Курс лекций
"Параллельная обработка данных"
План лекции
Вектор данных - это упорядоченный набор данных, размещенных в памяти на одинаковом "расстоянии" друг от друга. Примерами векторов в программах могут служить строки, столбцы, диагонали, массивы целиком, в тоже время поддиагональная часть двумерной матрицы вектором не является.
Некоторый фрагмент программы может быть обработан в векторном режиме, если для его выполнения могут быть использованы векторные команды (соответственно полная или частичная векторизация). Поиск таких фрагментов в программе и их замена на векторные команды называется векторизацией программы. Для векторизации необходимы вектора-аргументы + независимые операции над ними. Кандидаты для векторизации - это самые внутренние циклы программы.
Пример. Нужно выполнить независимую обработку всех элементов поддиагональной части массива; в этом случае можем векторизовать по строкам, можем по столбцам, но не можем обработать все данные сразу в векторном режиме из-за нерегулярности расположения элементов поддиагональной части массива в памяти.
Пример векторизуемого фрагмента, для которого выполнены все указанные условия:
Do i=1,n
A(i) = A(i) + s
EndDo
Пример невекторизуемого фрагмента (очередная итерация не может начаться, пока не закончится предыдущая):
Do i=1,n
A(i) = A(i-1)+s
End Do
Do i=1,n
ij = FUNC(i)
A(i) = A(i)+B(ij)
End Do
Do i=1,n
CALL SUBR(A,B)
End Do
Анализ факторов, снижающих реальную производительность компьютеров, начнем с обсуждения известного закона Амдала. Смысл его сводится к тому, что время работы программы определяется ее самой медленной частью. В самом деле, предположим, что одна половина некоторой программы - это сугубо последовательные вычисления. Тогда вне всякой зависимости от свойств другой половины, которая может идеально векторизоваться либо вообще выполняться мгновенно, ускорения работы всей программы более чем в два раза мы не получим.
Влияние данного фактора надо оценивать с двух сторон. Во-первых, по природе самого алгоритма все множество операций программы Г разбивается на последовательные операции Г1 и операции Г2, исполняемые в векторном режиме. Если доля последовательных операций велика, то программист сразу должен быть готов к тому, что большого ускорения он никакими средствами не получит и, быть может, следует уже на этом этапе подумать об изменении алгоритма.
Во-вторых, не следует сбрасывать со счетов и качество компилятора, который может не распознать векторизуемость отдельных конструкций и, тем самым, часть "потенциально хороших" операций из Г2 перенести в Г1.
Прекрасной иллюстрацией к действию закона Амдала могут служить наши эксперименты, которые мы проводили с алгоритмом компактного размещения данных. Задача ставилась следующим образом: l разрядов из каждого элемента массива A(i) надо плотно упаковать по элементам массива B. Если очередная секция из l разрядов целиком не помещается в очередном элементе B(j), то оставшаяся часть должна быть перенесена в следующий элемент B(j+1) (примерная схема данного преобразования показана на рис.1). Общее число элементов массива A было порядка одного миллиона.
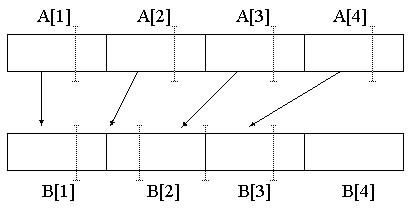
Рис.1 Примерная схема сжатия данных
Первоначально был реализован самый простой алгоритм, который перебирает по очереди все элементы массива A, для каждого выделяет битовую секцию из l разрядов, записывает в соответствующий элемент B(j) и, если необходимо, увеличивает j на единицу, записывая остаток из текущей секции в следующий элемент массива B. Алгоритм в таком виде не мог быть векторизован, выполнялся в скалярном режиме, а значит не мог в принципе получить никакого выигрыша от параллельной структуры компьютера CRAY Y-MP C90.
Немного подумав, нетрудно понять, каким образом можно модифицировать данный алгоритм и сделать его основную часть векторизуемой. Ясно, что, начиная с некоторого номера i0, смещения пакуемых секций всех элементов массива A в массиве B будут повторяться, причем будут повторяться циклически с периодом не более, чем 63 (число разрядов в слове данного компьютера равно 64, но знаковый разряд в каждом элементе B(j) надо было пропускать). Поэтому битовые секции всех элементов A(ibeg+i*63), i=0... для каждого фиксированного значения ibeg=1...63 будут расположены, начиная с одного и того же смещения в элементах массива B, причем эти элементы массива B будут расположены так же с некоторым фиксированным шагом! Становиться понятной общая схема нового алгоритма: упаковку первых 63 элементов делаем как и прежде в скалярном режиме, запоминая смещения в элементах массива B и определяя шаг по этому массиву, а затем в векторном режиме располагаем секции элементов A(ibeg+i*63), i=1... для каждого значения ibeg отдельно. После реализации второго алгоритма оказалось, что время его работы в 30 раз (!) меньше времени работы первого алгоритма. Основная причина очевидна - значительное увеличение доли операций Г2, выполняемых в векторном режиме.
Примерная схема первого варианта (каждая итерация ждет окончания предыдущей для определения смещения в слове массива B):
Примерная схема векторного варианта:
Следующие два фактора, снижающие реальную производительность (они же определяют невозможность достижения пиковой производительности) - секционирование длинных векторных операций на порции по 128 элементов и время начального разгона конвейера, относятся к накладным расходам на организацию векторных операций на конвейерных функциональных устройствах. Временем начального разгона конвейера, в частности, определяется тот факт, что очень короткие циклы выгоднее выполнять не в векторном режиме, а в скалярном, когда этих накладных расходов нет.
В отличие от секционирования операций дополнительное время на разгон конвейера требуется лишь один раз при старте векторной операции. Это стимулирует к работе с длинными векторами данных, так как с ростом длины вектора доля накладных расходов в общем времени выполнения операции быстро падает. Рассмотрим следующий фрагмент программы:
Do i=1,n
a(i)=b(i)*s + c(i)
End Do
В табл.1 показана зависимость производительности компьютера CRAY Y-MP C90 на данном фрагменте от длины вектора, т.е. от значения n (указанные значения производительности здесь и далее могут на практике немного меняться в зависимости от текущей загрузки компьютера и некоторых других факторов - их нужно рассматривать скорее как некоторый ориентир).
вектора | Mflop/s | вектора | Mflop/s |
Табл.1 Производительность CRAY Y-MP C90
Конфликты при обращении в память у компьютеров CRAY Y-MP полностью определяются аппаратными особенностями организации доступа к оперативной памяти. Память компьютеров CRAY Y-MP C90 в максимальной конфигурации разделена на 8 секций, каждая секция - на 8 подсекций, а каждая подсекция на 16 банков памяти. Ясно, что наибольшего времени на разрешение конфликтов потребуется при выборке данных с шагом 8*8=64, когда постоянно совпадают номера и секций и подсекций. С другой стороны, выборка с любым нечетным шагом проходит без конфликтов вообще, и в этом смысле она эквивалентна выборке с шагом единица. Возьмем следующий пример:
Do i=1,n*k,k
a(i)=b(i)*s + c(i)
End Do
В зависимости от значения k, т.е. шага выборки данных из памяти, происходит выполнение векторной операции ai=bi*s+ci длины n в режиме с зацеплением. Производительность компьютера (с двумя секциями памяти) на данной операции показана в таблице 2.
| памяти | производительность на векторах из | ||
| | | ||
Табл.2 Влияние конфликтов при обращении к памяти: производительность компьютера CRAY Y-MP C90
в зависимости от длины векторов и шага перемещения по памяти.
Как видим, производительность падает катастрофически. Однако еще одной неприятной сторой конфликтов является то, что "внешних" причин их появления может быть много (в то время как истинная причина, конечно же, одна - неудачное расположение данных). В самом деле, в предыдущем примере конфликты возникали при использовании цикла с неединичным четным шагом. Значит, казалось бы, не должно быть никаких причин для возникновения конфликтов при работе фрагмента следующего вида:
Do i=1,n
Do j=1,n
Do k=1,n
X(i,j,k) = X(i,j,k)+P(k,i)*Y(k,j)
End Do
End Do
End Do
Однако это не совсем так и все зависит от того, каким образом описан массив X. Предположим, что описание имеет вид:
DIMENSION X(40,40,100)
По определению Фортрана массивы хранятся в памяти "по столбцам", следовательно при изменении последнего индексного выражения на единицу реальное смещение по памяти будет равно произведению размеров массива по предыдущим размерностям. Для нашего примера, расстояние между соседними элементами X(i,j,k) и X(i,j,k+1) равно 40*40=1600=25*64, т.е. всегда кратно наихудшему шагу для выборки из памяти. В тоже время, если изменить лишь описание массива, добавив единицу к первым двум размерностям:
DIMENSION X(41,41,100),
то никаких конфликтов не будет вовсе. Последний пример возможного появления конфликтов - это использование косвенной адресации. В следующем фрагменте
Do j=1,n
Do i=1,n
XYZ(IX(i),j) = XYZ(IX(i),j)+P(i,j)*Y(i,j)
End Do
End Do
в зависимости от того, к каким элементам массива XYZ реально происходит обращение, конфликтов может не быть вовсе (например, IX(i) равно i) либо их число может быть максимальным (например, IX(i) равно одному и тому же значению для всех i).
Следующие два фактора, снижающие производительность, определяются тем, что перед началом выполнения любой операции данные должны быть занесены в регистры. Для этого в архитектуре компьютера CRAY Y-MP предусмотрены три независимых канала передачи данных, два из которых могут работать на чтение из памяти, а третий на запись. Такая структура хорошо подходит для операций, требующих не более двух входных векторов для выполнения в максимально производительном режиме с зацеплением, например, Ai = Bi*s+Ci.
Однако операции с тремя векторными аргументами, как например Ai = Bi*Ci+Di, не могут быть реализованы столь же оптимально. Часть времени будет неизбежно потрачено впустую на ожидание подкачки третьего аргумента для запуска операции с зацеплением, что является прямым следствием ограниченной пропускной способности каналов передачи данных (memory bottleneck). С одной стороны, максимальная производительность достигается на операции с зацеплением, требующей три аргумента, а с другой на чтение одновременно могут работать лишь два канала. В таблице 3 приведена производительность компьютера на указанной выше векторной операции, требующей три входных вектора B, C, D, в зависимости от их длины.
| вектора | Mflop/s |
| | |
Табл.3 Производительность CRAY Y-MP C90
Теперь предположим, что пропускная способность каналов не является узким местом. В этом случае на предварительное занесение данных в регистры все равно требуется некоторое дополнительное время. Поскольку нам необходимо использовать векторные регистры перед выполнением операций, то требуемые для этого операции чтения/записи будут неизбежно снижать общую производительность. Довольно часто влияние данного фактора можо заметно ослабить, если повторно используемые вектора один раз загрузить в регистры, выполнить построенные на их основе выражения, а уже затем перейти к оставшейся части программы. Рассмотрим следующий фрагмент:
Do j=1,120
Do i=1,n
DP(i) = DP(i) + s*P(i,j-1) + t*P(i,j)
End Do
End Do
На каждой итерации по j для выполнения векторной операции требуются три входных вектора DP(i), P(i,j-1), P(i,j) и один выходной - DP(i), следовательно за время работы всего фрагмента будет выполнено 120*3=360 операций чтения векторов и 120 операций записи. Если явно выписать каждые две последовательные итерации цикла по j и преобразовать фрагмент к виду:
Do j=1,120,2
Do i=1,n
DP(i) = DP(i)+s*P(i,j-1)+t*P(i,j)+s*P(i,j)+t*P(i,j+1)
End Do
End Do
то на каждой из 60-ти итераций внешнего цикла потребуется четыре входных вектора DP(i), P(i,j-1), P(i,j), P(i,j+1) и опять же один выходной. Суммарно, для нового варианта будет выполнено 60*4=240 операций чтения и 60 операций записи. Преобразование подобного рода носит название "раскрутки" и имеет максимальный эффект в том случае, когда на соседних итерациях цикла используются одни и те же данные.
Теоретически, одновременно с увеличением глубины раскрутки растет и производительность, приближаясь в пределе к некоторому значению. Однако на практике максимальный эффект достигается где-то на первых шагах, а затем производительность либо остается примерно одинаковой, либо падает. Основная причина данного несоответствия теории и практики заключается в том, что компьютеры CRAY Y-MP C90 имеют сильно ограниченный набор векторных регистров: 8 регистров по 128 слова в каждом. Как правило любая раскрутка требует подкачки дополнительных векторов, а следовательно, и дополнительных регистров. Таблица 4 содержит данные по производительности CRAY Y-MP C90 на обсуждаемом выше фрагменте в зависимости от длины векторов и глубины раскрутки.
| раскрутки | производительность на векторах из | ||
| 64 элементов | 128 элементов | 12800 элементов | |
| 1 | 464.4 | 612.9 | 749.0 |
| 2 | 591.4 | 731.6 | 730.1 |
| 3 | 639.3 | 780.7 | 752.5 |
| 4 | 675.3 | 807.7 | 786.8 |
Теперь вспомним, что значение пиковой производительности вычислялось при условии одновременной работы всех функциональных устройств. Значит если некоторый алгоритм выполняет одинаковое число операций сложения и умножения, но все сложения выполняются сначала и лишь затем операции умножения, то в каждый момент времени в компьютере будут задействованы только устройства одного типа. Присутствующая несбалансированность в использовании функциональных устройств является серьезным фактором, сильно снижающим реальную производительность компьютера - соответствующие данные можно найти в таблице 5.
В наборе функциональных устройств нет устройства деления. Для выполнения данной операции используется устройство обратной аппроксимации и устройство умножения. Отсюда сразу следует, что, во-первых, производительность фрагмента в терминах операций деления будет очень низкой и, во-вторых, использование деления вместе с операцией сложения немного выгоднее, чем с умножением. Конкретные значения производительности показаны в таблице 5.
| длина вектора | производительность на операции | ||||
Табл.5 Производительность CRAY Y-MP C90 на операциях одного типа и операциях с делением.
Если структура программы такова, что в ней либо происходит частое обращение к различным небольшим подпрограммам и функциям, либо структура управления очень запутана и построена на основе большого числа переходов, то потребуется частая перезагрузка буферов команд, а значит возникнут дополнительные накладные расходы. Наилучший результат достигается в том случае, если весь фрагмент кода уместился в одном буфере команд. Незначительные потери производительности будут у фрагментов, расположенных в нескольких буферах. Если же перезагрузка частая, т.е. фрагмент или программа обладают малой локальностью вычислений, то производительность может изменяться в очень широких пределах в зависимости от способа организации каждой конкретной программы.
Что следует из проведенного анализа архитектуры суперкомпьютера CRAY Y-MP C90? Выводов можно сделать много, но главный помогает сразу понять причину низкой производительности неоптимизированных программ, в частности программ, перенесенных с традиционных последовательных компьютеров. Дело в том, что на производительность реальных программ одновременно оказывают влияние в той или иной степени одновременно ВСЕ перечисленные выше факторы. В самом деле, программы не бывают векторизуемыми на все 100% --- всегда есть некоторая инициализация, ввод/вывод или что-то подобное. Вместе с этим обязательно будет присутствовать какое-то число конфликтов в памяти плюс, быть может легкая, несбалансированность в использовании функциональных устройств. Для части операций может не хватать каналов чтения/записи, векторных регистров и т.д. по всем изложенным выше факторам (плюс влияние компилятора -- что-то не векторизовал, что-то сделал не эффективно и т.д.).
Если предположить, что влияние каждого отдельного фактора в некоторой программе таково, что позволяет достичь 85% пиковой производительности, то их суммарное воздействие снизит реальную производительность менее, чем до 20% от пика!
Вывод: если хотим добиться хорошей производительности компьютера, то принимать во внимание необходимо все указанные выше факторы одновременно, минимизируя их суммарное проявление в программе.