номер пути и номер канала меняется от участка к участку (как логические каналы в Х.25). Итак, пользователи А и В соединены каналами 1, 2 и 3, а пользователи А и С - каналами 3 и 4. Заметим, что канал №3 присутствует в двух виртуальных путях, однако они не путаются т.к. они относятся к разным виртуальным путям. При едином для всех номере виртуального пути номера виртуальных каналов не могли бы совпадать. Под идентификатор виртуального пути в заголовке селла отводится от 8 до 12 бит, что позволяет создавать на участке до 256 или до 4096 путей, каждый из которых "набирается" из виртуальных каналов.
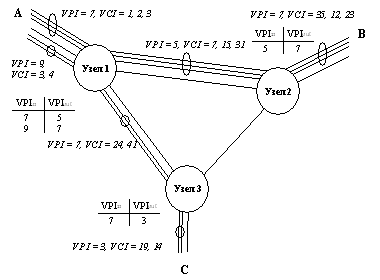
Рис. 4. Понятие VPI в сети АТМ
Еще одной функцией заголовка является разделение логических соединений по приоритетам. Приоритет означает, что на некоторые селлы допускается большая вероятность потери, чем на остальные. Приоритеты могут задаваться на виртуальный канал, или же на каждый селл в отдельности.
Ясно, что отсутствие приоритетов гарантирует лучшее разделение ресурсов, чем приоритетная система, но не позволяет делать различия между службами с разной чувствительностью к прозрачности сети.
Для функций эксплуатации сети и мониторинга соединений используются несколько дополнительных бит заголовка. Естественно, встает вопрос о разделении информационных селлов и селлов управления. Делается это с помощью специальных битов заголовка, называющихся "идентификатор типа поля данных" - Payload Type Identifier - PTI. С его помощью в абонентский поток данных можно вставлять селлы управления, которые обрабатываются сетью как обычные, но они содержат служебную информацию - например, такой служебный селл может добавляться пользовательской службой на передаче и содержать в себе проверочную последовательность для контроля ошибок предшествующих селлов. Кроме того, они могут содержать всякого рода тестовую информацию.
В любой пакетной системе приемник должен иметь возможность определять границы пакета. Например, в системе HDLC, где разрешается прохождение кадров переменной длины, границы кадра задаются с помощью флагов. Для гарантирования того, чтобы не произошло ложное обнаружение границ, вводится процедура бит-стаффинга. Такую же систему можно было бы включить и в сеть АТМ, но на высоких скоростях процедура бит-стаффинга нежелательна. Однако, ввиду постоянства длины селлов, возможны другие механизмы определения границ. Было предложено несколько вариантов такого алгоритма; мы рассмотрим тот, который был принят МККТТ.
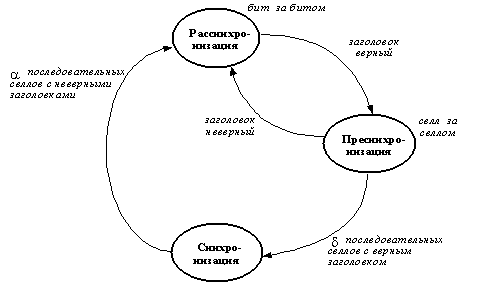
Рис. 5. Диаграмма состояний для определения границ селла
На рис. 5 представлена диаграмма состояний приемника в смысле выявления границ селла. Устройство может находиться в одном из трех состояний - синхронизм, предсинхронизм и рассинхронизм. В состоянии рассинхронизма система находится в первоначальный момент времени, когда процесс синхронизации еще не начался, и тогда, когда синхронизм потерян. В этом состоянии приемник просматривает канал на предмет обнаружения правильного селла. Когда он обнаружен, система переходит в состояние предсинхронизма и находится в нем до тех пор, пока не будет выявлено определенное количество правильно принятых подряд селлов, после чего считается, что синхронизм установлен. Переход в состояние рассинхронизма из синхронного состояния происходит в момент, когда границу селла не удалось выявить несколько раз подряд, после чего процесс начинается заново. Как же происходит выявление границы селла? Этот процесс основан на том, что в составе заголовка каждого селла присутствует проверочный байт, с помощью которого осуществляется защита от ошибок бит заголовка, о чем уже говорилось выше. В состоянии рассинхронизма система просматривает входной поток бит за битом, байт за байтом до тех пор, пока не будет обнаружено совпадение проверочной последовательности. Дело в том, что заголовок селла состоит из пяти байт, последний из которых содержит проверочную последовательность. Приемник, записав четыре байта, на основании следующего - пятого оценивает, соответствует ли последовательность в этом пятом байте значению предыдущих четырех. Если соответствует, то это значит, что скорее всего это и есть заголовок селла, т.к. пятый бит является линейной комбинацией первых четырех. В этот момент приемник входит в состояние предсинхронизма. Поскольку известна длина каждого селла - 53 байта, то система отсчитает еще 48 байт и после этого вновь примется анализировать соответствие четырех последующих байт пятому и т.д. Когда такая ситуация произойдет n раз подряд, будет принято решение о том, что синхронизм достигнут и система перейдет в соответствующее состояние. Выход из синхронного состояния происходит в случае, если m раз подряд значение заголовка селла не совпадет со значением проверочного полинома.
Вследствие злонамеренных или непреднамеренных действий может получиться так, что поле информации в селле точно повторяет корректный заголовок, из-за чего период вхождения в синхронизм может сильно увеличиться. Для того, чтобы защититься от этого, в систему на передаче добавляется скремблер, который преобразует информацию пользователя к виду, близкому к псевдослучайной последовательности, т.е. убирает статистическую зависимость бит данных друг от друга.
Таким образом, мы видим, что прямая связь между передатчиком и приемником в смысле синхронности отсутствует - приемник настраивается по входному полезному сигналу. Это значит, что не требуется передача специального синхросигнала от источника до получателя. Этим и объясняется термин "асинхронный" в названии режима передачи.
Разумеется, система не может работать так, чтобы заставлять пользователя все время посылать какую-то информацию. Передатчик всегда имеет возможность остановиться, если передавать больше нечего. Не произойдет ли выход из синхронизма, если нет данных для передачи? Не произойдет, причем за счет того, что передатчик всегда заполняет паузы абонентского трафика специальными "пустыми" селлами, не содержащими полезной информации, но также состоящими из 53 байт с корректным заголовком. Конечно, в поле PTI, о котором недавно говорилось, будет указано на то, что этот селл "пустой" и его не нужно отправлять приемнику.
В начале нашего курса говорилось о том, что модель ВОС очень удачна и широко используется для моделирования всех видов коммуникационных систем. МККТТ в рекомендации I.321 описал логическую иерархию широкополосной системы АТМ, однако в ней приведено только описание нижних уровней. Полностью соответствие АТМ и модели ВОС еще не приведено, поэтому придется ограничиться неофициальным взглядом на это.
Модель предполагает использование концепции нескольких плоскостей для разделения пользовательских функций, функций управления и контроля. Структура такой плоскостной модели приведена на рис. 6 и содержит эти три плоскости: пользовательскую - для передачи абонентской информации, плоскость контроля - для передачи информации сигнализации и плоскость управления - для системы эксплуатации сети и реализации операторских функций. Кроме того добавлено третье измерение в структуре, называемое управлением плоскостями, которое отвечает за управление системой в целом. Впрочем, поскольку технология АТМ находится еще в стадии становления, очень много функций управления до сих пор не стандартизированы.
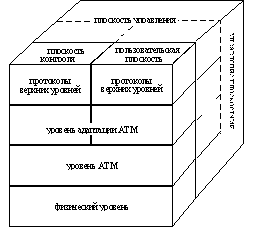
Рис. 6. Модель стека протоколов в сети АТМ
Как видно из рисунка, каждая плоскость охватывает несколько уровней модели, причем уровни, как и положено, функционируют независимо друг от друга и общаются между собой стандартными протокольными блоками. Взаимосвязь уровней АТМ и уровней модели ВОС пока не описано в МККТТ, но можно умозрительно установить такую взаимосвязь: физический уровень более или менее совпадает по функциям с первым уровнем модели ВОС и занимается обработкой потока бит. Уровень АТМ располагается в нижней части второго уровня стандартной модели. Уровень адаптации АТМ - АТМ adaptation layer - AAL - выполняет задачи приспособления протоколов верхних уровней, неважно, пользовательской или сигнальной информации, к селлам АТМ фиксированной длины. Для плоскости контроля информация сигнализации эквивалентна нижней части второго уровня ВОС, а пользовательская плоскость больше приложима к нижней части транспортного уровня, поскольку адаптация пользовательских данных выполняется из конца в конец между абонентскими установками. Функции системы можно разделить между уровнями АТМ так, как представлено на рис. 7. Физический уровень отвечает за передачу бит/селлов, уровень АТМ занимается коммутацией и маршрутизацией, а также мультиплексированием информации AAL (ATM adaptation layer), который в свою очередь отвечает за привязку пользовательских данных к потоку селлов, причем эта привязка для различных типов служб может делаться по-разному.
Эти три уровня в свою очередь делятся на подуровни, каждый из которых также реализует свои функции.
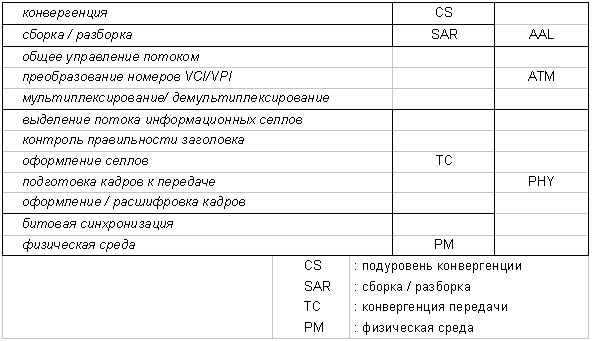
Рис. 7. Схема функций различных подуровней модели
Физический уровень состоит из подуровня физической среды и подуровня конвергенции, т.е. "подтягивания" вида передаваемых данных к виду, удобному для передачи по каналам. Подуровень физической среды отвечает за корректную передачу и прием битов по каналу. Иначе говоря, с его помощью осуществляется ввод потока данных в канал связи. Кроме того, этот уровень выполняет битовую синхронизацию на канале (отметим, что битовая синхронизация на канале никак не связана с синхронизацией селлов, о которой говорилось выше - селл может быть выдан в канал в произвольный момент времени, т.е. битовая синхронизация присутствует в любой системе, а кадровая синхронизация может отсутствовать).
Подуровень конвергенции в первую очередь выполняет адаптацию к системе передачи, например, это может быть система 8В/10В или SONET. Это значит, что этот подуровень выполняет функции формирования той информационной структуры, которая соответствует системе передачи. Например, здесь осуществляется вкладывание потока селлов в кадры SONET или 8В/10 и формирование самих этих кадров. На приеме производится изъятие селлов из кадров и кроме того, на этом подуровне осуществляется помехозащита заголовка селлов, соответственно, на нем лежит и функция селловой синхронизации, поскольку, как уже говорилось, она неотделима от системы кодирования заголовка. Помимо синхронизации, здесь также выполняются все функции, связанные с обработкой ошибок в заголовке. Все это означает, что здесь выполняются некоторые функции по формированию селлов - добавление в заголовок проверочного байта.
Раз здесь реализуется синхронизация селлов, то здесь же должен выполняться механизм вставки и изъятия "пустых" селлов, которые, как уже говорилось, нужны для того, чтобы не образовывалось пауз в потоке.
Работа уровня АТМ полностью независима от работы физического уровня, который выдает селлы, проверенные по заголовкам и готовые к маршрутизации. Соответственно, основными функциями уровня АТМ является мультиплексирование потока селлов из разных виртуальных путей в один канал для передачи, необходимые преобразования заголовков, например, переназначение номера виртуального пути при переходе с участка на участок, также выполняются некоторые функции управления на основании поля PTI в заголовке селла, а также формирование и изъятие заголовка.
Уровень AAL обеспечивает связку сервиса, поставляемого уровнем АТМ с пользовательскими уровнями. На нем лежит реализация функций пользовательской плоскости, плоскости контроля и управления. Поскольку системой могут пользоваться различные службы, то и вариантов реализации уровня AAL также несколько, и они зависят от потребностей служб.
В целом уровень AAL разделяется на два подуровня - подуровень сборки/разборки селлов и подуровень конвергенции ("подтягивания"). Функции подуровня сборки/разборки достаточно прозрачны и состоят в "нарезке" входной информации на части, годные для вставления в селл и обратное преобразование на приеме. Подуровень конвергенции выполняет функции идентификации сообщений, синхронизации абонентских установок (если соответствующая служба этого требует) и т.д. В тех случаях, когда условия работы сети АТМ пользователя устраивают, т.е. не требуется синхронизации абонентских установок и параметры качества сети (задержки и уровень ошибок) пользователя устраивает, этот подуровень может быть пропущен. В настоящее время организациями по стандартизации определено пять способов реализации уровня AAL, каждый из которых предназначен для поддержки своего типа службы. Об этом будет подробно рассказано при рассмотрении сетевого уровня.
На рис.8 представлена структура формата селла АТМ на стыке "пользователь-сеть". Внутрисетевой формат селла показан на рис.9. Как видим, в обоих случаях размер селла остается постоянным - 53 байта, а размер заголовка 5 байт. Различие только в том, что внутри сети в формате отсутствует поле GFC - общее управление потоком. За счет него увеличивается размер поля VPI - вместо 8 байт оно становится равным 12 байт.
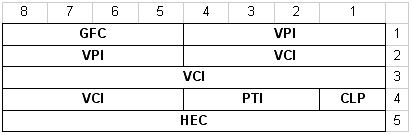
Рис. 8. Структура селла АТМ на входе в сеть. GFC - обобщенное управление потоком;
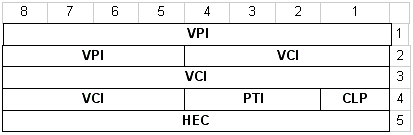
Рис. 9. Структура заголовка селла АТМ на интерфейсе NNI
Поле данных селла, составляющее 48 байт, заполняется на уровне АТМ информацией верхних уровней и в процессе передачи данных никак не анализируется и не изменяется сетью. Заметим, что речь в этом смысле идет только о селлах, содержащих пользовательские данные. Когда идет процесс управления соединением или передача другой служебной информации, например, обмен маршрутными таблицами между узлами, конечно, содержимое селла анализируется, но это уже служебные данные. Уровень АТМ создает заголовок к каждому селлу и добавляет его к пользовательской информации. Соответственно, на приеме заголовок анализируется и отбрасывается. Между селлами в канале нет никаких промежутков или разделительных бит - они следуют друг за другом сплошным потоком.
Поле данных пользователя никак не участвует в работе сети и сейчас нам не интересно.
Поле GFC - общее управление потоком занимает первые 4 бита в первом байте заголовка и предусмотрено для управления потоком на участке между пользователем и сетью. На сегодня его функции спецификациями не определены. В будущем с его помощью планируется более тщательно, чем сегодня управлять потоком данных. Так, сейчас у сети нет никаких способов воздействия на абонента в случаях, когда он работает не по правилам, т.е. нарушает соглашения, установленные в процессе установления соединения. Единственное, что может делать сеть (и она это делает), это отбрасывать селлы в случае, когда скорость передачи данных не соответствует условленной. Напомним, что такое превышение будет чревато для сети тем, что память узлов будет переполняться, что вызовет рост задержек передачи других потоков, а сеть им уже дала свои обязательства по качеству обслуживания.
Когда функция управления потоком будет реализована, то сеть сможет притормаживать абонента с тем, чтобы, хоть и с некоторой задержкой, но передать пользовательские данные, и с тем, чтобы указать абоненту на его неправомочные действия.
В предыдущем подразделе мы уже касались назначения полей идентификаторов виртуального пути и виртуального канала.
На стыке с сетью согласно форматам можно установить не более 256 виртуальных путей, каждый из которых может содержать до 65536 виртуальных каналов, что в сумме дает более 16 миллионов соединений. Напомним, что пока работа ведется только по одному виртуальному пути, и, поэтому, число возможных соединений ограничено 65536 соединениями. Внутри сети на каждом межузловом участке может одновременно проходить до 4095 виртуальных путей. Такое расширение может быть нужно, поскольку по одному каналу могут проходить соединения от очень многих абонентов, и 16 миллионов номеров может не хватить. Дело в том, что АТМ планируется как универсальная международная сеть, через которую будет передаваться весь мировой информационный обмен и необходимо заранее предусмотреть резервы. Так, сегодня через международные каналы России проходят многие десятки тысяч разговоров одновременно и это число растет. Поэтому, на этих каналах необходимо будет использовать эту расширенную нумерацию.
Что касается виртуальных каналов, то почти все они используются именно для абонентской передачи за исключением первых 32, которые зарезервированы под передачу сигналов управления различного рода. Каждый вид сигналов управления согласно различным спецификациям должен проходить по строго определенному виртуальному каналу. Назначение некоторых из них показано на рис.10.
С нулевым номером VP и VC проходят так называемые "пустые" селлы. Их назначение в том, чтобы заполнить пропуски в абонентском потоке. Выше говорилось о том, что для целей синхронизации селлы в канале обязательно должны идти подряд без пропусков - иначе собьется механизм определения границ селлов. Но поскольку невозможно заставить абонента на 100% загрузить канал, то оставшиеся проценты загрузки будут заняты этими пустыми селлами, формат которых точно такой же, как и у информационных. Раз их назначение только в заполнении пауз, после прохода через канал они будут уничтожены сразу после приема и никак не повлияют на производительность узла, который таким образом работает только с нужными селлами.
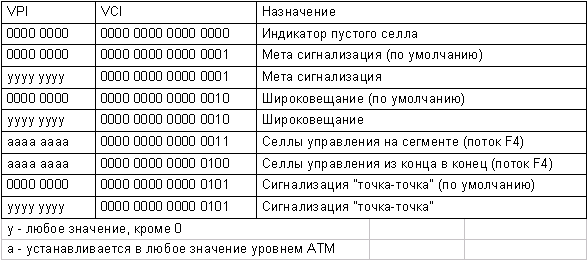
Рис. 10. Зарезервированные номера VPI/VCI
Каналы метасигнализации имеют функцию, связанную с настройкой других каналов сигнализации. В самом деле, далеко не всегда нужно использовать все сигнальные потоки, предусмотренные рекомендацией. Поэтому заранее нельзя сказать, нужно будет их устанавливать или нет. А раз их можно не устанавливать, то они не могут быть образованы автоматически при включении устройства, тем более, что никогда заранее нельзя предсказать, через канал какой пропускной способности они будут проходить. Для того, чтобы можно было установить служебные соединения, служит канал метасигнализации, требующий очень мало пропускной способности, и работающий очень короткое время.
Канал широковещания используется для передачи пользовательских селлов, которые должны быть доставлены всем абонентам на данном интерфейсе.
Для целей управления отдельными соединениями и отдельными виртуальными путями служат два потока сигнализации - поток F4 и поток F5. Поскольку они задают сигнализацию, распространяющуюся только на один путь или канал, то они имеют тот же самый номер пути или канала.
Уже говорилось о том, что поле данных пользователя никак не анализируется сетью. Однако, управляющие данные необходимо анализировать. Следовательно возникает вопрос: каким же образом сеть может определить, нужно ей осматривать содержимое селла или нет? Можно, конечно, попытаться всю управляющую информацию вкладывать в специально отведенные для этого виртуальные каналы, которых мы уже коснулись, но в некоторых случаях это неудобно, и, поэтому, приходится вставлять служебные селлы непосредственно в тот же канал, что и абонентские данные. Для отделения этих служебных данных от абонентских в рамках одного и того же виртуального канала служит поле PTI - Payload Type Identifier. Это поле имеет длину 3 бита. Структура его кодирования приведена на рис.11.
Как видно из рисунка, на сегодня используется только 6 типов кодов для поля данных селла и из этих шести четыре связаны с различными типами селлов, содержащих пользовательские данные. Они разделяются по признаку наличия или отсутствия перегрузки, а также по признаку, является ли данный селл конечным в передаваемом сообщении, или содержит продолжение сообщения. Разумеется, признак продолжения или конца сообщения может быть известен только уровню адаптации. Когда селл передается с уровня AAL на уровень АТМ первый указывает на этот признак. В случае, если селл является продолжением сообщения, то в протокольном блоке, который проходит между уровнями в передающем устройстве, указывается признак "type 0". Селл, заканчивающий сообщение содержит признак "type 1", и этот признак type будет включен в состав заголовка селла на уровне АТМ. Таким образом, в составе поля данных этот признак не передается.

Рис. 11. Кодирование поля PTI
На приемной стороне поле данных пользователя оформляется в протокольный блок, который выдается на уровень AAL, и в составе этого протокольного блока будет содержаться соответствующая метка type 0 или type 1. Заметим, что признака "начала сообщения" нет. Этот признак используется только при работе с уровнем адаптации типа AAL 5. Все другие уровни адаптации всегда указывают данные как тип 0.
Помимо признака начала и конца сообщения в составе поля PTI передается также признак уведомления о перегрузке. Этот признак предназначен приемнику и проставляется не источником информации, т.е. не передающим АТМ-уровнем, а тем узлом сети, который отметил у себя наличие перегрузки. Когда приемник получит селл с этим признаком, он в принципе может начать у себя процедуру управления потоком с целью заставить передатчик снизить интенсивность потока данных. Однако, этот механизм, во-первых, никак не может быть подвластен сети, а, во-вторых, он еще не стандартизирован. При этом нет никакой информации о том, где именно на сети произошла перегрузка.
Следующие два значения поля PTI относятся к служебным селлам управления. Ранее уже говорилось, что вся сигнализация и управление проходят по отдельным виртуальным каналам, а здесь этот признак вставляется в состав селлов в рамках того же виртуального канала, что и данные пользователя. Дело в том, что есть один вид управления, который относится к внутриканальной сигнализации, т.е. сигнализации между узлами коммутации и связан с управлением только данным конкретным соединением, поэтому он был включен с состав пользовательского канала. Одно значение поля PTI указывает на управление только между двумя соседними узлами, а другое - из конца в конец. Все это также будет подробно рассмотрено ниже.
Еще один бит в заголовке указывает на приоритет селла. Если приоритет указан низким, т.е. если этот бит установлен в 1, то это значит, что в случае каких-либо перегрузок в узлах такой селл будет отброшен в первую очередь. При этом возможны два варианта - приоритет своему соединению и, соответственно, всем его селлам назначает пользователь, а второй вариант - сеть сама изменяет приоритет селлам внутри сети. Конечно, нас заинтересует только второй вариант.
Предположим, что некий абонент не совсем правильно выдерживает установленные ранее параметры трафика, т.е. работает с большей скоростью, чем это предполагалось. Сеть это сразу заметит и тем селлам, которые поступили в узел через слишком маленький интервал времени после предыдущего селла (т.е. их частота больше согласованной), снизит приоритет. В принципе, это еще не значит, что такие селлы будут обязательно в сети уничтожены. Если у узла несмотря на превышение согласованной интенсивности имеется достаточно ресурсов, чтобы обслужить такой поток, то этот селл будет передан дальше, хотя и с пониженным приоритетом. Отбрасывание селла произойдет только в том случае, если возникает угроза тому, что сеть не сможет выполнить взятые на себя обязательства - доставлять информацию со строго определенной задержкой. Это может произойти не обязательно в том же узле, который изменил селлу приоритет.
Таким образом, потери данных в сети могут происходить даже, если никаких помех в канале не было. С помощью этого бита в сети реализуется защита от перегрузок.
Последний, пятый байт заголовка селла содержит проверочную последовательность, с помощью которой защищается от ошибок предыдущие 4 байта заголовка. При этом используется код с исправлением ошибок, благодаря чему удается защититься от ошибок, связанных с неправильной маршрутизацией селлов - ведь если поражен заголовок, то скорее всего исказился номер виртуального канала, и селл будет доставлен не по адресу.
Кроме защиты от ошибок с помощью этого байта выполняется процедура выявления границ селлов, как это было описано выше.
Итак, мы видим, что функции обработки заголовков селлов в сети очень ограничены и по сути состоят только в коммутации на основании установленных маршрутов и в контроле за соблюдением установленных параметров соединения. Эту работу можно выполнить очень быстро, и, поэтому, система АТМ может работать на очень высоких скоростях. В принципе, конечно, можно изобрести такие вычислительные системы, которые смогли бы с такой же скоростью обрабатывать и пакеты TCP/IP или Х.25, однако, это не смогло бы заменить технологию АТМ, поскольку никогда нельзя было бы гарантировать постоянство времени передачи данных через сеть, хотя вероятность потерь данных и необнаруженных ошибок была бы весьма низкой. Впрочем, даже в рамках описанной технологии вероятность потерь данных удается удерживать на уровне 10-8, что вполне достаточно для большинства приложений. Могут быть системы, где даже такая вероятность ошибок недопустима, например, в военной области, телемедицине или системе управления космическими объектами, но там придется вводить дополнительную защиту от ошибок уже на пользовательском уровне.