|
|
|
Close Help | ||||||||||||||
|
|
|
Close Help | ||||||||||||||
По своей значимости для развития и распространения реляционного подхода к управлению базами данных СУБД Ingres (Interactive Graphics and Retrieval System) находится близко к System R, хотя история и организация этой системы во многом отличается от System R. Для начала коротко рассмотрим историю Ingres.
Проект и экспериментальный вариант СУБД Ingres были разработаны в университете Беркли под руководством одного из наиболее известных в мире ученых и специалистов в области баз данных Майкла Стоунбрейкера (Michael Stonebraker). С самого начала СУБД Ingres разрабатывалась как мобильная система, функционирующая в среде ОС UNIX. Первая версия Ingres была рассчитана на 16-разрядные компьютеры и работала главным образом на машинах серии PDP. Это была первая СУБД, распространяемая бесплатно для использования в университетах. Впоследствии группа Стоунбрейкера перенесла Ingres в среду ОС UNIX BSD, которая также была разработана в университете Беркли. Семейство СУБД Ingres из университета Беркли принято называть "университетской Ingres".
В начале 80-х была образована компания RTI (Relational Technology Inc.) для доведения университетских прототипов до уровня коммерческих продуктов. С этого момента стали различать университетскую и коммерческую СУБД Ingres. В настоящее время коммерческая Ingres поддерживается, развивается и продается компанией Computer Associates. Сейчас это одна из развитых коммерческих реляционных СУБД.
Хотя во многих отношениях коммерческие варианты Ingres являются более развитыми, чем университетские, в учебных целях гораздо интереснее говорить про университетские разработки. Во-первых, как в случае любого коммерческого продукта, информация о внутренней организации коммерческой Ingres в основном носит закрытый характер. В то же время, по поводу университетской Ingres имеется много высококачественных публикаций. Во-вторых, университетскую Ingres можно опробовать на практике и даже посмотреть ее исходные тексты. Наконец, в-третьих, именно в университетской Ingres были опробованы многие оригинальные идеи, используемые в настоящее время во многих других системах. С использованием этой системы в университете Беркли (и других университетах) проводились многие учебные и исследовательские работы.
Поэтому в данной лекции мы будем рассматривать организацию университетской версии СУБД Ingres, которая тесно связана с особенностями языка QUEL (в такой же степени, в какой System R тесно связана с особенностями языка SQL). Далее, говоря о СУБД Ingres, мы будем в этой лекции иметь в виду университетскую Ingres.
СУБД Ingres проектировалась в расчете на использование в среде ОС UNIX. Эта система играла роль своего рода виртуальной машины. Ориентация на использование UNIX наложила существенный отпечаток на общую организацию Ingres, на статическую и динамическую структуру СУБД.
Прежде всего, все базы данных, обслуживаемые СУБД Ingres на данном UNIX-компьютере, хранятся в одном поддереве файловой системы. Каждой базе данных соответствует отдельный справочник, каждое отношение базы данных (включая служебные отношения) хранится в отдельном файле ОС UNIX. Защита программных компонентов системы от несанкционированного выполнения и баз данных от несанкционированного доступа основывается главным образом на общем механизме защиты файлов ОС UNIX. При установке СУБД Ingres автоматически заводится специальный "пользователь" ОС UNIX с именем Ingres, от имени которого работают все системные процессы Ingres, и только ему разрешается запускать эти системные процессы и обращаться к файлам баз данных. Более точное управление доступом берет на себя Ingres.
Существуют две возможности вызова Ingres - в интерактивном режиме командой языка Shell или из прикладной программы, написанной на языке EQUEL и преобразованной прекомпилятором языка EQUEL к программе на языке Си. В первом случае создается следующая структура процессов:
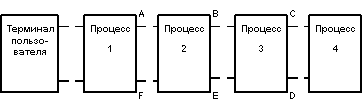
Во втором случае структура процессов выглядит следующим образом:
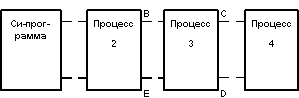
Процесс 1 - это интерактивный терминальный монитор, позволяющий пользователю формулировать, редактировать и выполнять наборы команд Ingres (операторов языка QUEL).
В процессе 2 выполняется лексический и синтаксический анализ операторов QUEL, модификация операторов с целью обеспечения целостности баз данных, контроля доступа, подстановки представлений, а также синхронизация параллельного доступа к базе данных.
Процесс 3 является ответственным за выполнение операторов выборки, занесения и удаления кортежей. В нем выполняется оптимизация запросов на основе техники декомпозиции сложных запросов. Кроме того, для операторов модификации кортежей производится предварительная выборка модифицируемых кортежей и подготовка их новых образов для реального выполнения модификации в процессе 4.
Наконец, в процессе 4 выполняются так называемые команды-утилиты - создания и уничтожения отношений, индексов и т.д., а также упомянутая отложенная модификация кортежей.
Процессы связаны программными каналами (pipes) ОС UNIX. Прямая информация при обработке операторов передается по каналам A, B и C. Результаты, включая сообщения об ошибках, передаются по обратным каналам D, E и F. Процессы работают строго синхронно: после посылки прямого сообщения каждый процесс дожидается получения ответного сообщения, а после посылки ответного сообщения - ждет получения очередного прямого.
Как видно, динамическая структура системы примерно одинакова в случаях интерактивного использования системы и в случае обращения к системе из прикладной программы. В последнем случае по естественным причинам отсутствует лишь процесс 1, осуществляющий функции терминального монитора.
Следует отметить, что на описанную структуру оказал большое влияние тот факт, что первый вариант Ingres реализовывался для 16-разрядных компьютеров, в которых размер виртуальной памяти процесса был весьма ограничен. Поскольку процессы системы функционировали синхронно, принципиальной выгоды от наличия нескольких процессов не было. Но подход к разбиению системы на несколько процессов позволил выработать разумную статическую структуризацию системы, в ряде компонентов которой не используются общие данные. Кроме того, с развитием системы стали использоваться и реальные возможности распараллеливания.
Организация данных в базе данных Ingres отличается от организации данных в System R прежде всего тем, что на логическом уровне поддерживаются только отношения. Для каждого отношения может быть создано несколько индексов, но для индексов не поддерживаются какие-либо специальные структуры данных; они представляются также в виде отношений (для которых, правда, уже нельзя создавать индексы).
Как мы уже отмечали, каждое отношение базы данных Ingres хранится в отдельном файле ОС UNIX. Поддерживается несколько способов организации таких файлов: неключевая, основанная на хэшировании и индексно-последовательная. При любой организации кортежи отношения хранятся в специальных "первичных" страницах файлов в том же стиле, что и в System R. Соответственно, каждый кортеж обладает уникальным и не изменяемым во все время существования кортежа идентификатором (tid), который "почти напрямую" адресует кортеж.
При неключевой организации отношения файл состоит только из первичных страниц. Для поиска кортежей, удовлетворяющих условию выборки, требуется последовательный просмотр всех первичных страниц файла. При организации на основе хэширования файл также состоит только из первичных страниц, но расположение кортежей в страницах определяется значением функции хэширования в зависимости от установленного ключа (части кортежа). Наконец, при индексно-последовательной организации кортежи отношения заносятся в файл в порядке возрастания установленного ключа. Для прямого доступа по ключу в том же файле поддерживается специальная индексная таблица. Заметим, что в начальных вариантах Ingres упорядоченность кортежей не поддерживалась в динамике, т.е. могла нарушаться при вставке новых или модификации существующих кортежей. Структура отношения может быть изменена в динамике путем выполнения специального оператора языка QUEL.
Для каждого из трех видов организации отношений поддерживался набор функций доступа (методов доступа) с фиксированным интерфейсом. Это позволяло добавлять новые методы доступа без требования переделки частей системы, которые ими пользовались.
Каждый набор функций включал следующие функции:
1) openr(descriptor, mode, relation-name)
Эта функция открывает отношение как файл ОС UNIX в режиме, определяемом значением параметра mode (на чтение или на чтение и модификацию). Кроме того, в выходной параметр descriptor заносится информация, характеризующая указанное отношение на основе системных каталогов. После выполнения функции openr параметр descriptor является обязательным входным параметром для всех прочих функций.
2) get(descriptor, tid, limit_tid, tuple, next_flag)
Если функция вызывается в режиме прямой выборки кортежа (значение параметра next_flag есть false), то в выходной параметр tuple заносится кортеж с идентификатором tid. При вызове в режиме сканирования (next_flag = true) функция выполняет при каждом вызове последовательную выборку кортежей начиная с кортежа с идентификатором tid и кончая кортежем с идентификатором limit_tid. Начальные установки tid и limit_tid производятся функцией find.
3) find(descriptor, key, tid, match_mode)
Функция устанавливает в выходной параметр tid идентификатор первого или последнего кортежа отношения, который соответствует значению заданного ключа в соответствие с режимом, задаваемым входным параметром match_mode. Если отношение имеет неключевую структуру, или если заданное значение ключа не соответствует типу ключевого атрибута отношения, в tid записывается идентификатор физически первого (или последнего) кортежа отношения.
4) paramd(descriptor, access_characteristics_structure)
5) parami(descriptor, access_characteristics_structure)
Эта пара функций позволяет узнать о ключевых атрибутах отношения, использование которых может оптимизировать доступ к этому отношению. Соответствующая информация записывается в выходной параметр access_characteristics_structure и используется системой для выбора значения параметра match_mode при последующих вызовах функции find.
6) insert(descriptor, tuple)
Заданный кортеж заносится в указанное отношение в соответствии со структурой отношения и значением ключевых полей.
7) replace(descriptor, tid, new_tuple)
8) delete(descriptor, tid)
Функции заменяют или удаляют кортеж отношения с указанным идентификатором.
9) closer(descriptor)
Функция закрывает соответствующий файл ОС UNIX и, возможно, обновляет содержимое отношений-каталогов.
Заметим, что перечисленные функции работают только с указанным отношением. В частности, если для отношения определены индексы, то их автоматическая модификация при изменении отношений не производится. Кроме того, функции не выполняют никаких действий по журнализации изменений или синхронизации параллельного доступа.
Манипуляционная часть языка QUEL является чистой реализацией реляционного исчисления кортежей. Это означает, что в операторах указываются условия, накладываемые на кортежи, с которыми необходимо произвести соответствующие действия.
Основной набор операторов
манипулирования данными включает операторы RETRIVE (выбрать), APPEND
(добавить), REPLACE (заменить) и DELETE (удалить). Перед выполнением
любого из этих операторов необходимо определить используемые в них
переменные кортежей, связав их с соответствующими отношениями путем
выполнения оператора RANGE:
RANGE OF variable-list IS relation-name
Продемонстрируем основные свойства операторов QUEL на примерах. Будем использовать базу данных СТУДЕНТЫ и ГРУППЫ:
RANGE OF S IS СТУДЕНТЫ
RANGE OF G IS ГРУППЫ
Пример 1. Выбрать имена студентов, куратором которых является Иванов.
RETRIEVE (S.СТУД_ИМЯ)
WHERE (S.ГРУП_НОМЕР = G.ГРУП_НОМЕР AND
G.КУРАТ_ИМЯ = "ИВАНОВ")
Пример 2. Занести в отношение НЕУСПЕВАЮЩИЕ номера студенческих билетов и имена неуспевающих студентов.
RETRIEVE INTO НЕУСПЕВАЮЩИЕ (S.СТУД_НОМЕР, S.СТУД_ИМЯ)
WHERE (S.СТУД_УСП = "NO")
Пример 3. Вывести фамилии студентов, получающих стипендию ниже средней.
RETRIEVE (S.СТУД_ИМЯ)
WHERE (S.СТУД_СТИП < AVG (S.СТУД_СТИП))
Как и в SQL, поддерживаются агрегатные функции COUNT, SUM, MAX, MIN и AVG.
Пример 4. Включить в группу 310 студента Петрова.
APPEND TO СТУДЕНТЫ (СТУД_ИМЯ = "ПЕТРОВ", ....)
Пример 5. Увеличить стипендию в 1,5 раза всем успевающим студентам.
REPLACE S(СТУД_СТИП BY СТУД_СТИП * 1,5)
WHERE (S.CТУД_УСП = "YES")
Пример 6. Удалить из списка групп все группы, в которых не учится ни один студент.
DELETE G
WHERE (G.ГРУП_РАЗМЕР = 0)
Кроме операторов манипулирования данными, язык QUEL содержит операторы для создания и уничтожения отношений:
CREATE имя_отношения (имя_атрибута IS тип_атрибута, ...)
DESTROY имя_отношения
а также два оператора изменения структур хранимых данных:
MODIFY имя_отношения TO структура_памяти
ON (ключ1, ключ2, ...) и
INDEX ON имя_отношения IS имя_индекса (ключ1, ключ2, ...)
Оператор MODIFY изменяет структуру хранимого отношения в соответствии с параметром структура_памяти и заданным набором ключевых атрибутов. Оператор INDEX создает отдельную индексную структуру для заданных полей данного отношения. Созданные индексы используются системой для оптимизации выполнения операторов манипулирования данными. Согласованность содержимого отношений и индексов поддерживается системой автоматически.
Язык QUEL содержит также операторы определения ограничений целостности, представлений и ограничений доступа. На них мы остановимся немного позже.
В том виде, в каком мы его кратко описали, язык QUEL предназначен для интерактивной работы с базами данных Ingres. Для программирования прикладных информационных систем, которые должны взаимодействовать с базами данных, был разработан язык программирования EQUEL, являющийся, по существу, расширением языка программирования Си путем встраивания в него операторов языка QUEL. Язык EQUEL определяется следующим образом:
Пример программы на языке EQUEL, выдающей номер группы по имени студента:
main()
{
## char stud_name[20];
## int group_number;
while (READ(stud_name_)
{
## RANGE OF S IS STUDENTS
## RETRIEVE (group_number = G.GROUP.NUMBER)
## WHERE (S.STUD_NAME = stud_name)
{
PRINT ("The group number of 'stud_name' is 'group_number');
}
}
}
Программа на языке EQUEL обрабатывается специальным препроцессором, который превращает ее в обычную Си-программу, содержащую вызовы Ingres с передачей в качестве параметров текстов операторов языка QUEL. Дальнейшую схему мы уже обсуждали.
Мы объединили эти три кажущиеся не очень близкими темы, потому что в Ingres для решения соответствующих проблем применяется единый подход, основанный на модификации операторов SQL. Начнем с представлений. Как и в System R (точнее, в языке SQL), представление базы данных - это некоторый именованный запрос с именованными полями результирующего отношения.
Например, оператор
DEFINE VIEW GROUP310
(STUD_NUMBER = S.STUD_NUMBER,
STUD_NAME = S.STUD_NAME,
STUD_STATUS = S.STUD_STATUS)
WHERE (S.GROUP_NUMBER = 310)
определяет представляемое отношение, включающее номера студенческих билетов и имена студентов из группы 310.
Предположим, что мы хотим теперь найти неуспевающих студентов в отношении GROUP310:
RANGE OF G310 IS GROUP310
RETRIEVE (G310.STUD_NAME)
WHERE (G310.STUD_STATUS = "NO")
Тогда после модификации этот запрос будет выглядеть следующим образом:
RETRIEVE (STUD_NUMBER = S.STUD_NUMBER, STUD_NAME =
S.STUD_NAME, STUD_STATUS = S.STUD_STATUS)
WHERE (S.GROUP_NUMBER = 310 AND
S.STUD_STATUS = "NO")
На
тех же самых принципах построен контроль доступа к данным и контроль
целостности баз данных. Например, ограничение доступа к отношению
СТУДЕНТЫ может быть определено следующим образом:
DEFINE PERMIT RETRIEVE, REPLACE
ON S
TO PETROV
AT TTA5
FROM 9:00 TO 17:50
ON MON TO FRI
WHERE (S.GROUP_NUMBER = 310)
Это означает, что Петрову разрешается читать и модифицировать отношение СТУДЕНТЫ с терминала TTA5 во время от 9 до 15:00 в рабочие дни недели, причем только те кортежи, которые удовлетворяют сформулированному условию. При компиляции любого оператора QUEL над отношением СТУДЕНТЫ этот оператор будет модифицироваться таким образом, чтобы он был выполнен при выполнении условий хотя бы одного из ограничений доступа.
Аналогично, если для отношения СТУДЕНТЫ определено ограничение целостности
DEFINE INTEGRITY
ON S
WHERE (S.STUD_STIP < 150,000)
то к условию любого оператора изменения кортежей отношения СТУДЕНТЫ будет через AND добавляться условия всех ограничений целостности, определенных для этого отношения.
В заключение этой лекции заметим, что конечно, в Ingres поддерживается механизм параллельных транзакций с соответствующей синхронизаций доступа и журнализация изменений баз данных. Однако нам не известны какие-либо особенности применяемых механизмов. На особенностях оптимизации операторов QUEL мы остановимся в лекции, посвященной оптимизациям в языках баз данных.