|
|
|
Close Help | ||||||||||||||
|
|
|
Close Help | ||||||||||||||
Литература
|
| |||||||||
| |||||||||
|
1940-е и 1950-е
"Персональные ЭВМ" - "пультовый режим" Библиотека
программ ввода-вывода, служебная программа.
Середина 1950-х
Пакетная обработка. Однопрограммный и
мультипрограммный режимы. Инструкция оператору -> паспорт задачи (простейший
язык управления заданиями). Требования к аппаратуре:
Середина 1960-х
Режим разделения времени. Терминалы, квантование,
свопинг, страничная и сегментная организация.
1970-е
Многопроцессорные ЭВМ, многомашинные комплексы, сети ЭВМ
1980-е
Персональные ЭВМ
1990-е
MPP, открытые системы, Internet
Недостатки мультипроцессоров
Почему создаются распределенные системы? В чем их преимущества перед централизованными ЭВМ?
1-ая причина - экономическая. Закон Гроша (Herb Grosh, 25 лет назад)- быстродействие процессора пропорциональна квадрату его стоимости. С появлением микропроцессоров закон перестал действовать - за двойную цену можно получить тот же процессор с несколько большей частотой.
2-ая причина - можно достичь такой высокой производительности путем объединения микропроцессоров, которая недостижима в централизованном компьютере.
3-я причина - естественная распределенность (банк, поддержка совместной работы группы пользователей ).
4-ая причина - надежность (выход из строя нескольких узлов незначительно снизит производительность).
5-я причина - наращиваемость производительности. В будущем главной причиной будет наличие огромного количества персональных компьютеров и необходимость совместной работы без ощущения неудобства от географического и физического распределения людей, данных и машин.
Почему нужно объединять PC в сети?
Недостатки распределенных систем:
Распределенные ОС - единый глобальный межпроцессный коммуникационный механизм, глобальная схема контроля доступа, одинаковое видение файловой системы. Вообще - иллюзия единой ЭВМ.
ОС мультипроцессорных ЭВМ - единая очередь процессов, ожидающих
выполнения, одна файловая система.
|
|
(2) Гибкость (не все еще ясно - потребуется менять
решения).
Использование монолитного ядра ОС или микроядра.
(3) Надежность.
(4) Производительность.
Грануллированность. Мелкозернистый и
крупнозернистый параллелизм (fine-grained parallelism, coarse-grained
parallelism). Устойчивость к ошибкам требует дополнительных накладных расходов.
(5) Масштабируемость.
Плохие решения:
Большой объем этой информации делает дорогими операции создания процессов, их
переключение. Потребность в легковесных процессах, нитях (threads) возникла еще
на однопроцессорных ЭВМ (физические процессы или их моделирование, совмещение
обменов и счета), но для использования достоинств многопроцессорных ЭВМ с общей
памятью они просто необходимы. Процессы могут быть независимыми, которые не
требуют какой-либо синхронизации и обмена информацией (но могут конкурировать за
ресурсы), либо взаимодействующими.
Процесс p1 выполняет оператор I = I+J, а процесс p2 - оператор
I = I-K машинные коды выглядят так:
| Процесс p1 | Процесс p2 | |
| Load R1,I | Load R1,I | |
| Load R2,J | Load R2,J | |
| Add R1,R2 | Sub R1,R2 | |
| Store R1,I | Store R1,I |
Результат зависит от порядка выполнения этих команд. Требуется взаимное исключение критических интервалов. Решение проблемы взаимного исключения должно удовлетворять требованиям:
Взаимное исключение критических интервалов в однопроцессорной ЭВМ.
Взаимное исключение критических интервалов в многопроцессорной ЭВМ. Программные решения на основе неделимости операций записи и чтения из памяти.
Алгоритм Деккера (1968).
int turn;
boolean flag[2 ];
proc( int i )
{
while (TRUE)
{
<вычисления>;
enter_region( i );
<критический интервал>;
leave_region( i );
}
}
void enter_region( int i )
{
try: flag[i] = TRUE;
while (flag [(i + 1) % 2])
{
if ( turn == i ) continue;
flag[ i ] = FALSE;
while ( turn != i );
goto try;
}
}
void leave_region( int i )
{
turn = ( turn +1 ) % 2;
flag[ i ] = FALSE;
}
turn = 0;
flag[ 0 ] = FALSE;
flag[ 1 ] = FALSE;
proc( 0 ) AND proc( 1 ) /* запустили 2 процесса */
Алгоритм Петерсона (1981)
int turn;
int flag[ 2 ];
void enter_region( int i )
{
int other; /* номер другого процесса */
other = 1 - i;
flag[ i ] = TRUE;
turn = i;
while (turn == i && flag[ other ] == TRUE) /* пустой оператор */;
}
void leave_region( int i )
{
flag[ i ] = FALSE;
}
Использование неделимой операции TEST_and_SET_LOCK.
Операция
TSL(r,s): [r = s; s = 1]
Квадратные скобки - используются для
спецификации неделимости операций.
enter_region: tsl reg, flag cmp reg, #0 /* сравниваем с нулем */ jnz enter_region /* если не нуль - цикл ожидания */ ret leave_region: mov flag, #0 /* присваиваем нуль */ ret
Семафоры Дейкстры (1965).
Семафор - неотрицательная целая
переменная, которая может изменяться и проверяться только посредством двух
функций:
Функция запроса семафора
P(s): [if (s == 0)
<заблокировать текущий процесс>; else s = s-1;]
Функция освобождения семафора
V(s): [if (s == 0)
<разблокировать один из заблокированных процессов>; s = s+1;]
Двоичные семафоры как частный случай общих (считающих).
Использование семафоров для взаимного исключения критических интервалов и для
координации в задаче производитель-потребитель. Задача
производитель-потребитель (поставщик-потребитель, проблема ограниченного
буфера).
semaphore s = 1; semaphore full = 0; semaphore empty = N; |
|
producer()
{
int item;
while (TRUE)
{
produce_item(&item);
P(empty);
P(s);
enter_item(item);
V(s);
V(full);
}
}
|
consumer()
{
int item;
while (TRUE)
{
P(full);
P(s);
remove_item(&item);
V(s);
V(empty);
consume_item(item);
}
}
|
producer() AND consumer() /* запустили 2 процесса */ | |
Реализация семафоров. Мультипрограммный режим.
Для многопроцессорной ЭВМ первые два способа не годятся. Для реализации третьего способа достаточно команды TSL и возможности объявлять прерывание указанному процессору. Блокирование процесса и переключение на другой - не эффективно, если семафор захватывается на очень короткое время. Ожидание освобождения таких семафоров может быть реализовано в ОС посредством циклического опроса значения семафора. Недостатки такого "активного ожидания" - бесполезная трата времени, нагрузка на общую память, и возможность фактически заблокировать работу процесса, находящегося в критическом нтервале
Если произведенный объект используется многими, то семафоры не годятся.
События.
Это переменные, показывающие, что произошли определенные
события. Для объявления события служит оператор POST(имя переменной), для
ожидания события - WAIT (имя переменной). Для чистки (присваивания нулевого
значения) - оператор CLEAR(имя переменной). Варианты реализации - не хранящие
информацию (по оператору POST из ожидания выводятся только те процессы, которые
уже выдали WAIT) , однократно объявляемые (нет оператора чистки).
Метод последовательной верхней релаксации (SOR) с использованием массива событий.
float A[ L1 ][ L2 ];
struct event s[ L1 ][ L2 ];
for ( i = 0; i < L1; i++)
for ( j = 0; j < L2; j++) { clear( s[ i ][ j ]) };
for ( j = 0; j < L2; j++) { post( s[ 0 ][ j ]) };
for ( i = 0; i < L1; i++) { post( s[ i ][ 0 ]) };
..............
..............
parfor ( i = 1; i < L1-1; i++)
parfor ( j = 1; j < L2-1; j++)
{
wait( s[ i-1 ][ j ]);
wait( s[ i ][ j-1 ]);
A[i][j] = (A[i-1][j] + A[i+1][j] + A[i][j-1] + A[i][j+1])/4;
post( s[ i ][ j ]);
}
Обмен сообщениями (message passing) Хоар (Xoare) 1978 год,
"Взаимодействующие параллельные процессы".
Цели - избавиться от проблем
разделения памяти и предложить модель взаимодействия процессов для
распределенных систем.
send(destination, &message,
msize);
receive([source], &message, msize);
Адресат - процесс. Отправитель - может не специфицироваться (любой). С буферизацией (почтовые ящики) или нет (рандеву - Ада, Оккам). Пайпы ОС UNIX - почтовые ящики, заменяют файлы и не хранят границы сообщений (все сообщения объединяются в одно большое, которое можно читать произвольными порциями.
Пример использования буферизуемых сообщений.
#define N 100 /* максимальное число сообщений в буфере*/
#define msize 4 /* размер сообщения*/
typedef int message[msize];
producer()
{
message m;
int item;
while (TRUE)
{
produce_item(&item);
receive(consumer, &m, msize); /* получает пустой */
/* "контейнер" */
build_message(&m, item); /* формирует сообщение */
send(consumer, &m, msize);
};
}
consumer()
{
message m;
int item, i;
for (i = 0; i < N; i ++)
send (producer, &m, msize); /* посылает все пустые */
/* "контейнеры" */
while (TRUE)
{
receive(producer, &m, msize);
extract_item(&m, item);
send(producer, &m, msize); /* возвращает "контейнер" */
consume_item(item);
};
}
producer() AND consumer() /* запустили 2 процесса */
Механизмы семафоров и обмена сообщениями взаимозаменяемы семантически и на
мультипроцессорах могут быть реализованы один через другой. Другие классические
задачи взаимодействия процессов - проблема обедающих философов (Dijkstra) и
"читатели-писатели".
Планирование процессоров очень сильно влияет на производительность мультипроцессорной системы. Можно выделить следующие главные причины деградации производительности:
Применяются следующие стратегии борьбы с деградацией производительности.
Все компьютеры в распределенной системе связаны между собой коммуникационной сетью. Коммуникационные сети подразделяются на широкомасштабные (Wide Area Networks, WANs) и локальные (Local Area Networks, LANs).
Широкомасштабные сети
WAN состоит из коммуникационных ЭВМ,
связанных между линии, собой коммуникационными линиями (телефонные радиолинии,
спутниковые каналы, оптоволокно) и обеспечивающих транспортировку сообщений.
Обычно используется техника store-and-forward, когда следующий с ссобщения
передаются из одного компьютера в промежуточной буферизацией.
Коммутация пакетов или коммутация линий.
Коммутация линий
(телефонные разговоры) требует резервирования линий на время всего сеанса
общения двух устройств.
Пакетная коммутация основана на разбиении
сообщений в пункте отправления на порции (пакеты), посылке пакетов по адресу
назначения, и сборке сообщения из пакетов в пункте назначения. При этом линии
используются эффективнее, сообщения могут передаваться быстрее, но требуется
работа по разбиению и сборке сообщений, а также возможны задержки (для передачи
речи или музыки такой метод не годится).
ISO OSI (International Standards Organizations”s Reference Model of Open Systems Interconnection) организует коммуникационные протоколы в виде семи уровней и специфицирует функции каждого уровня.
Локальные сети.
Особенности LAN:
Свойственные многоуровневой модели ISO OSI накладные расходы являются причиной того, что в LAN применяются более простые протоколы.
Клиент-сервер
Можно избежать подтверждения получения сервером
сообщения-запроса от клиента, если ответ сервера должен последовать скоро.
Удаленный вызов процедур
Send, receive - подход ввода/вывода Более
естественный подход, применяемый в централизованных ЭВМ - вызов процедур.
Birrell and Nelson (1984) (независимо и раньше - Илюшин А.И.,1978) предложили позволить вызывающей программе находиться на другой ЭВМ.
MPP с распределенной памятью может рассматриваться как частный случай локальной сети. Решетка транспьютеров, в которой каждый транспьютер параллельно с вычислениями может обмениваться одновременно по 8 каналам с 4 соседями, является хорошим примером, для которого будут формулироваться различные экзаменационные задачи. Время передачи сообщения между двумя узлами транспьютерной матрицы (характеристики аппаратуры - время старта передачи Ts, время передачи одного байта информации соседнему узлу Tb, процессорные операции, включая чтение из памяти и запись в память считаются бесконечно быстрыми). За время Ts+Tb транспьютер может передать 1 байт информации своим четырем соседям и принять от них 4 байта информации (по одному байту от каждого). Конвейеризация и параллельное использование нескольких маршрутов.
Обмен сообщениями между прикладными процессами
SEND,
RECEIVE (адресат/отправитель, [тэг], адрес памяти, длина)
Адресация - физический/логический номер процессора, уникальный идентификатор динамически создаваемого процесса, служба имен (сервер имен или широковещание - broadcasting). Обычно пересылка в соседний компьютер требует три копирования - из памяти процесса-отправителя в буфер ОС на своем компьютере, пересылка между буферами ОС, копирование в память процесса-получателя.
Блокирующие операции send (до освобождения памяти с данными или до завершения фактической передачи) и неблокирующие.
Буферизуемые и небуферизуемые (rendezvous или с потерей информации при отсутствии receive).
(1) Цели:
(2) Что включено в MPI ?
(3) Что не включено в MPI ?
(4) Некоторые понятия.
Коммуникационные операции могут быть:
Операция называется локальной, если ее выполнение не требует коммуникаций; нелокальной, если ее выполнение может требовать коммуникаций; коллективной, если в ее выполнении должны участвовать все процессы группы.
(5) Группы, контексты, коммуникаторы.
Группа - упорядоченное (от 0 до ранга группы) множество идентификаторов процессов (т.е. процессов). Группы служат для указания адресата при посылке сообщений (процесс-адресат специфицируется своим номером в группе), определяют исполнителей коллективных операций. Являются мощным средством функционального распараллеливания - позволяют разделить группу процессов на несколько подгрупп, каждая из которых должна выполнять свою параллельную процедуру. При этом существенно упрощается проблема адресации при использовании параллельных процедур.
Контекст - область “видимости” для сообщений, аналогичное области видимости переменных в случае вложенных вызовов процедур. Сообщения, посланные в некотором контексте, могут быть приняты только в этом же контексте. Контексты - также важные средства поддержки параллельных процедур.
Коммуникаторы - позволяют ограничить область видимости (жизни, определения) сообщений рамками некоторой группы процессов, т.е. могут рассматриваться как пара - группа и контекст. Кроме того, они служат и для целей оптимизации, храня необходимые для этого дополнительные объекты. Имеются предопределенные коммуникаторы (точнее, создаваемые при инициализации MPI-системы):
(6) Операции над группами (локальные, без обмена сообщениями).
Для
поддержки пользовательских серверов имеется коллективная операция разбиения
группы на подгруппы по ключам, которые указывает каждый процесс группы. Для
поддержки связывания с серверами, имеются средства построения коммуникатора по
некоторому имени, известному и серверу и клиентам.
(7) Точечные коммуникации.
Основные операции - send,
receive Операции могут быть блокирующими и неблокирующими.
В операции send задается:
В операции receive задается:
Имеется четыре режима коммуникаций - стандартный, буферизуемый, синхронный и режим готовности.
В стандартном режиме последовательность выдачи операций send и receive произвольна, операция send завершается тогда, когда сообщение изъято из памяти и она уже может использоваться процессом. При этом выполнение операции может осуществляться независимо от наличия receive, либо требовать наличие (вопрос реализации MPI). Поэтому операция считается нелокальной.
В буферизуемом режиме последовательность выдачи операций send и receive произвольна, операция send завершается тогда, когда сообщение изъято из памяти и помещено в буфер. Если места в буфере нет - ошибка программы (но есть возможность определить свой буфер). Операция локальная.
В синхронном режиме последовательность выдачи операций произвольна, но операция send завершается только после выдачи и начала выполнения операции receive. Операция нелокальная. В режиме готовности операция send может быть выдана только после выдачи соответствующей операции receive, иначе программа считается ошибочной и результат ее работы неопределен. Операция локальная.
Во всех четырех режимах операция receive завершается после получения сообщения в заданный пользователем буфер приема.
Неблокирующие операции не приостанавливают процесс до своего завершения, а возвращают ссылку на коммуникационный объект, позволяющий опрашивать состояние операции или дожидаться ее окончания. Имеются операции проверки поступающих процессу сообщений, без чтения их в буфер (например, для определения длины сообщения и запроса затем памяти под него). Имеется возможность аварийно завершать выданные неблокирующие операции, и поэтому предоставлены возможности проверки, хорошо ли завершились операции. Имеется составная операция send-receive, позволяющая избежать трудностей с порядком выдачи отдельных операций в обменивающихся между собой процессах. Для частного случая обмена данными одного типа и длины предлагается специальная операция сообщения (send-receive-replace), в которой для посылки и приема используется один буфер.
(8) Коллективные коммуникации.
Для обеспечения коллективных
коммуникаций введены следующие функции:
Схема перемещения данных между 4 процессами
|
BROADCAST |
|
||||||||||||||||||||||||||||||||||||||
|
SCATTER GATHER |
|
||||||||||||||||||||||||||||||||||||||
|
ALLGATHER |
|
||||||||||||||||||||||||||||||||||||||
|
ALLTOALL |
|
Названия функций и параметры:
MPI_BARRIER(IN
comm)
MPI_BCAST(IN/OUT buffer, IN cnt, IN type, IN root, IN
comm)
MPI_GATHER(IN sendbuf, IN sendcnt, IN sendtype, OUT recvbuf, IN
recvcnt, IN recvtype, IN root, IN comm)
MPI_SCATTER(IN sendbuf, IN
sendcnt, IN sendtype, OUT recvbuf, IN recvcnt, IN recvtype, IN root, IN
comm)
MPI_ALLGATHER(IN sendbuf, IN sendcnt, IN sendtype, OUT recvbuf,
IN recvcnt, IN recvtype, IN comm)
MPI_ALLTOALL(IN sendbuf, IN sendcnt,
IN sendtype, OUT recvbuf, IN recvcnt, IN recvtype, IN comm)
Широко известная система PVM [5] была создана для объединения нескольких связанных сетью рабочих станций в единую виртуальную параллельную ЭВМ. Система представляет собой надстройку над операционной системой UNIX и используется в настоящее время на различных аппаратных платформах, включая и ЭВМ с массовым параллелизмом.
Задача пользователя представляет собой множество подзадач, которые динамически создаются на указанных процессорах распределенной системы и взаимодействуют между собой путем передачи и приема сообщений (а также посредством механизма сигналов).
Достоинства - простота, наличие наследованного от OS UNIX аппарата процессов и сигналов, а также возможность динамического добавления к группе вновь созданных процессов.
Недостатки - низкая производительность и функциональная ограниченность
(например, имеется только один режим передачи сообщений - с буферизацией).
Обычно децентрализованные алгоритмы имеют следующие свойства:
Первые три пункта все говорят о недопустимости сбора всей информации для
принятия решения в одно место. Обеспечение синхронизации без централизации
требует подходов, отличных от используемых в традиционных ОС. Последний пункт
также очень важен - в распределенных системах достигнуть согласия относительно
времени совсем непросто. Важность наличия единого времени можно оценить на
примере программы make в ОС UNIX. Главные теоретические проблемы - отсутствие
глобальных часов и невозможность зафиксировать глобальное состояние (для анализа
ситуации - обнаружения дедлоков, для организации промежуточного запоминания).
Аппаратные часы (скорее таймер - счетчик временных сигналов и регистр с начальным значением счетчика) основаны на кварцевом генераторе и могут в разных ЭВМ различаться по частоте.
В 1978 году Lamport показал, что синхронизация времени возможна, и предложил алгоритм для такой синхронизации. При этом он указал, что абсолютной синхронизации не требуется. Если два процесса не взаимодействуют, то единого времени им не требуется. Кроме того, в большинстве случаев согласованное время может не иметь ничего общего с астрономическим временем, которое объявляется по радио. В таких случаях можно говорить о логических часах.
Для синхронизации логических часов Lamport определил отношение "произошло до". Выражение a->b читается как "a произошло до b" и означает, что все процессы согласны, что сначала произошло событие "a", а затем "b". Это отношение может в двух случаях быть очевидным:
Отношение -> является транзитивным.
Если два события x и y случились в различных процессах, которые не обмениваются сообщениями, то отношения x->y и y->x являются неверными, а эти события называют одновременными.
Введем логическое время С таким образом, что если a->b, то C(a) < C(b)
Алгоритм:
| Логическое время без коррекции. | Логическое время с коррекцией. | |
| 0 | 0 | 0 | 0 | 0 | 0 | |||||
| 6 | >- | 8 | 10 | 6 | >- | 8 | 10 | |||
| 12 | 16 | 20 | 12 | 16 | 20 | |||||
| 18 | 24 | >- | 30 | 18 | 24 | >- | 30 | |||
| 24 | 32 | 40 | 24 | 32 | 40 | |||||
| 30 | 40 | 50 | 30 | 40 | 50 | |||||
| 36 | 48 | -< | 60 | 36 | 48 | -< | 60 | |||
| 42 | 56 | 70 | 42 | 61 | 70 | |||||
| 48 | -< | 64 | 80 | 48 | -< | 69 | 80 | |||
| 54 | 72 | 90 | 70 | 77 | 90 | |||||
| 60 | 80 | 100 | 76 | 85 | 100 |
Для целей упорядочения всех событий удобно потребовать, чтобы их времена никогда не совпадали. Это можно сделать, добавляя в качестве дробной части к времени уникальный номер процесса (40.1, 40.2). Однако логических часов недостаточно для многих применений (системы управления в реальном времени).
Физические часы.
После изобретения в 17 веке механических часов
время измерялось астрономически. Интервал между двумя последовательными
достижениями солнцем наивысшей точки на небе называется солнечным днем.
Солнечная секунда равняется 1/86400(24*3600) части солнечного дня.
В 1940-х годах было установлено, что период вращения земли не постоянен - земля замедляет вращение из-за приливов и атмосферы. Геологи считают, что 300 миллионов лет назад в году было 400 дней. Происходят и изменения длительности дня по другим причинам. Поэтому стали вычислять за длительный период среднюю солнечную секунду.
С изобретением в 1948 году атомных часов появилась возможность точно измерять время независимо от колебаний солнечного дня. В настоящее время 50 лабораторий в разных точках земли имеют часы, базирующиеся на частоте излучения Цезия-133. Среднее значение является международным атомным временем (TAI), исчисляемым с 1 июля 1958 года.
Отставание TAI от солнечного времени компенсируется становится добавлением секунды тогда, когда разница больше 800 мксек. Это скорректированное время, называеемое UTC (Universal Coordinated Time), заменило прежний стандарт (Среднее время по Гринвичу - астрономическое время). При объявлении о добавлении секунды к UTC электрические компании меняют частоту с 60 Hz на 61 Hz (c 50 на 51) на период времени в 60 (50) секунд. Для обеспечения точного времени сигналы WWV передаются коротковолновым передатчиком (Fort Collins, Colorado) в начале каждой секунды UTC. Есть и другие службы времени.
Алгоритмы синхронизации времени.
Две проблемы - часы не должны
ходить назад (надо ускорять или замедлять их для проведения коррекции) и
ненулевое время прохождения сообщения о времени (можно многократно замерять
время прохождения и брать среднее).
Многие распределенные алгоритмы требуют, чтобы один из процессов выполнял функции координатора, инициатора или некоторую другую специальную роль. Выбор такого специального процесса будем называть выбором координатора. При этом очень часто бывает не важно, какой именно процесс будет выбран. Можно считать, что обычно выбирается процесс с самым большим уникальным номером. Могут применяться разные алгоритмы, имеющие одну цель - если процедура выборов началась, то она должна закончиться согласием всех процессов относительно нового координатора.
Алгоритм "задиры"
Если процесс обнаружит, что координатор очень
долго не отвечает, то инициирует выборы. Процесс P проводит выборы
следующим образом:
В любой момент процесс может получить сообщение "ВЫБОРЫ" от одного из коллег с меньшим номером. В этом случае он посылает ответ "OK", чтобы сообщить, что он жив и берет проведение выборов на себя, а затем начинает выборы (если к этому моменту он уже их не вел). Следовательно, все процессы прекратят выборы, кроме одного - нового координатора. Он извещает всех о своей победе и вступлении в должность сообщением "КООРДИНАТОР".
Если процесс выключился из работы, а затем захотел восстановить свое участие, то он проводит выборы (отсюда и название алгоритма).
Круговой алгоритм.
Алгоритм основан на использовании кольца
(физического или логического), но без маркера. Каждый процесс знает следующего
за ним в круговом списке. Когда процесс обнаруживает отсутствие координатора, он
посылает следующему за ним процессу сообщение "ВЫБОРЫ" со своим номером. Если
следующий процесс не отвечает, то сообщение посылается процессу, следующему за
ним, и т.д., пока не найдется работающий процесс. Каждый работающий процесс
добавляет в список работающих свой номер и переправляет сообщение дальше по
кругу. Когда процесс обнаружит в списке свой собственный номер (круг пройден),
он меняет тип сообщения на "КООРДИНАТОР" и оно проходит по кругу, извещая всех о
списке работающих и координаторе (процессе с наибольшим номером в списке). После
прохождения круга сообщение удаляется.
Централизованный алгоритм
Все процессы запрашивают у координатора
разрешение на вход в критическую секцию и ждут этого разрешения. Координатор
обслуживает запросы в порядке поступления. Получив разрешение процесс входит в
критическую секцию. При выходе из нее он сообщает об этом координатору.
Количество сообщений на одно прохождение критической секции - 3.
Недостатки алгоритма - обычные недостатки централизованного алгоритма (крах
координатора или его перегрузка сообщениями).
Алгоритм с круговым маркером.
Все процессы составляют логическое
кольцо, когда каждый знает, кто следует за ним. По кольцу циркулирует маркер,
дающий право на вход в критическую секцию. Получив маркер (посредством сообщения
точка-точка) процесс либо входит в критическую секцию (если он ждал разрешения)
либо переправляет маркер дальше. После выхода из критической секции маркер
переправляется дальше, повторный вход в секцию при том же маркере не
разрешается.
Проблемы:
Алгоритм древовидный маркерный (Raymond)
Все процессы представлены
в виде сбалансированного двоичного дерева. Каждый процесс имеет очередь запросов
от себя и соседних процессов (1-го, 2-х или 3-х) и указатель в направлении
владельца маркера.
Вход в критическую секцию:
Если есть маркер, то процесс выполняет
КС.
Если нет маркера, то процесс:
Поведение процесса при приеме сообщений:
Процесс, не находящийся внутри КС
должен реагировать на сообщения двух видов -"МАРКЕР" и "ЗАПРОС".
А) Пришло сообщение "МАРКЕР"
Б) Пришло сообщение "ЗАПРОС".
Выход из критической секции.
Если очередь запросов пуста, то при выходе
ничего не делается, иначе - перейти к пункту М1.
Децентрализованный алгоритм на основе временных меток.
Алгоритм
носит имя Ricart-Agrawala и является улучшением алгоритма, который предлжил
Lamport.
Требуется глобальное упорядочение всех событий в системе по времени.
Вход в критическую секцию:
Когда процесс желает войти в критическую
секцию, он посылает всем процессам сообщение-запрос, содержащее имя критической
секции, номер процесса и текущее время. После посылки запроса процесс ждет, пока
все дадут ему разрешение. После получения от всех разрешения, он входит в
критическую секцию.
Поведение процесса при приеме запроса:
Когда процесс получает
сообщение-запрос, в зависимости от своего состояния по отношению к указанной
критической секции он действует одним из следующих способов.
Выход из критической секции:
После выхода из секции он посылает сообщение
"OK" всем процессам, запросы от которых он запомнил, а затем стирает все
запомненные запросы.
Количество сообщений на одно прохождение секции - 2(n-1), где n - число
процессов. Кроме того, одна критическая точка заменилась на n точек (если
какой-то процесс перестанет функционировать, то отсутствие разрешения от него
всех остановит). И, наконец, если в централизованном алгоритме есть опасность
перегрузки координатора, то в этом алгоритме перегрузка любого процесса приведет
к тем же последствиям. Некоторые улучшения алгоритма (например, ждать разрешения
не от всех, а от большинства) требуют наличия неделимых широковещательных
рассылок сообщений.
Алгоритм широковещательный маркерный (Suzuki-Kasami).
Маркер
содержит:
Вход в критическую секцию:
Поведение процесса при приеме запроса:
Выход из критической секции процесса Pk:
Измерение производительности
Введем следующие три метрики.
При оценке производительности интересны две ситуации:
Для некоторых метрик интересно оценить наилучшее и наихудшее значение
(которые часто достигаются при низкой или высокой загрузки).
Сравнение алгоритмов.
При оценке времен исходим из коммуникационной
среды, в которой время одного сообщения (Т) равно времени
широковещательного сообщения.
|
Все алгоритмы не устойчивы к крахам процессов (децентрализованные даже более
чувствительны к ним, чем централизованный). Они в таком виде не годятся для
отказоустойчивых систем.
Сетевая прозрачность.
Самая важная цель - обеспечить те же самые
возможности доступа к файлам, распределенным по сети ЭВМ, которые обеспечиваются
в системах разделения времени на централизованных ЭВМ.
Высокая доступность.
Другая важная цель - обеспечение высокой
доступности. Ошибки систем или осуществление операций копирования и
сопровождения не должны приводить к недоступности файлов.
Понятие файлового сервиса и файлового сервера.
Файловый сервис - это то, что файловая система предоставляет своим
клиентам, т.е. интерфейс с файловой системой.
Файловый сервер - это
процесс, который реализует файловый сервис.
Пользователь не должен знать, сколько файловых серверов имеется и где они расположены.
Так, как файловый сервер обычно является обычным пользовательским процессом, то в системе могут быть различные файловые серверы, предоставляющие различный сервис (например, UNIX файл сервис и MS-DOS файл сервис).
Файл может иметь атрибуты (информация о файле, не являющаяся его частью). Типичные атрибуты - владелец, размер, дата создания и права доступа.
Важный аспект файловой модели - могут ли файлы модифицироваться после создания. Обычно могут, но есть системы с неизменяемыми файлами. Такие файлы освобождают разработчиков от многих проблем при кэшировании и размножении.
Защита обеспечивается теми же механизмами, что и в однопроцессорных ЭВМ - мандатами и списками прав доступа. Мандат - своего рода билет, выданный пользователю для каждого файла с указанием прав доступа. Список прав доступа задает для каждого файла список пользователей с их правами. Простейшая схема с правами доступа - UNIX схема, в которой различают три типа доступа (чтение, запись, выполнение), и три типа пользователей (владелец, члены его группы, и прочие).
Файловый сервис может базироваться на одной из двух моделей - модели
загрузки/разгрузки и модели удаленного доступа. В первом случае
файл передается между клиентом (памятью или дисками) и сервером целиком, а во
втором файл сервис обеспечивает множество операций (открытие, закрытие, чтение и
запись части файла, сдвиг указателя, проверку и изменение атрибутов, и т.п.).
Первый подход требует большого объема памяти у клиента, затрат на перемещение
ненужных частей файла. При втором подходе файловая система функционирует на
сервере, клиент может не иметь дисков и большого объема памяти.
Определяет алфавит и синтаксис имен. Для спецификации типа информации в файле используется часть имени (расширение) либо явный атрибут.
Все распределенные системы позволяют директориям содержать поддиректории - такая файловая система называется иерархической. Некоторые системы позволяют создавать указатели или ссылки на произвольные директории, которые можно помещать в директорию. При этом можно строить не только деревья, но и произвольные графы (разница между ними очень важна для распределенных систем, поскольку в случае графа удаление связи может привести к появлению недостижимых поддеревьев. Обнаруживать такие поддеревья в распределенных системах очень трудно).
Ключевое решение при конструировании распределенной файловой системы - должны или не должны машины (или процессы) одинаково видеть иерархию директорий. Тесно связано с этим решением наличие единой корневой директории (можно иметь такую директорию с поддиректориями для каждого сервера).
Прозрачность именования.
Две формы прозрачности именования
различают - прозрачность расположения (/server/d1/f1) и прозрачность миграции
(когда изменение расположения файла не требует изменения имени).
Имеются три подхода к именованию:
Еще одна проблема - трудно сохранить семантику общего указателя файла (в UNIX он общий для открывшего файл процесса и его дочерних процессов) - для процессов на разных ЭВМ трудно иметь общий указатель.
Неизменяемые файлы - очень радикальный подход к изменению
семантики разделения файлов.
Только две операции - создать и читать. Можно
заменить новым файлом старый - т.е. можно менять директории. Если один процесс
читает файл, а другой его подменяет, то можно позволить первому процессу
доработать со старым файлом в то время, как другие процессы могут уже работать с
новым.
Второй вопрос - должны ли быть файловый сервер и сервер директорий отдельными серверами или быть объединенными в один сервер. Разделение позволяет иметь разные серверы директорий (UNIX, MS-DOS) и один файловый сервер. Объединение позволяет сократить коммуникационные издержки.
В случае разделения серверов и при наличии разных серверов директорий для различных поддеревьев возникает следующая проблема. Если первый вызванный сервер будет поочередно обращаться ко всем следующим, то возникают большие коммуникационные расходы. Если же первый сервер передает остаток имени второму, а тот третьему, и т.д., то это не позволяет использовать RPC.
Возможный выход - использование кэша подсказок. Однако в этом случае при получении от сервера директорий устаревшего двоичного имени клиент должен быть готов получить отказ от файлового сервера и повторно обращаться к серверу директорий (клиент может не быть конечным пользователем!).
Последний важный вопрос - должны ли серверы хранить информацию о клиентах.
Во-первых, хранение файлов на дисках сервера. Нет проблемы когерентности, так как одна копия файла существует. Главная проблема - эффективность, поскольку для обмена с файлом требуется передача информации в обе стороны и обмен с диском.
Кэширование в памяти сервера. Две проблемы - помещать в кэш файлы целиком или блоки диска, и как осуществлять выталкивание из кэша.
Коммуникационные издержки остаются.
Избавиться от коммуникаций позволяет кэширование в машине клиента.
Кэширование на диске клиента может не дать преимуществ перед кэшированием в памяти сервера, а сложность повышается значительно.
Поэтому рассмотрим подробнее организацию кэширования в памяти клиента.
Алгоритм с отложенной записью.
Через регулярные промежутки
времени все модифицированные блоки пишутся в файл. Эффективность выше, но
семантика непонятная пользователю (UNIX).
Алгоритм записи в файл при закрытии файла.
Реализует
семантику сессий. Не намного хуже случая, когда два процесса на одной ЭВМ
открывают файл, читают его, модифицируют в своей памяти и пишут назад в файл.
Алгоритм централизованного управления.
Можно выдержать
семантику UNIX, но не эффективно, ненадежно, и плохо масштабируется.
Каждый сервер экспортирует некоторое число своих директорий для доступа к ним удаленных клиентов. При этом экспортируются директории со всеми своими поддиректориями, т.е. фактически поддеревья. Список экспортируемых директорий хранится в специальном файле, что позволяет при загрузке сервера автоматически их экспортировать.
Клиент получает доступ к экспортированным директориям путем их монтирования. Если клиент не имеет дисков, то может монтировать директории в свою корневую директорию.
Если несколько клиентов одновременно смонтировали одну и ту же директорию, то они могут разделять файлы в общей директории без каких либо дополнительных усилий. Простота - достоинство NFS.
Многие клиенты монтируют требуемые удаленные директории автоматически при запуске (используя командную процедуру shell-интерпретатора ОС UNIX).
Версия ОС UNIX, разработанная Sun (Solaris), имеет свой специальный режим автоматического монтирования. С каждой локальной директорией можно связать множество удаленных директорий. Когда открывается файл, отсутствующий в локальной директории, ОС посылает запросы всем серверам (владеющим указанными директориями). Кто ответит первым, директория того и будет смонтирована. Такой подход обеспечивает и надежность, и эффективность (кто свободнее, тот раньше и ответит). При этом подразумевается, что все альтернативные директории идентичны. Поскольку NFS не поддерживает размножение файлов или директорий, то такой режим автоматического монтирования в основном используется для директорий с кодами программ или других редко изменяемых файлов.
Второй протокол - для доступа к директориям и файлам. Клиенты посылают сообщения, чтобы манипулировать директориями, читать и писать файлы. Можно получить атрибуты файла. Поддерживается большинство системных вызовов ОС UNIX, исключая OPEN и CLOSE. Для получения дескриптора файла по его символическому имени используется операция LOOKUP, отличающаяся от открытия файла тем, что никаких внутренних таблиц не создается. Таким образом, серверы в NFS не имеют состояния (stateless). Поэтому для захвата файла используется специальный механизм.
NFS использует механизм защиты UNIX. В первых версиях все запросы содержали идентификатор пользователя и его группы (для проверки прав доступа). Несколько лет эксплуатации системы показали слабость такого подхода. Теперь используется криптографический механизм с открытыми ключами для проверки законности каждого запроса и ответа. Данные не шифруются.
Все ключи, используемые для контроля доступа, поддерживаются специальным сервисом (и серверами) - сетевым информационным сервисом (NIS). Храня пары (ключ, значение), сервис обеспечивает выдачу значения кода при правильном подтверждении ключей. Кроме того, он обеспечивает отображение имен машин на их сетевые адреса, и другие отображения. NIS-серверы используют схему главный -подчиненные для реализации размножения (“ленивое” размножение).
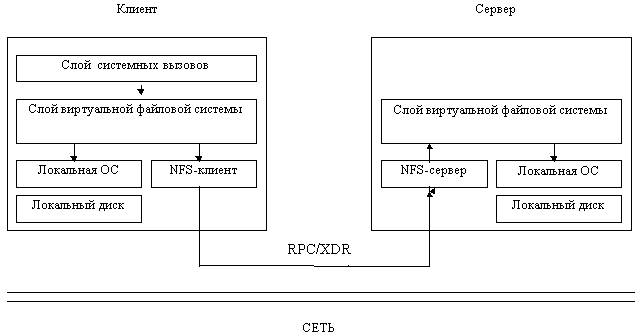
Задача уровня виртуальной файловой системы - поддерживать для каждого открытого файла строку в таблице (v-вершину), аналогичную i-вершине UNIX. Эта строка позволяет различать локальные файлы от удаленных. Для удаленных файлов вся необходимая информация хранится в специальной r-вершине в NFS-клиенте, на которую ссылается v-вершина. У сервера нет никаких таблиц.
Передачи информации между клиентом и сервером NFS производятся блоками размером 8К (для эффективности).
Два кэша - кэш данных и кэш атрибутов файлов (обращения к ним очень часты, разработчики NFS исходили из оценки 90%). Реализована семантика отложенной записи - предмет критики NFS.
Имеется также кэш подсказок для ускорения получения v-вершины по символическому имени. При использовании устаревшей подсказки NFS-клиент будет обращаться к NFS-серверу и корректировать свой кэш (пользователь об этом ничего не должен знать).
DSM - виртуальное адресное пространство, разделяемое всеми узлами
(процессорами) распределенной системы. Программы получают доступ к данным в DSM
примерно так же, как они работают с данными в виртуальной памяти традиционных
ЭВМ. В системах с DSM данные перемещаются между локальными памятями разных
компьютеров аналогично тому, как они перемещаются между оперативной и внешней
памятью одного компьютера.
Миграционный алгоритм позволяет интегрировать DSM с виртуальной памятью, обеспечивающейся операционной системой в отдельных узлах. Если размер страницы DSM совпадает с размером страницы виртуальной памяти (или кратен ей), то можно обращаться к разделяемой памяти обычными машинными командами, воспользовавшись аппаратными средствами проверки наличия в оперативной памяти требуемой страницы и замены виртуального адреса на физический. Конечно, для этого виртуальное адресное пространство процессоров должно быть достаточно, чтобы адресовать всю разделяемую память. При этом, несколько процессов в одном узле могут разделять одну и ту же страницу.
Для определения места расположения блоков данных миграционный алгоритм может
использовать сервер, отслеживающий перемещения блоков, либо воспользоваться
механизмом подсказок в каждом узле. Возможна и широковещательная рассылка
запросов.
При использовании такого алгоритма требуется отслеживать расположение всех
блоков данных и их копий. Например, каждый собственник блока может отслеживать
расположение его копий.
Данный алгоритм может снизить среднюю стоимость
доступа по чтению тогда, когда количество чтений значительно превышает
количество записей.
Одним из способов обеспечения консистентности данных является использование специального процесса для упорядочивания модификаций памяти. Все узлы, желающие модифицировать разделяемые данные должны посылать свои модификации этому процессу. Он будет присваивать каждой модификации очередной номер и рассылать его широковещательно вместе с модификацией всем узлам, имеющим копию модифицируемого блока данных. Каждый узел будет осуществлять модификации в порядке возрастания их номеров. Разрыв в номерах полученных модификаций будет означать потерю одной или нескольких модификаций. В этом случае узел может запросить недостающие модификации.
Все перечисленные алгоритмы являются неэффективными. Добиться эффективности
можно только изменив семантику обращений к памяти.
Все однопроцессорные системы обеспечивают строгую консистентность, но в
распределенных многопроцессорных системах ситуация намного сложнее. Предположим,
что переменная X расположена в памяти машины B, и процесс, который выполняется
на машине A, пытается прочитать значение этой переменной в момент времени T1.
Для этого машине B посылается запрос переменной X. Немного позже, в момент
времени T2, процесс, выполняющийся на машине B, производит операцию записи
нового значения в переменную X. Для обеспечения строгой консистентности операция
чтения должна возвратить в машину А старое значение переменной вне зависимости
от того, где расположена машина A и насколько близки между собой два момента
времени T1 и T2. Однако, если T1-T2 равно 1 нсек, и машины расположены друг от
друга на расстоянии 3-х метров, то сигнал о запросе значения переменной должен
быть передан на машину B со скоростью в 10 раз превышающей скорость света, что
невозможно.
| P1: W(x)1 | P1: W(x)1 |
| --------------------------------> t | -----------------------------------> t |
| P2: R(x)1 | P2: R(x)0 R(x)1 |
| а) | б) |
а) Строго консистентная память
б) Память без строгой консистентности
Последовательная консистентность не гарантирует, что операция чтения возвратит значение, записанное другим процессом наносекундой или даже минутой раньше, в этой модели только точно гарантируется, что все процессы знают последовательность всех записей в память. Результат повторного выполнения параллельной программы в системе с последовательной консистентностью (как, впрочем, и при строгой консистентности) может не совпадать с результатом предыдущего выполнения этой же программы, если в программе нет регулирования операций доступа к памяти с помощью механизмов синхронизации.
Два примера правильного выполнения одной программы. В примерах используются следующие обозначения:
| P1: | W(x)1 | W(y)1 | |||
| P2: | W(z)1 | ||||
| P3: | R(x)0 | R(y)0 | R(z)1 | R(y)0 | |
| P4: | R(x)0 | R(y)1 | R(z)1 | R(x)1 |
| P1: | W(x)1 | W(y)1 | |||
| P2: | W(z)1 | ||||
| P3: | R(x)0 | R(y)1 | R(z)0 | R(y)1 | |
| P4: | R(x)1 | R(y)1 | R(z)0 | R(x)1 |
| P1: | W(x)1 | W(y)1 | |||
| P2: | W(z)1 | ||||
| P3: | R(x)0 | R(y)0 | R(z)1 | R(y)0 | |
| P4: | R(x)0 | R(y)1 | R(z)0 | R(x)1 |
| P1: | W(x)1 | W(y)1 | |||
| P2: | W(z)1 | ||||
| P3: | R(x)1 | R(y)0 | R(z)1 | R(y)1 | |
| P4: | R(x)0 | R(y)1 | R(z)1 | R(x)0 |
<>Рассмотрим пример. Предположим, что процесс P1 модифицировал переменную x, затем процесс P2 прочитал x и модифицировал y. В этом случае модификация x и модификация y потенциально причинно зависимы, так как новое значение y могло зависеть от прочитанного значения переменной x. С другой стороны, если два процесса одновременно изменяют значения различных переменных, то между этими событиями нет причинной связи. Операции, которые причинно не зависят друг от друга называются параллельными.
Причинная модель консистентности памяти определяется следующим условием: “Последовательность операций записи, которые потенциально причинно зависимы, должна наблюдаться всеми процессами системы одинаково, параллельные операции записи могут наблюдаться разными узлами в разном порядке.”
Пример.
(а) Нарушение модели причинной
консистентности
| P1: | W(x)1 | ||||
| P2: | R(x)1 | W(x)2 | |||
| P3: | R(x)2 | R(x)1 | |||
| P4: | R(x)1 | R(x)2 |
(б) корректная последовательность для модели причинной консистентности.
| P1: | W(x)1 | W(x)3 | ||||
| P2: | R(x)1 | W(x)2 | ||||
| P3: | R(x)1 | R(x)3 | R(x)2 | |||
| P4: | R(x)1 | R(x)2 | R(X)3 |
При реализации причинной консистентности для случая размножения страниц выполнение операций с общей памятью требует ожидания выполнения только тех предыдущих операций записи, которые являются потенциально причинно зависимыми. Параллельные операции записи не задерживают выполнение операций с общей памятью, а также не требуют неделимости широковещательных рассылок.
Определение потенциальной причинной зависимости может осуществляться компилятором посредством анализа зависимости операторов программы по данным.
Система DSM может это осуществить
посредством нумерации всех записей на каждом процессоре, распространения этих
номеров по всем процессорам вместе с модифицируемыми данными, и задержке любой
модификации на любом процессоре до тех пор, пока он не получит все те
модификации, о которых известно процессору - автору задерживаемой
модификации.
Пример допустимой последовательности
событий в системе с PRAM консистентностью.
| P1: | W(x)1 | ||||
| P2: | R(x)1 | W(x)2 | |||
| P3: | R(x)1 | R(x)2 | |||
| P4: | R(x)2 | R(x)1 |
Преимущество модели PRAM консистентности заключается в простоте ее
реализации, поскольку операции записи на одном процессоре могут быть
конвейеризованы: выполнение операций с общей памятью можно начинать не дожидаясь
завершения предыдущих операций записи (модификации всех копий страниц,
например), необходимо только быть уверенным, что все процессоры увидят эти
записи в одном и том же порядке.
PRAM консистентность может приводить к
результатам, противоречащим интуитивному представлению. Пример:
| Процесс P1 | Процесс P2 |
| .......... | .......... |
| a = 1; | b = 1; |
| if (b==0) kill (P2); | if (a==0) kill (P1); |
| .......... | .......... |
Оба процесса могут быть убиты, что невозможно при последовательной
консистентности.
Модель процессорной консистентности отличается от модели
PRAM консистентности тем, что в ней дополнительно требуется когерентность
памяти: “Для каждой переменной x есть общее согласие относительно порядка, в
котором процессоры модифицируют эту переменную, операции записи в разные
переменные - параллельны”. Таким образом, к упорядочиванию записей каждого
процессора добавляется упорядочивание записей в переменные или группы
Рассмотрим, для примера, процесс, который в критической секции циклически читает и записывает значение некоторых переменных. Даже, если остальные процессоры и не пытаются обращаться к этим переменным до выхода первого процесса из критической секции, для удовлетворения требований описанных выше моделей консистентности они должны “видеть” все записи первого процессора в порядке их выполнения, что, естественно, совершенно не нужно. Наилучшее решение в такой ситуации - это позволить первому процессу завершить выполнение критической секции и, только после этого, переслать остальным процессам значения модифицированных переменных, не заботясь о пересылке промежуточных результатов, и порядка их вычисления внутри критической секции.
Предложенная в 1986 г. (Dubois et al.) модель слабой консистентности, основана на выделении среди переменных специальных синхронизационных переменных и описывается следующими правилами:
Второе правило гарантирует, что выполнение процессором операции обращения к синхронизационной переменной возможно только после “выталкивания” конвейера (полного завершения выполнения на всех процессорах всех предыдущих операций записи переменных, выданных данным процессором). Третье правило определяет, что при обращении к обычным (не синхронизационным) переменным на чтение или запись, все предыдущие обращения к синхронизационным переменным должны быть выполнены полностью. Выполнив синхронизацию перед обращением к общей переменной, процесс может быть уверен, что получит правильное значение этой переменной.
a) Пример допустимой последовательности событий.
| P1: | W(x)1 | W(x)2 | S | |||
| P2: | R(x)1 | R(x)2 | S | |||
| P3: | R(x)2 | R(x)1 | S |
б) Пример недопустимой последовательности событий.
| P1: | W(x)1 | W(x)2 | S | ||
| P2: | S | R(x)1 |
В отличие от предыдущих моделей консистентности, модель слабой
консистентности ориентирована на консистентность групповых операций
чтения/записи. Эта модель наиболее эффективна для приложений, в которых
отдельные (изолированные) обращения к общим переменным встречаются довольно
редко.
В модели консистентности по выходу введены специальные функции обращения к синхронизационным переменным:
(1) ACQUIRE - захват синхронизационной переменной, информирует систему о входе в критическую секцию;
(2) RELEASE - освобождение синхронизационной переменной, определяет завершение критической секции.
Захват и освобождение используется для организации доступа не ко всем общим переменным, а только к тем, которые защищаются данной синхронизационной переменной. Такие общие переменные называют защищенными переменными.
Пример допустимой последовательности событий для модели с консистентностью по
выходу. (Acq(L) - захват синхронизационной переменной L; Rel(L) - освобождение
синхронизационной переменной).
| P1: | Acq(L) | W(x)1 | W(x)2 | Rel(L) | ||||
| P2: | Acq(L) | R(x)2 | Rel(L) | |||||
| P3: | R(x)1 |
Следующие правила определяют требования к модели консистентности по выходу:
При выполнении всех этих требований и использовании методов захвата и освобождения, результат выполнения программы будет таким же, как при выполнении этой программы в системе с последовательной моделью консистентности.
- До выполнения обращения к общей переменной, должны быть полностью выполнены все предыдущие захваты синхронизационных переменных данным процессором.
- Перед освобождением синхронизационной переменной должны быть закончены все операции чтения/записи, выполнявшиеся процессором прежде.
- Реализация операций захвата и освобождения синхронизационной переменной должны удовлетворять требованиям процессорной консистентности (последовательная консистентность не требуется).
Существует модификация консистентности по выходу - “ленивая”. В отличие от
описанной (“энергичной”) консистентности по выходу, она не требует выталкивания
всех модифицированных данных при выходе из критической секции. Вместо этого, при
запросе входа в критическую секцию процессу передаются текущие значения
защищенных разделяемых данных (например, от процесса, который последним
находился в критической секции, охраняемой этой синхронизационной переменной).
При повторных входах в критическую секцию того же самого процесса не требуется
никаких обменов сообщениями.
Кроме того, критические секции, охраняемые одной синхронизационной переменной могут быть двух типов:
(а) Модели консистентности, не использующие операции синхронизации.
| Консистентность | Описание |
| Строгая | Упорядочение всех доступов к разделяемым данным по абсолютному времени |
| Последовательная | Все процессы видят все записи разделяемых данных в одном и том же порядке |
| Причинная | Все процессы видят все причинно-связанные записи данных в одном и том же порядке |
| Процессорная | PRAM-консистентность + когерентность памяти |
| PRAM | Все процессоры видят записи любого процессора в одном и том же порядке |
(б) Модели консистентности с операциями синхронизации.
| Консистентность | Описание |
| Слабая | Разделяемые данные можно считать консистентными только после выполнения синхронизации |
| По выходу | Разделяемые данные становятся консистентными после выхода из критической секции |
| По входу | Связанные с критической секцией разделяемые данные становятся консистентными при входе в нее |
WRITE-UPDATE - организуется обновление копий у всех владельцов.
К этому же типу DSM (не знающих заранее ничего о содержимом памяти) можно
отнести и аппаратные реализации на базе кэшей (Convex SPP).
Знание информации о режиме использования разделяемых переменных позволяет воспользоваться более эффективными протоколами когерентности.
Рассмотрим следующую программу, которая автоматически распараллеливается посредством размножения всех переменных на все процессоры и распределения между ними витков цикла.
s = 0;
izer = 0;
for (i = 1; i < L2-1; i++)
{
r = A[i-1]*A[i+1];
C[i] = r;
s = s + r*r;
if (A[i]==0) { izer = i};
}
A[izer] = 1;
r - приватно (фактически не является разделяемой);
C - раздельно используется (любой элемент массива изменяется не более, чем одним процессом, и никакой процесс не читает элемент, изменяемый другими);
s - редукционная переменная, используемая для суммирования;
izer - переменная, хранящая индекс последнего нулевого элемента массива А;
Приведения в консистентное состояние переменных A и r - не требуется.
Для приведения в консистентное состояние массива С необходимо при завершении цикла каждому процессу послать остальным все свои изменения в массиве С.
Для переменной s в конце цикла надо довыполнить операцию редукции - сложить все частичные суммы, полученные разными процессорами в своих копиях переменной s и разослать результат всем процессорам (если бы начальное значение переменной s было отлично от нуля, то это надо было бы учесть).
Переменной izer на всех процессорах при выходе из цикла должно быть присвоено то значение, которое было получено на витке цикла с максимальным номером (требуется фиксировать на каждом процессоре максимальный номер витка, на котором переменной присваивается значение. При распределении витков последовательными блоками между процессорами достаточно фиксировать сам факт изменения переменной каждым процессором).
Вне цикла приведение в консистентное состояние переменной A[izer] не
требуется, поскольку на каждом процессоре выполняется один и тот же оператор,
который присваивает одно и то же значение всем копиям переменной.
В таких случаях потери эффективности из-за доступа к данным через функции могут быть вполне приемлемыми, поскольку они могут сполна компенсироваться тем выигрышем, который достигается балансировкой загрузки.