|
|
|
Close Help | ||||||||||||||
|
|
|
Close Help | ||||||||||||||
В этой части курса вводятся основные понятия, на которые опирается ОС UNIX, рассматривается общая структура системы и обсуждаются ее основные возможности.
Одним из достоинств ОС UNIX является то, что система базируется на небольшом числе интуитивно ясных понятий. Однако, несмотря на простоту этих понятий, к ним нужно привыкнуть. Без этого невозможно понять существо ОС UNIX.
С самого начала ОС UNIX замышлялась как интерактивная система. Другими словами, UNIX предназначен для терминальной работы. Чтобы начать работать, человек должен "войти" в систему, введя со свободного терминала свое учетное имя (account name) и, возможно, пароль (password). Человек, зарегистрированный в учетных файлах системы, и, следовательно, имеющий учетное имя, называется зарегистрированным пользователем системы. Регистрацию новых пользователей обычно выполняет администратор системы. Пользователь не может изменить свое учетное имя, но может установить и/или изменить свой пароль. Пароли хранятся в отдельном файле в закодированном виде. Не забывайте свой пароль, снова узнать его не поможет даже администратор!
Все пользователи ОС UNIX явно или неявно работают с файлами. Файловая система ОС UNIX имеет древовидную структуру. Промежуточными узлами дерева являются каталоги со ссылками на другие каталоги или файлы, а листья дерева соответствуют файлам или пустым каталогам. Каждому зарегистрированному пользователю соответствует некоторый каталог файловой системы, который называется "домашним" (home) каталогом пользователя. При входе в систему пользователь получает неограниченный доступ к своему домашнему каталогу и всем каталогам и файлам, содержащимся в нем. Пользователь может создавать, удалять и модифицировать каталоги и файлы, содержащиеся в домашнем каталоге. Потенциально возможен доступ и ко всем другим файлам, однако он может быть ограничен, если пользователь не имеет достаточных привилегий.
Традиционный способ взаимодействия пользователя с системой UNIX основывается на использовании командных языков (правда, в настоящее время все большее распространение получают графические интерфейсы). После входа пользователя в систему для него запускается один из командных интерпретаторов (в зависимости от параметров, сохраняемых в файле /etc/passwd). Обычно в системе поддерживается несколько командных интерпретаторов с похожими, но различающимися своими возможностями командными языками. Общее название для любого командного интерпретатора ОС UNIX - shell (оболочка), поскольку любой интерпретатор представляет внешнее окружение ядра системы.
Вызванный командный интерпретатор выдает приглашение на ввод пользователем командной строки, которая может содержать простую команду, конвейер команд или последовательность команд. После выполнения очередной командной строки и выдачи на экран терминала или в файл соответствующих результатов, shell снова выдает приглашение на ввод командной строки, и так до тех пор, пока пользователь не завершит свой сеанс работы путем ввода команды logout или нажатием комбинации клавиш Ctrl-d.
Командные языки, используемые в ОС UNIX, достаточно просты, чтобы новые пользователи могли быстро начать работать, и достаточно мощны, чтобы можно было использовать их для написания сложных программ. Последняя возможность опирается на механизм командных файлов (shell scripts), которые могут содержать произвольные последовательности командных строк. При указании имени командного файла вместо очередной команды интерпретатор читает файл строка за строкой и последовательно интерпретирует команды.
Ядро ОС UNIX идентифицирует каждого пользователя по его идентификатору (UID - User Identifier), уникальному целому значению, присваиваемому пользователю при регистрации в системе. Кроме того, каждый пользователь относится к некоторой группе пользователей, которая также идентифицируется некоторым целым значением (GID - Group IDentifier). Значения UID и GID для каждого зарегистрированного пользователя сохраняются в учетных файлах системы и приписываются процессу, в котором выполняется командный интерпретатор, запущенный при входе пользователя в систему. Эти значения наследуются каждым новым процессом, запущенным от имени данного пользователя, и используются ядром системы для контроля правомощности доступа к файлам, выполнения программ и т.д.
Понятно, что администратор системы, который, естественно, тоже является зарегистрированным пользователем, должен обладать большими возможностями, чем обычные пользователи. В ОС UNIX эта задача решается путем выделения одного значения UID (нулевого). Пользователь с таким UID называется суперпользователем (superuser) или root. Он имеет неограниченные права на доступ к любому файлу и на выполнение любой программы. Кроме того, такой пользователь имеет возможность полного контроля над системой. Он может остановить ее и даже разрушить.
В мире UNIX считается, что человек, получивший статус суперпользователя, должен понимать, что делает. Суперпользователь должен хорошо знать базовые процедуры администрирования ОС UNIX. Он отвечает за безопасность системы, ее правильное конфигурирование, добавление и исключение пользователей, регулярное копирование файлов и т.д.
Еще одним отличием суперпользователя от обычного пользователя ОС UNIX является то, что на суперпользователя не распространяются ограничения на используемые ресурсы. Для обычных пользователей устанавливаются такие ограничения как максимальный размер файла, максимальное число сегментов разделяемой памяти, максимально допустимое пространство на диске и т.д. Суперпользователь может изменять эти ограничения для других пользователей, но на него они не действуют.
ОС UNIX одновременно является операционной средой использования существующих прикладных программ и средой разработки новых приложений. Новые программы могут писаться на разных языках (Фортран, Паскаль, Модула, Ада и др.). Однако стандартным языком программирования в среде ОС UNIX является язык Си (который в последнее время все больше заменяется на Си++). Это объясняется тем, что во-первых, сама система UNIX написана на языке Си, а, во-вторых, язык Си является одним из наиболее качественно стандартизованных языков.
Поэтому программы, написанные на языке Си, при использовании правильного стиля программирования обладают весьма высоким уровнем мобильности, т.е. их можно достаточно просто переносить на другие аппаратные платформы, работающие как под управлением ОС UNIX, так и под управлением ряда других операционных систем (например, DEC Open VMS или MS Windows NT). Более подробно мы рассмотрим принципы мобильного программирования в среде ОС UNIX в четвертой части курса.
Приведем краткий обзор процесса разработки программы на языке Си (или Си++), которую можно выполнить в среде ОС UNIX. Любая выполняемая программа компонуется из одного или нескольких объектных файлов. Поэтому разработка программы начинается с создания исходных файлов, содержащих текст на языке Си. Эти файлы могут содержать определения глобальных имен переменных и/или функций (имен, которые могут быть видимы из других файлов), а также ссылки на внешние имена (объявленные как глобальные в одном из других файлов, которые будут составлять программу).
Текстовые файлы производятся с помощью одного из текстовых редакторов, поддерживаемых в среде UNIX. Традиционным текстовым редактором ОС UNIX является упоминавшийся в первом разделе редактор vi, исходная версия которого была разработана Биллом Джоем. Этот редактор достаточно старый, он может работать практически на всех терминалах и не является в полном смысле оконным.
В последние годы все большую популярность получает редактор Emacs (разработанный и непрерывно совершенствуемый президентом Free Software Foundation Ричардом Столлманом). Это очень мощный многооконный редактор, который позволяет не только писать программы (и другие тексты), но также и компилировать, компоновать и отлаживать программы (а также делать многое другое, например, принимать и отправлять электронную почту). Основным недостатком редактора Emacs является исключительно большой набор (более 200) функциональных клавиш. Следует, правда, заметить, что при использовании Emacs в оконной системе X он обеспечивает более удобный интерфейс.
Заметим также, что многие неудобства интерфейсов традиционных инструментальных средств ОС UNIX связаны с тем, что они ориентированы на использование и алфавитно-цифровых, и графических терминалов. Поэтому обычно эти средства поддерживают старомодный строчный интерфейс даже при наличии графического терминала. Естественно, в современных вариантах ОС UNIX все новые инструментальные средства поддерживают оконный графический интерфейс (и, следовательно, их невозможно использовать при наличии алфавитно-цифровых терминалов).
После того, как текстовый файл создан, его нужно откомпилировать для получения объектного файла. Наиболее популярными компиляторами для языка Си в среде ОС UNIX сейчас являются pcc (Ритчи и Томпсон) и gcc (Ричард Столлман). Оба эти компилятора являются полностью мобильными и обладают возможностью генерировать код для разнообразных компьютеров, т.е. эти компиляторы могут быть установлены практически на любой аппаратной платформе под управлением ОС UNIX.
Можно отметить следующие преимущества gcc. Во-первых, этот компилятор свободно, т.е. бесплатно (вместе со своими исходными текстами) распространяется Free Software Foundation. Во-вторых, gcc тщательно поддерживается и сопровождается. В-третьих, начиная с версии 2.0, gcc может компилировать программы, написанные на языках Си, Си++ и Objective C, а результирующая выполняемая программа может быть скомпонована из объектных файлов, полученных из текстовых файлов на любом из этих языков. В-четвертых, открытость исходных текстов gcc и тщательно разработанная структура компилятора позволяют сравнительно просто добавлять к gcc новые кодогенераторы. Относительным недостатком gcc является то, что используемый диалект языка Си включает слишком много расширений по сравнению со стандартом ANSI/ISO (однако имеется режим, в котором компилятор указывает все расширенные конструкции языка, встречающиеся в компилируемой программе).
Оба компилятора обрабатывают программу в два этапа. На первом этапе синтаксически правильный текст на языке Си преобразуется в текст на языке ассемблера. На втором этапе на основе текста на языке ассемблера генерируются машинные коды и получается объектный файл. Исторически в ОС UNIX использовались различные форматы объектных модулей. Для обеспечения совместимости с предыдущими версиями почти все они поддерживаются в современных версиях компиляторов. Однако в настоящее время преимущественно используется формат COFF (Common Object File Format). При желании можно остановить процесс компиляции после первого этапа и получить для изучения файл с текстом программы на языке ассемблера.
После того, как необходимый для построения выполняемой программы набор объектных файлов получен, необходимо произвести компоновку выполняемой программы. В ОС UNIX компоновщик выполняемых программ называется редактором связей (link editor) и обычно вызывается командой ld. Редактору связей указывается набор объектных файлов и набор библиотек, из которых нужно черпать недостающие для компоновки программы.
Процесс компоновки заключается в следующем. Сначала просматривается набор заданных объектных файлов. Для каждого внешнего имени ищется объектный файл, содержащий определение такого же глобального имени. Если поиск заканчивается успешно, то внешняя ссылка заменяется на ссылку на определение глобального имени. Если в конце этого этапа остаются внешние имена, для которых не удалось найти соответствующего определения глобального имени, то начинается поиск объектных файлов с нужными определениями глобальных имен в указанных библиотеках. Если, в конце концов, удается найти определения для всех внешних имен, все соответствующие объектные файлы собираются вместе и образуют выполняемый файл.
В ОС UNIX имеется несколько стандартных библиотек. В большинстве случаев наиболее важной является библиотека ввода/вывода (stdio). Грамотное использование стандартных библиотек способствует созданию легко переносимых прикладных программ (мы вернемся к обсуждению стандартных библиотек ОС UNIX в четвертой части курса).
Выполняемая программа может быть запущена в интерактивном режиме как команда shell или выполнена в отдельном процессе, образуемом уже запущенной программой.
Любой командный язык семейства shell фактически состоит из трех частей: служебных конструкций, позволяющих манипулировать с текстовыми строками и строить сложные команды на основе простых команд; встроенных команд, выполняемых непосредственно интерпретатором командного языка; команд, представляемых отдельными выполняемыми файлами (более подробно и точно командные языки рассматриваются в пятой части курса).
В свою очередь, набор команд последнего вида включает стандартные команды (системные утилиты, такие как vi, cc и т.д.) и команды, созданные пользователями системы. Для того, чтобы выполняемый файл, разработанный пользователем ОС UNIX, можно было запускать как команду shell, достаточно определить в одном из исходных файлов функцию с именем main (имя main должно быть глобальным, т.е. перед ним не должно указываться ключевое слово static). Если употребить в качестве имени команды имя такого выполняемого файла, командный интерпретатор создаст новый процесс (см. следующий подраздел) и запустит в нем указанную выполняемую программу начиная с вызова функции main.
Тело функции main, вообще говоря, может быть произвольным (для интерпретатора существенно только наличие входной точки в программу с именем main), но для того, чтобы создать команду, которой можно задавать параметры, нужно придерживаться некоторых стандартных правил. В этом случае каждая функция main должна определяться с двумя параметрами - argc и argv. После вызова команды параметру argc будет соответствовать число символьных строк, указанных в качестве аргументов вызова команды, а argv - массив указателей на переменные, содержащие эти строки. При этом имя самой команды составляет первую строку аргументов (т.е. после вызова значение argc всегда больше или равно 1). Код функции main должен проанализировать допустимость заданного значения argc и соответствующим образом обработать заданные текстовые строки.
Например, следующий текст на языке Си может быть использован для создании команды, которая выводит на экран текстовую строку, заданную в качестве ее аргумента:
#include <stdio.h>
main (argc, argv)
int argc;
char *argv[];
{
if (argc != 2)
{ printf("usage: %s your-text\n", argv[0]);
exit;
}
printf("%s\n", argv[1]);
}
Процесс в ОС UNIX - это программа, выполняемая в собственном виртуальном адресном пространстве. Когда пользователь входит в систему, автоматически создается процесс, в котором выполняется программа командного интерпретатора. Если командному интерпретатору встречается команда, соответствующая выполняемому файлу, то он создает новый процесс и запускает в нем соответствующую программу, начиная с функции main. Эта запущенная программа, в свою очередь, может создать процесс и запустить в нем другую программу (она тоже должна содержать функцию main) и т.д.
Управление процессами подробно обсуждается в третьей части курса. Тем не менее кратко опишем здесь общий подход. Для образования нового процесса и запуска в нем программы используются два системных вызова (примитива ядра ОС UNIX) - fork() и exec (имя-выполняемого-файла). Системный вызов fork приводит к созданию нового адресного пространства, состояние которого абсолютно идентично состоянию адресного пространства основного процесса (т.е. в нем содержатся те же программы и данные).
Другими словами, сразу после выполнения системного вызова fork основной и порожденный процессы являются абсолютными близнецами; управление и в том, и в другом находится в точке, непосредственно следующей за вызовом fork. Чтобы программа могла разобраться, в каком процессе она теперь работает - в основном или порожденном, функция fork возвращает разные значения: 0 в порожденном процессе и целое положительное число (идентификатор порожденного процесса) в основном процессе.
Теперь, если мы хотим запустить новую программу в порожденном процессе, нужно обратиться к системному вызову exec, указав в качестве аргументов вызова имя файла, содержащего новую выполняемую программу, и, возможно, одну или несколько текстовых строк, которые будут переданы в качестве аргументов функции main новой программы. Выполнение системного вызова exec приводит к тому, что в адресное пространство порожденного процесса загружается новая выполняемая программа и запускается с адреса, соответствующего входу в функцию main.
В следующем примере пользовательская программа, вызываемая как команда shell, выполняет в отдельном процессе стандартную команду shell ls, которая выдает на экран содержимое текущего каталога файлов.
main()
{if(fork()==0) wait(0); /* родительский процесс */
else execl("ls", "ls", 0); /* порожденный процесс */
}
Механизм перенаправления ввода/вывода является одним из наиболее элегантных, мощных и одновременно простых механизмов ОС UNIX. Цель, которая ставилась при разработке этого механизма, состоит в следующем. Поскольку UNIX - это интерактивная система, то обычно программы вводят текстовые строки с терминала и выводят результирующие текстовые строки на экран терминала. Для того, чтобы обеспечить более гибкое использование таких программ, желательно уметь обеспечить им ввод из файла или из вывода других программ и направить их вывод в файл или на ввод другим программам.
Реализация механизма основывается на следующих свойствах ОС UNIX. Во-первых, любой ввод/вывод трактуется как ввод из некоторого файла и вывод в некоторый файл. Клавиатура и экран терминала тоже интерпретируются как файлы (первый можно только читать, а во второй можно только писать). Во-вторых, доступ к любому файлу производится через его дескриптор (положительное целое число). Фиксируются три значения дескрипторов файлов. Файл с дескриптором 1 называется файлом стандартного ввода (stdin), файл с дескриптором 2 - файлом стандартного вывода (stdout), и файл с дескриптором 3 - файлом стандартного вывода диагностических сообщений (stderr). В-третьих, программа, запущенная в некотором процессе, "наследует" от породившего процесса все дескрипторы открытых файлов.
В головном процессе интерпретатора командного языка файлом стандартного ввода является клавиатура терминала пользователя, а файлами стандартного вывода и вывода диагностических сообщений - экран терминала. Однако при запуске любой команды можно сообщить интерпретатору (средствами соответствующего командного языка), какой файл или вывод какой программы должен служить файлом стандартного ввода для запускаемой программы и какой файл или ввод какой программы должен служить файлом стандартного вывода или вывода диагностических сообщений для запускаемой программы. Тогда интерпретатор перед выполнением системного вызова exec открывает указанные файлы, подменяя смысл дескрипторов 1, 2 и 3.
Конечно, то же самое может проделать и любая другая программа, запускающая третью программу в специально созданном процессе. Следовательно, все, что требуется для нормального функционирования механизма перенаправления ввода/вывода - это придерживаться при программировании соглашения об использовании дескрипторов stdin, stdout и stderr. Это не очень трудно, поскольку в наиболее распространенных функциях библиотеки ввода/вывода printf, scanf и error вообще не требуется указывать дескриптор файла. Функция printf неявно использует stdout, функция scanf - stdin, а функция error - stderr.
Более подробно механизм перенаправления вывода одной программы на ввод другой программы будет рассмотрен в третьей части курса.
Как и в любой другой многопользовательской операционной системе, обеспечивающей защиту пользователей друг от друга и защиту системных данных от любого непривилегированного пользователя, в ОС UNIX имеется защищенное ядро, которое управляет ресурсами компьютера и предоставляет пользователям базовый набор услуг.
Следует заметить, что удобство и эффективность современных вариантов ОС UNIX не означает, что вся система, включая ядро, спроектирована и структуризована наилучшим образом. Как мы показали в первой части курса, ОС UNIX развивалась на протяжении многих лет (это первая в истории операционная система, которая продолжает завоевывать популярность в таком зрелом возрасте - уже больше 25 лет). Естественно, наращивались возможности системы, и, как это часто бывает в больших системах, качественные улучшения структуры ОС UNIX не поспевали за ростом ее возможностей.
В результате, ядро большинства современных коммерческих вариантов ОС UNIX (как мы отмечали ранее, почти все они основаны на UNIX System V) представляет собой не очень четко структуризованный монолит большого размера. По этой причине программирование на уровне ядра ОС UNIX продолжает оставаться искусством (если не считать отработанной и понятной технологии разработки драйверов внешних устройств). Эта недостаточная технологичность организации ядра ОС UNIX многих не удовлетворяет. Отсюда стремление к полному воспроизведению среды ОС UNIX при полностью иной организации системы (в частности, с применением микроядерного подхода, который мы кратко рассмотрим в конце курса).
По причине наибольшей распространенности в этом подразделе мы в основном обсуждаем ядро UNIX System V (можно считать его традиционным). В конце курса мы обсудим отличия в организации ядра других ветвей иерархии вариантов ОС UNIX.
Одно из основных достижений ОС UNIX состоит в том, что система обладает свойством высокой мобильности. Смысл этого качества состоит в том, что вся операционная система, включая ее ядро, сравнительно просто переносится на различные аппаратные платформы. Все части системы, не считая ядра, являются полностью машинно-независимыми. Эти компоненты аккуратно написаны на языке Си, и для их переноса на новую платформу (по крайней мере, в классе 32-разрядных компьютеров) требуется только перекомпиляция исходных текстов в коды целевого компьютера.
Конечно, наибольшие проблемы связаны с ядром системы, которое полностью скрывает специфику используемого компьютера, но само зависит от этой специфики. В результате продуманного разделения машинно-зависимых и машинно-независимых компонентов ядра (видимо, с точки зрения разработчиков операционных систем, в этом состоит наивысшее достижение разработчиков традиционного ядра ОС UNIX) удалось добиться того, что основная часть ядра не зависит от архитектурных особенностей целевой платформы, написана полностью на языке Си и для переноса на новую платформу нуждается только в перекомпиляции.
Однако сравнительно небольшая часть ядра является машинно-зависимой и написана на смеси языка Си и языка ассемблера целевого процессора. При переносе системы на новую платформу требуется переписывание этой части ядра с использованием языка ассемблера и учетом специфических черт целевой аппаратуры. Машинно-зависимые части ядра хорошо изолированы от основной машинно-независимой части, и при хорошем понимании назначения каждого машинно-зависимого компонента переписывание машинно-зависимой части является в основном технической задачей (хотя и требует высокой программистской квалификации).
Машинно-зависимая часть традиционного ядра ОС UNIX включает следующие компоненты:
К основным функциям ядра ОС UNIX принято относить следующие:
(a) Инициализация системы - функция запуска и раскрутки. Ядро системы обеспечивает средство раскрутки (bootstrap), которое обеспечивает загрузку полного ядра в память компьютера и запускает ядро.
(b) Управление процессами и нитями - функция создания, завершения и отслеживания существующих процессов и нитей ("процессов", выполняемых на общей виртуальной памяти). Поскольку ОС UNIX является мультипроцессной операционной системой, ядро обеспечивает разделение между запущенными процессами времени процессора (или процессоров в мультипроцессорных системах) и других ресурсов компьютера для создания внешнего ощущения того, что процессы реально выполняются в параллель.
(c) Управление памятью - функция отображения практически неограниченной виртуальной памяти процессов в физическую оперативную память компьютера, которая имеет ограниченные размеры. Соответствующий компонент ядра обеспечивает разделяемое использование одних и тех же областей оперативной памяти несколькими процессами с использованием внешней памяти.
(d) Управление файлами - функция, реализующая абстракцию файловой системы, - иерархии каталогов и файлов. Файловые системы ОС UNIX поддерживают несколько типов файлов. Некоторые файлы могут содержать данные в формате ASCII, другие будут соответствовать внешним устройствам. В файловой системе хранятся объектные файлы, выполняемые файлы и т.д. Файлы обычно хранятся на устройствах внешней памяти; доступ к ним обеспечивается средствами ядра. В мире UNIX существует несколько типов организации файловых систем. Современные варианты ОС UNIX одновременно поддерживают большинство типов файловых систем.
(e) Коммуникационные средства - функция, обеспечивающая возможности обмена данными между процессами, выполняющимися внутри одного компьютера (IPC - Inter-Process Communications), между процессами, выполняющимися в разных узлах локальной или глобальной сети передачи данных, а также между процессами и драйверами внешних устройств.
(f) Программный интерфейс - функция, обеспечивающая доступ к возможностям ядра со стороны пользовательских процессов на основе механизма системных вызовов, оформленных в виде библиотеки функций.
В следующих разделах этой части курса и, более подробно, в третьей части курса мы будем знакомиться с базовыми возможностями ядра ОС UNIX.
В любой операционной системе поддерживается некоторый механизм, который позволяет пользовательским программам обращаться за услугами ядра ОС. В операционных системах наиболее известной советской вычислительной машины БЭСМ-6 соответствующие средства общения с ядром назывались экстракодами, в операционных системах IBM они назывались системными макрокомандами и т.д. В ОС UNIX такие средства называются системными вызовами.
Название не изменяет смысл, который состоит в том, что для обращения к функциям ядра ОС используются "специальные команды" процессора, при выполнении которых возникает особого рода внутреннее прерывание процессора, переводящее его в режим ядра (в большинстве современных ОС этот вид прерываний называется trap - ловушка). При обработке таких прерываний (дешифрации) ядро ОС распознает, что на самом деле прерывание является запросом к ядру со стороны пользовательской программы на выполнение определенных действий, выбирает параметры обращения и обрабатывает его, после чего выполняет "возврат из прерывания", возобновляя нормальное выполнение пользовательской программы.
Понятно, что конкретные механизмы возбуждения внутренних прерываний по инициативе пользовательской программы различаются в разных аппаратных архитектурах. Поскольку ОС UNIX стремится обеспечить среду, в которой пользовательские программы могли бы быть полностью мобильны, потребовался дополнительный уровень, скрывающий особенности конкретного механизма возбуждения внутренних прерываний. Этот механизм обеспечивается так называемой библиотекой системных вызовов.
Для пользователя библиотека системных вызовов представляет собой обычную библиотеку заранее реализованных функций системы программирования языка Си. При программировании на языке Си использование любой функции из библиотеки системных вызовов ничем не отличается от использования любой собственной или библиотечной Си-функции. Однако внутри любой функции конкретной библиотеки системных вызовов содержится код, являющийся, вообще говоря, специфичным для данной аппаратной платформы.
Наиболее важные системные вызовы ОС UNIX рассматриваются в оставшихся разделах этой части курса и в следующей части.
Конечно, применяемый в операционных системах механизм обработки внутренних и внешних прерываний в основном зависит от того, какая аппаратная поддержка обработки прерываний обеспечивается конкретной аппаратной платформой. К счастью, к настоящему моменту (и уже довольно давно) основные производители компьютеров де-факто пришли к соглашению о базовых механизмах прерываний.
Если говорить не очень точно и конкретно, суть принятого на сегодня механизма состоит в том, что каждому возможному прерыванию процессора (будь то внутреннее или внешнее прерывание) соответствует некоторый фиксированный адрес физической оперативной памяти. В тот момент, когда процессору разрешается прерваться по причине наличия внутренней или внешней заявки на прерывание, происходит аппаратная передача управления на ячейку физической оперативной памяти с соответствующим адресом - обычно адрес этой ячейки называется "вектором прерывания" (как правило, заявки на внутреннее прерывание, т.е. заявки, поступающие непосредственно от процессора, удовлетворяются немедленно).
Дело операционной системы - разместить в соответствующих ячейках оперативной памяти программный код, обеспечивающий начальную обработку прерывания и инициирующий полную обработку.
В основном, ОС UNIX придерживается общего подхода. В векторе прерывания, соответствующем внешнему прерыванию, т.е. прерыванию от некоторого внешнего устройства, содержатся команды, устанавливающие уровень выполнения процессора (уровень выполнения определяет, на какие внешние прерывания процессор должен реагировать незамедлительно) и осуществляющие переход на программу полной обработки прерывания в соответствующем драйвере устройства. Для внутреннего прерывания (например, прерывания по инициативе программы пользователя при отсутствии в основной памяти нужной страницы виртуальной памяти, при возникновении исключительной ситуации в программе пользователя и т.д.) или прерывания от таймера в векторе прерывания содержится переход на соответствующую программу ядра ОС UNIX.
Как мы отмечали в разделе 2.1, понятие файла является одним из наиболее важных для ОС UNIX. Все файлы, с которыми могут манипулировать пользователи, располагаются в файловой системе, представляющей собой дерево, промежуточные вершины которого соответствуют каталогам, и листья - файлам и пустым каталогам. Примерная структура файловой системы ОС UNIX показана на рисунке 2.1. Реально на каждом логическом диске (разделе физического дискового пакета) располагается отдельная иерархия каталогов и файлов. Для получения общего дерева в динамике используется "монтирование" отдельных иерархий к фиксированной корневой файловой системе.
Замечание: в мире ОС UNIX по историческим причинам термин "файловая система" является перегруженным, обозначая одновременно иерархию каталогов и файлов и часть ядра, которая управляет каталогами и файлами. Видимо, было бы правильнее называть иерархию каталогов и файлов архивом файлов, а термин "файловая система" использовать только во втором смысле. Однако, следуя традиции ОС UNIX, мы будем использовать этот термин в двух смыслах, различая значения по контексту.
Каждый каталог и файл файловой системы имеет уникальное полное имя (в ОС UNIX это имя принято называть full pathname - имя, задающее полный путь, поскольку оно действительно задает полный путь от корня файловой системы через цепочку каталогов к соответствующему каталогу или файлу; мы будем использовать термин "полное имя", поскольку для pathname отсутствует благозвучный русский аналог). Каталог, являющийся корнем файловой системы (корневой каталог), в любой файловой системе имеет предопределенное имя "/" (слэш). Полное имя файла, например, /bin/sh означает, что в корневом каталоге должно содержаться имя каталога bin, а в каталоге bin должно содержаться имя файла sh. Коротким или относительным именем файла (relative pathname) называется имя (возможно, составное), задающее путь к файлу от текущего рабочего каталога (существует команда и соответствующий системный вызов, позволяющие установить текущий рабочий каталог).
В каждом каталоге содержатся два специальных имени, имя ".", именующее сам этот каталог, и имя "..", именующее "родительский" каталог данного каталога, т.е. каталог, непосредственно предшествующий данному в иерархии каталогов.
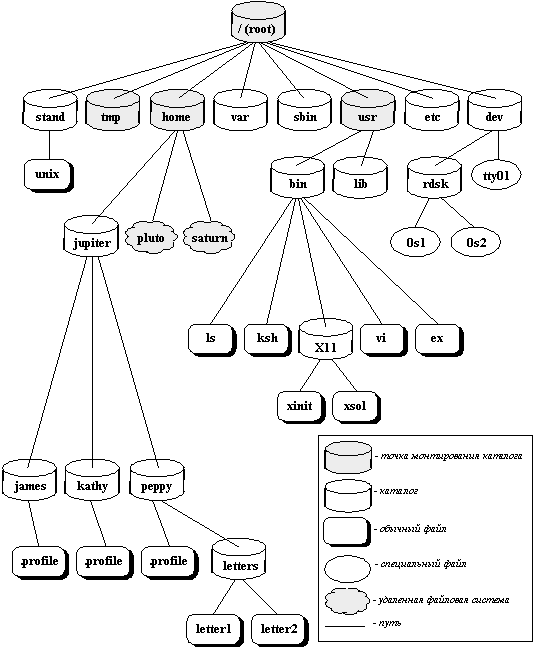
Рис. 2.1. Структура каталогов файловой системы
UNIX поддерживает многочисленные утилиты, позволяющие работать с файловой системой и доступные как команды командного интерпретатора. Вот некоторые из них (наиболее употребительные):
| cp имя1 имя2 | - копирование файла имя1 в файл имя2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| rm имя1 | - уничтожение файла имя1 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| mv имя1 имя2 | - переименование файла имя1 в файл имя2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| mkdir имя | - создание нового каталога имя | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| rmdir имя | - уничтожение каталога имя | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ls имя | - выдача содержимого каталога имя | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| cat имя | - выдача на экран содержимого файла имя | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| chown имя режим | - изменение режима доступа к файлу | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Файловая система обычно размещается на дисках или других устройствах внешней памяти, имеющих блочную структуру. Кроме блоков, сохраняющих каталоги и файлы, во внешней памяти поддерживается еще несколько служебных областей.
В мире UNIX существует несколько разных видов файловых систем со своей структурой внешней памяти. Наиболее известны традиционная файловая система UNIX System V (s5) и файловая система семейства UNIX BSD (ufs). Файловая система s5 состоит из четырех секций (рисунок 2.2,a). В файловой системе ufs на логическом диске (разделе реального диска) находится последовательность секций файловой системы (рисунок 2.2,b).
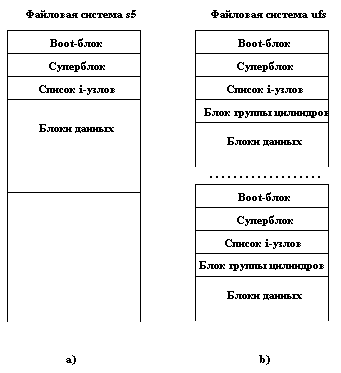
Рис. 2.2. Структура внешней памяти файловых систем s5 и ufs
Кратко опишем суть и назначение каждой области диска.
Файлы любой файловой системы становятся доступными только после "монтирования" этой файловой системы. Файлы "не смонтированной" файловой системы не являются видимыми операционной системой.
Для монтирования файловой системы используется системный вызов mount. Монтирование файловой системы означает следующее. В имеющемся к моменту монтирования дереве каталогов и файлов должен иметься листовой узел - пустой каталог (в терминологии UNIX такой каталог, используемый для монтирования файловой системы, называется directory mount point - точка монтирования). В любой файловой системе имеется корневой каталог. Во время выполнения системного вызова mount корневой каталог монтируемой файловой системы совмещается с каталогом - точкой монтирования, в результате чего образуется новая иерархия с полными именами каталогов и файлов.
Смонтированная файловая система впоследствии может быть отсоединена от общей иерархии с использованием системного вызова umount. Для успешного выполнения этого системного вызова требуется, чтобы отсоединяемая файловая система к этому моменту не находилась в использовании (т.е. ни один файл из этой файловой системы не был открыт). Корневая файловая система всегда является смонтированной, и к ней не применим системный вызов umount.
Как мы отмечали выше, отдельная файловая система обычно располагается на логическом диске, т.е. на разделе физического диска. Для инициализации файловой системы не поддерживаются какие-либо специальные системные вызовы. Новая файловая система образуется на отформатированном диске с использованием утилиты (команды) mkfs. Вновь созданная файловая система инициализируется в состояние, соответствующее наличию всего лишь одного пустого корневого каталога. Команда mkfs выполняет инициализацию путем прямой записи соответствующих данных на диск.
Ядро ОС UNIX поддерживает для работы с файлами несколько системных вызовов. Среди них наиболее важными являются open, creat, read, write, lseek и close.
Важно отметить, что хотя внутри подсистемы управления файлами обычный файл представляется в виде набора блоков внешней памяти, для пользователей обеспечивается представление файла в виде линейной последовательности байтов. Такое представление позволяет использовать абстракцию файла при работе в внешними устройствами, при организации межпроцессных взаимодействий и т.д.
Файл в системных вызовах, обеспечивающих реальный доступ к данным, идентифицируется своим дескриптором (целым значением). Дескриптор файла выдается системными вызовами open (открыть файл) и creat (создать файл). Основным параметром операций открытия и создания файла является полное или относительное имя файла. Кроме того, при открытии файла указывается также режим открытия (только чтение, только запись, запись и чтение и т.д.) и характеристика, определяющая возможности доступа к файлу:
open(pathname, oflag [,mode])
Одним из признаков, которые могут участвовать в параметре oflag, является признак O_CREAT, наличие которого указывает на необходимость создания файла, если при выполнении системного вызова open файл с указанным именем не существует (параметр mode имеет смысл только при наличии этого признака). Тем не менее по историческим причинам и для обеспечения совместимости с предыдущими версиями ОС UNIX отдельно поддерживается системный вызов creat, выполняющий практически те же функции.
Открытый файл может использоваться для чтения и записи последовательностей байтов. Для этого поддерживаются два системных вызова:
read(fd, buffer, count) и write(fd, buffer, count)
Здесь fd - дескриптор файла (полученный при ранее выполненном системном вызове open или creat), buffer - указатель символьного массива и count - число байтов, которые должны быть прочитаны из файла или в него записаны. Значение функции read или write - целое число, которое совпадает со значением count, если операция заканчивается успешно, равно нулю при достижении конца файла и отрицательно при возникновении ошибок.
В каждом открытом файле существует текущая позиция. Сразу после открытия файл позиционируется на первый байт. Другими словами, если сразу после открытия файла выполняется системный вызов read (или write), то будут прочитаны (или записаны) первые count байтов содержимого файла (конечно, они будут успешно прочитаны только в том случае, если файл реально содержит по крайней мере count байтов). После выполнения системного вызова read (или write) указатель чтения/записи файла будет установлен в позицию count+1 и т.д.
Такой, чисто последовательный стиль работы, оказывается во многих случаях достаточным, но часто бывает необходимо читать или изменять файл с произвольной позиции (например, как без такой возможности хранить в файле прямо индексируемые массивы данных?). Для явного позиционирования файла служит системный вызов
lseek(fd, offset, origin)
Как и раньше, здесь fd - дескриптор ранее открытого файла. Параметр offset задает значение относительного смещения указателя чтения/записи, а параметр origin указывает, относительно какой позиции должно применяться смещение. Возможны три значения параметра origin. Значение 0 указывает, что значение offset должно рассматриваться как смещение относительно начала файла. Значение 1 означает, что значение offset является смещением относительно текущей позиции файла. Наконец, значение 2 говорит о том, что задается смещение относительно конца файла. Заметим, что типом данных параметра offset является long int. Это значит, что, во-первых, могут задаваться достаточно длинные смещения и, во-вторых, смещения могут быть положительными и отрицательными.
Например, после выполнения системного вызова
lseek(fd, 0, 0)
указатель чтения/записи соответствующего файла будет установлен на начало (на первый байт) файла. Системный вызов
lseek(fd, 0, 2)
установит указатель на конец файла. Наконец, выполнение системного вызова
lseek(fd, 10, 1)
приведет к увеличению текущего значения указателя на 10.
Естественно, системный вызов успешно завершается только в том случае, когда заново сформированное значение указателя не выходит за пределы существующих размеров файла.
Как мы неоднократно отмечали, в ОС UNIX понятие файла является универсальной абстракцией, позволяющей работать с обычными файлами, содержащимися на устройствах внешней памяти; с устройствами, вообще говоря, отличающимися от устройств внешней памяти; с информацией, динамически генерируемой другими процессами и т.д. Для поддержки этих возможностей единообразным способом файловые системы ОС UNIX поддерживают несколько типов файлов, наиболее существенные из которых мы рассмотрим в этом разделе.
Обычные (или регулярные) файлы реально представляют собой набор блоков (возможно, пустой) на устройстве внешней памяти, на котором поддерживается файловая система. Такие файлы могут содержать как текстовую информацию (обычно в формате ASCII), так и произвольную двоичную информацию. Файловая система не предписывает обычным файлам какую-либо структуру, обеспечивая на уровне пользователей представление обычного файла как последовательности байтов. Используя базовые системные вызовы (или функции библиотеки ввода/вывода, которые мы рассмотрим в разделе 4), пользователи могут как угодно структуризовать файлы. В частности, многие СУБД хранят базы данных в обычных файлах ОС UNIX.
Для некоторых файлов, которые должны интерпретироваться компонентами самой операционной системы, UNIX поддерживает фиксированную структуру. Наиболее важным примером таких файлов являются объектные и выполняемые файлы. Структура этих файлов поддерживается компиляторами, редакторами связей и загрузчиком. Однако, эта структура неизвестна файловой системе. Для нее такие файлы по-прежнему являются обычными файлами.
Наличие обычных файлов недостаточно для организации иерархических файловых систем. Требуется наличие каталогов, которые сопоставляют имена файлов или каталогов с их физическим описанием. Каталоги представляют собой особый вид файлов, которые хранятся во внешней памяти подобно обычным файлам, но структура которых поддерживается самой файловой системой.
Структура файла-каталога очень проста. Фактически, каталог - это таблица, каждый элемент которой состоит из двух полей: номера i-узла данного файла в его файловой системе и имени файла, которое связано с этим номером (конечно, этот файл может быть и каталогом). Если просмотреть содержимое текущего рабочего каталога с помощью команды ls -ai, то можно получить, например, следующий вывод:
inode File
number name
_________________________
33 .
122 ..
54 first_file
65 second_file
65 second_again
77 dir2
Этот вывод демонстрирует, что в любом каталоге содержатся два стандартных имени - "." и "..". Имени "." сопоставляется i-узел, соответствующий самому этому каталогу, а имени ".." - i-узел, соответствующий "родительскому" каталогу данного каталога. "Родительским" (parent) каталогом называется каталог, в котором содержится имя данного каталога. Файлы с именами "first_file" и "second_file" - это разные файлы с номерами i-узлов 54 и 65 соответственно. Файл "second_again" представляет пример так называемой жесткой ссылки: он имеет другое имя, но реально описывается тем же i-узлом, что и файл "second_file". Наконец, последний элемент каталога описывает некоторый другой каталог с именем "dir2".
Этот последний файл, как и любой обычный файл, хранится в файловой системе как набор блоков запоминающего устройства. Однако файловая система знает, что на самом деле это каталог со структурой, контролируемой файловой системой. Поэтому файлам-каталогам соответствует особый тип файла (обозначенный в их i-узлах), по отношению к которому возможно выполнение только специального набора системных вызовов:
mkdir, производящего новый каталог,
rmdir, удаляющий пустой (незаполненный) каталог,
getdents, позволяющего прочитать содержимое указанного каталога.
Отсутствует системный вызов, позволяющий прямо писать в файл-каталог. Какими бы правами вы не обладали по отношению к файлу-каталогу, прямая запись информации в него запрещена - прямое следствие фиксированной (и закрытой от пользователей) структуры файлов-каталогов. Запись в файлы-каталоги производится неявно при создании и уничтожении файлов и каталогов, однако читать из файла-каталога при наличии соответствующих прав можно (пример - стандартная утилита ls, которая как раз и пользуется системным вызовом getdents).
Специальные файлы не хранят данные. Они обеспечивают механизм отображения физических внешних устройств в имена файлов файловой системы. Каждому устройству, поддерживаемому системой, соответствует, по меньшей мере, один специальный файл. Специальные файлы создаются при выполнении системного вызова mknod, каждому специальному файлу соответствует порция программного обеспечения, называемая драйвером соответствующего устройства. При выполнении чтения или записи по отношению к специальному файлу, производится прямой вызов соответствующего драйвера, программный код которого отвечает за передачу данных между процессом пользователя и соответствующим физическим устройством.
При этом имена специальных файлов можно использовать практически всюду, где можно использовать имена обычных файлов. Например, команда
cp myfile /tmp/kuz
перепишет файл с именем myfile в подкаталог kuz рабочего каталога. В то же время, команда
cp myfile /dev/console
выдаст содержимое файла myfile на системную консоль вашей установки.
Различаются два типа специальных файлов - блочные и символьные (подробности см. в разделе 3.3). Блочные специальные файлы ассоциируются с такими внешними устройствами, обмен с которыми производится блоками байтов данных, размером 512, 1024, 4096 или 8192 байтов. Типичным примером подобных устройств являются магнитные диски. Файловые системы всегда находятся на блочных устройствах, так что в команде mount обязательно указывается некоторое блочное устройство.
Символьные специальные файлы ассоциируются с внешними устройствами, которые не обязательно требуют обмена блоками данных равного размера. Примерами таких устройств являются терминалы (в том числе, системная консоль), последовательные устройства, некоторые виды магнитных лент. Иногда символьные специальные файлы ассоциируются с магнитными дисками.
При обмене данными с блочным устройством система буферизует данные во внутреннем системном кеше. Через определенные интервалы времени система "выталкивает" буфера, при которых содержится метка "измененный". Кроме того, существуют системные вызовы sync и fsync, которые могут использоваться в пользовательских программах, и выполнение которых приводит к выталкиванию измененных буферов из общесистемного пула. Основная проблема состоит в том, что при аварийной остановке компьютера (например, при внезапном выключении электрического питания) содержимое системного кеша может быть утрачено. Тогда внешние блочные файлы могут оказаться в рассогласованном состоянии. Например, может быть не вытолкнут супер-блок файловой системы, хотя файловая система соответствует его вытолкнутому состоянию. Заметим, что в любом случае согласованное состояние файловой системы может быть восстановлено (конечно, не всегда без потерь пользовательской информации).
Обмены с символьными специальными файлами производятся напрямую, без использования системной буферизации.
Файловая система ОС UNIX обеспечивает возможность связывания одного и того же файла с разными именами. Часто имеет смысл хранить под разными именами одну и ту же команду (выполняемый файл) командного интерпретатора. Например, выполняемый файл традиционного текстового редактора ОС UNIX vi обычно может вызываться под именами ex, edit, vi, view и vedit.
Можно узнать имена всех связей данного файла с помощью команды ncheck, если указать в числе ее параметров номер i-узла интересующего файла. Например, чтобы узнать все имена, под которыми возможен вызов редактора vi, можно выполнить следующую последовательность команд (третий аргумент команды ncheck представляет собой имя специального файла, ассоциированного с файловой системой /usr):
$ ls -i /usr/bin/vi
372 /usr/bin/vi
$ ncheck -i 372 /dev/dsk/sc0d0s5
/dev/dsk/sc0d0s5:
372 /usr/bin/edit
372 /usr/bin/ex
372 /usr/bin/vedit
372 /usr/bin/vi
372 /usr/bin/view
Ранее в большинстве версий ОС UNIX поддерживались только так называемые "жесткие" связи, означающие, что в соответствующем каталоге имени связи сопоставлялось имя i-узла соответствующего файла. Новые жесткие связи могут создаваться с помощью системного вызова link. При выполнении этого системного вызова создается новый элемент каталога с тем же номером i-узла, что и ранее существовавший файл.
Начиная с "быстрой файловой системы" университета Беркли, в мире UNIX появились "символические связи". Символическая связь создается с помощью системного вызова symblink. При выполнении этого системного вызова в соответствующем каталоге создается элемент, в котором имени связи сопоставляется некоторое имя файла (этот файл даже не обязан существовать к моменту создания символической связи). Для символической связи создается отдельный i-узел и даже заводится отдельный блок данных для хранения потенциально длинного имени файла.
Для работы с символьными связями поддерживаются три специальных системных вызова:
readlink - читает имя файла, связанного с именуемой символической связью (это имя может соответствовать реальному файлу, специальному файлу, жесткой ссылке или вообще ничему); имя хранится в блоке данных, связанном с данной символической ссылкой;
lstat - аналогичен системному вызову stat (получить информацию о файле), но относится к символической ссылке;
lchowm - аналогичен системному вызову chown, но используется для смены пользователя и группы самой символической ссылки.
Программный канал (pipe) - это одно из наиболее традиционных средств межпроцессных взаимодействий в ОС UNIX. В русской терминологии использовались различные переводы слова pipe (начиная от "трубки" и заканчивая замечательным русским словом "пайп"). Мы считаем, что термин "программный канал" наиболее точно отражает смысл термина "pipe".
Основной принцип работы программного канала состоит в буферизации байтового вывода одного процесса и обеспечении возможности чтения содержимого программного канала другим процессом в режиме FIFO (т.е. первым будет прочитан байт, который раньше всего записан). В любом случае интерфейс программного канала совпадает с интерфейсом файла (т.е. используются те же самые системные вызовы read и write).
Однако различаются два подвида программных каналов - неименованные и именованные. Неименованные программные каналы появились на самой заре ОС UNIX (см. раздел 1.2). Неименованный программный канал создается процессом-предком, наследуется процессами-потомками, и обеспечивает тем самым возможность связи в иерархии порожденных процессов. Интерфейс неименованного программного канала совпадает с интерфейсом файла (более подробно см. п. 3.4.4). Однако, поскольку такие каналы не имеют имени, им не соответствует какой-либо элемент каталога в файловой системе.
Именованному программному каналу обязательно соответствует элемент некоторого каталога и даже собственный i-узел. Другими словами, именованный программный канал выглядит как обычный файл, но не содержащий никаких данных до тех пор, пока некоторый процесс не выполнит в него запись. После того, как некоторый другой процесс прочитает записанные в канал байты, этот файл снова становится пустым. В отличие от неименованных программных каналов, именованные программные каналы могут использоваться для связи любых процессов (т.е. не обязательно процессов, входящих в одну иерархию родства). Интерфейс именованного программного канала практически полностью совпадает с интерфейсом обычного файла (включая системные вызовы open и close), хотя, конечно, необходимо учитывать, что поведение канала отличается от поведения файла (подробности см. в п. 3.4.4).
В современных версиях ОС UNIX (например, в UNIX System V.4) появилась возможность отображать обычные файлы в виртуальную память процесса с последующей работой с содержимым файла не с помощью системных вызовов read, write и lseek, а с помощью обычных операций чтения из памяти и записи в память. Заметим, что этот прием был базовым в историческом предшественнике ОС UNIX - операционной системе Multics (см. раздел 1.1).
Для отображения файла в виртуальную память, после открытия файла выполняется системный вызов mmap, действие которого состоит в том, что создается сегмент разделяемой памяти, ассоциированный с открытым файлом, и автоматически подключается к виртуальной памяти процесса (подробнее о разделяемой памяти см. п. 3.4.1). После этого процесс может читать из нового сегмента (реально будут читаться байты, содержащиеся в файле) и писать в него (реально все записи отображаются в файл). При закрытии файла соответствующий сегмент автоматически отключается от виртуальной памяти процесса и уничтожается, если только файл не подключен к виртуальной памяти некоторого другого процесса.
Несколько процессов могут одновременно открыть один и тот же файл и подключить его к своей виртуальной памяти системным вызовом mmap. Тогда любые изменения, производимые путем записи в соответствующий сегмент разделяемой памяти, будут сразу видны другим процессам.
Исторически в ОС UNIX всегда применялся очень простой подход к обеспечению параллельного (от нескольких процессов) доступа к файлам: система позволяла любому числу процессов одновременно открывать один и тот же файл в любом режиме (чтения, записи или обновления) и не предпринимала никаких синхронизационных действий. Вся ответственность за корректность совместной обработки файла ложилась на использующие его процессы, и система даже не предоставляла каких-либо особых средств для синхронизации доступа процессов к файлу.
В System V.4 появились средства, позволяющие процессам синхронизировать параллельный доступ к файлам. В принципе, было бы логично связать синхронизацию доступа к файлу как к единому целому с системным вызовом open (т.е., например, открытие файла в режиме записи или обновления могло бы означать его монопольную блокировку соответствующим процессом, а открытие в режиме чтения - совместную блокировку). Так поступают во многих операционных системах (начиная с ОС Multics). Однако, по отношению к ОС UNIX такое решение принимать было слишком поздно, поскольку многочисленные созданные за время существования системы прикладные программы опирались на свойство отсутствия автоматической синхронизации.
Поэтому разработчикам пришлось пойти "обходным путем". Ядро ОС UNIX поддерживает дополнительный системный вызов fcntl, обеспечивающий такие вспомогательные функции, относящиеся к файловой системе, как получение информации о текущем режиме открытия файла, изменение текущего режима открытия и т.д. В System V.4 именно на системный вызов fcntl нагружены функции синхронизации.
С помощью этого системного вызова можно установить монопольную или совместную блокировку файла целиком или блокировать указанный диапазон байтов внутри файла. Допускаются два варианта синхронизации: с ожиданием, когда требование блокировки может привести к откладыванию процесса до того момента, когда это требование может быть удовлетворено, и без ожидания, когда процесс немедленно оповещается об удовлетворении требования блокировки или о невозможности ее удовлетворения в данный момент времени.
Установленные блокировки относятся только к тому процессу, который их установил, и не наследуются процессами-потомками этого процесса. Более того, даже если некоторый процесс пользуется синхронизационными возможностями системного вызова fcntl, другие процессы по-прежнему могут работать с тем файлом без всякой синхронизации. Другими словами, это дело группы процессов, совместно использующих файл, - договориться о способе синхронизации параллельного доступа.
Поскольку ОС UNIX с самого своего зарождения задумывалась как многопользовательская операционная система, в ней всегда была актуальна проблема авторизации доступа различных пользователей к файлам файловой системы. Под авторизацией доступа мы понимаем действия системы, которые допускают или не допускают доступ данного пользователя к данному файлу в зависимости от прав доступа пользователя и ограничений доступа, установленных для файла. Схема авторизации доступа, примененная в ОС UNIX, настолько проста и удобна и одновременно настолько мощна, что стала фактическим стандартом современных операционных систем (не претендующих на качества систем с многоуровневой защитой).
С каждым выполняемым процессом в ОС UNIX связываются реальный идентификатор пользователя (real user ID), действующий идентификатор пользователя (effective user ID) и сохраненный идентификатор пользователя (saved user ID). Все эти идентификаторы устанавливаются с помощью системного вызова setuid, который можно выполнять только в режиме суперпользователя. Аналогично, с каждым процессом связываются три идентификатора группы пользователей - real group ID, effective group ID и saved group ID. Эти идентификаторы устанавливаются привилегированным системным вызовом setgid.
При входе пользователя в систему программа login проверяет, что пользователь зарегистрирован в системе и знает правильный пароль (если он установлен), образует новый процесс и запускает в нем требуемый для данного пользователя shell. Но перед этим login устанавливает для вновь созданного процесса идентификаторы пользователя и группы, используя для этого информацию, хранящуюся в файлах /etc/passwd и /etc/group. После того, как с процессом связаны идентификаторы пользователя и группы, для этого процесса начинают действовать ограничения для доступа к файлам. Процесс может получить доступ к файлу или выполнить его (если файл содержит выполняемую программу) только в том случае, если хранящиеся при файле ограничения доступа позволяют это сделать. Связанные с процессом идентификаторы передаются создаваемым им процессам, распространяя на них те же ограничения. Однако в некоторых случаях процесс может изменить свои права с помощью системных вызовов setuid и setgid, а иногда система может изменить права доступа процесса автоматически.
Рассмотрим, например, следующую ситуацию. В файл /etc/passwd запрещена запись всем, кроме суперпользователя (суперпользователь может писать в любой файл). Этот файл, помимо прочего, содержит пароли пользователей и каждому пользователю разрешается изменять свой пароль. Имеется специальная программа /bin/passwd, изменяющая пароли. Однако пользователь не может сделать это даже с помощью этой программы, поскольку запись в файл /etc/passwd запрещена. В системе UNIX эта проблема разрешается следующим образом. При выполняемом файле может быть указано, что при его запуске должны устанавливаться идентификаторы пользователя и/или группы. Если пользователь запрашивает выполнение такой программы (с помощью системного вызова exec), то для соответствующего процесса устанавливаются идентификатор пользователя, соответствующий идентификатору владельца выполняемого файла и/или идентификатор группы этого владельца. В частности, при запуске программы /bin/passwd процесс получит идентификатор суперпользователя, и программа сможет произвести запись в файл /etc/passwd.
И для идентификатора пользователя, и для идентификатора группы реальный ID является истинным идентификатором, а действующий ID - идентификатором текущего выполнения. Если текущий идентификатор пользователя соответствует суперпользователю, то этот идентификатор и идентификатор группы могут быть переустановлены в любое значение системными вызовами setuid и setgid. Если же текущий идентификатор пользователя отличается от идентификатора суперпользователя, то выполнение системных вызовов setuid и setgid приводит к замене текущего идентификатора истинным идентификатором (пользователя или группы соответственно).
Как и принято в многопользовательской операционной системе, в UNIX поддерживается единообразный механизм контроля доступа к файлам и справочникам файловой системы. Любой процесс может получить доступ к некоторому файлу в том и только в том случае, если права доступа, описанные при файле, соответствуют возможностям данного процесса.
Защита файлов от несанкционированного доступа в ОС UNIX основывается на трех фактах. Во-первых, с любым процессом, создающим файл (или справочник), ассоциирован некоторый уникальный в системе идентификатор пользователя (UID - User Identifier), который в дальнейшем можно трактовать как идентификатор владельца вновь созданного файла. Во-вторых, с каждый процессом, пытающимся получить некоторый доступ к файлу, связана пара идентификаторов - текущие идентификаторы пользователя и его группы. В-третьих, каждому файлу однозначно соответствует его описатель - i-узел.
На последнем факте стоит остановиться более подробно. Важно понимать, что имена файлов и файлы как таковые - это не одно и то же. В частности, при наличии нескольких жестких связей с одним файлом несколько имен файла реально представляют один и тот же файл и ассоциированы с одним и тем же i-узлом. Любому используемому в файловой системе i-узлу всегда однозначно соответствует один и только один файл. I-узел содержит достаточно много разнообразной информации (большая ее часть доступна пользователям через системные вызовы stat и fstat), и среди этой информации находится часть, позволяющая файловой системе оценить правомощность доступа данного процесса к данному файлу в требуемом режиме.
Общие принципы защиты одинаковы для всех существующих вариантов системы: Информация i-узла включает UID и GID текущего владельца файла (немедленно после создания файла идентификаторы его текущего владельца устанавливаются соответствующими действующим идентификатором процесса-создателя, но в дальнейшем могут быть изменены системными вызовами chown и chgrp). Кроме того, в i-узле файла хранится шкала, в которой отмечено, что может делать с файлом пользователь - его владелец, что могут делать с файлом пользователи, входящие в ту же группу пользователей, что и владелец, и что могут делать с файлом остальные пользователи. Мелкие детали реализации в разных вариантах системы различаются. Для определенности мы приведем точную картину того, как это происходит в UNIX System V Release 4 (таблица 2.1).
Таблица 2.1.
Представление информации, ограничивающей доступ к файлу, в i-узле файла
| Шкала ограничений в восьмеричном виде | Описание | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 04000 | Устанавливать идентификатор пользователя-владельца при выполнении файла. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 020n0 | При n = 7, 5, 3 или 1 устанавливать идентификатор группы владельца при выполнении файла. При n = 6, 4, 2 или 0 разрешается блокирование диапазонов адресов файла. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 01000 | Сохранять в области подкачки образ кодового сегмента выполняемого файла после конца его выполнения. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 00400 | Владельцу файла разрешено чтение файла. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 00200 | Владелец файла может дополнять или модифицировать файл. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 00100 | Владелец файла может его исполнять, если файл - исполняемый, или производить в нем поиск, если это файл-каталог. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 00040 | Все пользователи группы владельца могут читать файл. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 00020 | Все пользователи группы владельца могут дополнять или модифицировать файл. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 00010 | Все пользователи группы владельца могут исполнять файл, если файл - исполняемый, или производить в нем поиск, если это файл-каталог. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 00004 | Все пользователи могут читать файл. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 00002 | Все пользователи могут дополнять или модифицировать файл. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 00001 | Все пользователи могут исполнять файл, если файл - исполняемый, или производить в нем поиск, если это файл-каталог. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Управление внешними устройствами - это одна из важнейших функций любой операционной системы. Система должна обеспечивать эффективный и удобный доступ к периферийным устройствам, а также обеспечивать возможность унифицированной разработки программного обеспечения для вновь подключаемых внешних устройств. Рассмотрим, как эта проблема решается в ОС UNIX.
В п. 2.4.4 мы уже отмечали, что для доступа к внешним устройствам в ОС UNIX используется универсальная абстракция файла. Помимо настоящих файлов (обычных файлов или каталогов), которые реально занимают память на магнитных дисках, файловая система содержит так называемые специальные файлы, для которых, как и для настоящих файлов, отводятся отдельные i-узлы, но которым на самом деле соответствуют внешние устройства. Это решение позволяет естественным образом работать в одном и том же интерфейсе с любым файлом или внешним устройством. (На самом деле, в некоторых случаях нестандартных внешних устройств приходится выходить за пределы стандартного интерфейса. Подробности и детали приводятся в разделе 3.3.).
Любому программисту должно быть ясно, что простое объявление внешнего устройства специальным файлом не даст возможности работать с этим устройством, если не создан и соответствующим образом не подключен к системе специальный программный код, соответствующий специфике данного устройства. Как и в большинстве современных операционных систем, такого рода программный код в ОС UNIX называется драйвером устройства (в этом контексте слово драйвер лучше всего понимать в значении "управляющий").
Для профессионалов в области операционных систем драйверы ОС UNIX, в сущности, не представляют ничего нового. По-простому говоря, в любой системе драйвер устройства - это многовходовой программный модуль со своими статическими данными, который умеет инициировать работу с устройством, выполнять заказываемые пользователем обмены (на ввод или вывод данных), терминировать работу с устройством и обрабатывать прерывания от устройства. Однако, в любой операционной системе имеется своя технология разработки драйверов. В частности, в ОС UNIX различаются символьные, блочные и потоковые драйверы.
Символьные драйверы являются простейшими в ОС UNIX и предназначаются для обслуживания устройств, которые реально ориентированы на прием или выдачу произвольных последовательностей байтов (например, простой принтер или устройство ввода с перфоленты). Такие драйверы используют минимальный набор стандартных функций ядра UNIX, которые главным образом заключаются в возможности взять данные из виртуального пространства пользовательского процесса и/или поместить данные в такое виртуальное пространство.
Блочные драйверы - более сложные. Они работают с использованием возможностей системной буферизации блочных обменов ядра ОС UNIX. В число функций такого драйвера входит включение соответствующего блока данных в систему буферов ядра ОС UNIX и/или взятие содержимого буферной области в случае необходимости.
Наконец, наиболее сложной организацией отличаются потоковые драйверы. Фактически, такой драйвер представляет собой конвейер модулей, обеспечивающий многоступенчатую обработку запросов пользователя. Потоковые драйверы в среде ОС UNIX в основном предназначены для реализации доступа к сетевым устройствам, которые должны работать в соответствии с многоуровневыми сетевыми протоколами.
Подробности по поводу разных способов организации драйверов в ОС UNIX см. в разделе 3.3.
Последний момент, на который мы хотим обратить внимание в этом пункте, состоит в том, что (опять же, как и в большинстве развитых операционных систем) в ОС UNIX возможны два способа включения драйвера в состав ядра ОС. Первый способ состоит в полном включении драйвера в состав ядра на стадии генерации системы (т.е. драйвер статически объявляется частью ядра системы). Второй способ позволяет обойтись минимальным количеством статических объявлений на стадии генерации ядра (фактически, обеспечиваются лишь необходимые элементы статических таблиц). В любой момент работы системы такой драйвер может быть динамически загружен в ядро системы. После появления (статического или динамического) в ядре ОС UNIX драйверы всех разновидностей функционируют единообразно.
Независимо от типа файла (обычный файл, каталог, связь или специальный файл) пользовательский процесс может работать с файлом через стандартный интерфейс, включающий системные вызовы open, close, read и write. Ядро само распознает, нужно ли обратиться к его стандартным функциям или вызвать подпрограмму драйвера устройства. Другими словами, если процесс пользователя открывает для чтения обычный файл, то системные вызовы open и read обрабатываются встроенными в ядро подпрограммами open и read соответственно. Однако, если файл является специальным, то будут вызваны подпрограммы open и read, определенные в соответствующем драйвере устройства (рисунок 2.3).
Кратко поясним этот рисунок. С каждым специальным файлом в системе связаны старший (major) и младший (minor) номера. После того, как (по содержанию i-узла) файловая система распознает, что данный файл является специальным, ядро ОС UNIX использует старший номер специального файла как индекс в конфигурационной таблице драйверов устройств. Поддерживаются две раздельные таблицы для символьных и блочных специальных файлов (или соответствующих драйверов). Для блочных драйверов используется системная таблица bdevsw, а для символьных - cdevsw. В обоих случаях элементом таблицы является структура (в терминах языка программирования Си), элементы которой содержат указатели на подпрограммы соответствующего драйвера. Допускается (и на самом деле используется) реализация драйверов, которые одновременно могут обрабатывать и блочный, и символьный ввод/вывод. В этом случае для драйвера будут существовать и элемент таблицы bdevsw, и таблицы cdevsw.
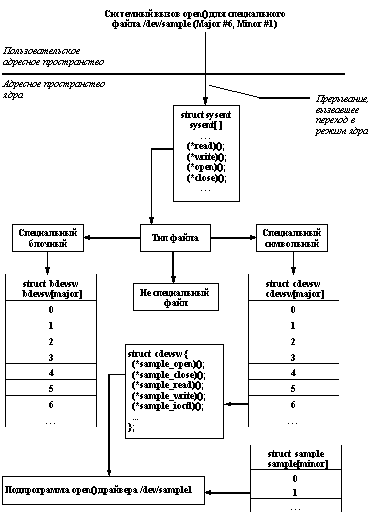
Рис. 2.3. Логическое представление открытия специального символьного файла
Старшему номеру специального файла блочного или специального файла, вообще говоря, соответствуют разные драйверы. Например, символьному специальному файлу /dev/tty и блочному специальному файлу /dev/swap в UNIX System V соответствует старший номер 6. Но поскольку первый специальный файл - символьный, а второй - блочный, они могут использовать один и тот же старший номер, хотя им соответствуют разные драйверы. В любом случае, младший номер специального файла передается в качестве параметра соответствующей функции драйвера, который волен использовать его любым образом, хотя обычно младший номер используется в качестве номера устройства, обслуживаемого аппаратным контроллером, которым на самом деле управляет данный драйвер. Другими словами, один драйвер как программная единица может управлять несколькими физическими устройствами.
Операционная система UNIX с самого своего возникновения была по своей сути сетевой операционной системой. Однако по причине одновременного наличия нескольких вариантов ОС (см. раздел 1) образовалось несколько альтернативных механизмов, каждый из которых обладал собственными преимуществами и недостатками. В наиболее унифицированном и стандартизированном варианте UNIX System V среди этих механизмов был наведен некоторый порядок, и в этом разделе мы приведем сравнительно краткий обзор современного положения дел.
В самых ранних вариантах UNIX коммуникационные средства основывались на символьном вводе/выводе, главным образом потому, что аппаратной основой являлись модемы и терминалы. Поскольку такие устройства являются относительно медленными, в ранних вариантах не требовалось особенно заботиться о модульности и эффективности программного обеспечения. Несколько позже в системе появилась поддержка более развитых устройств, протоколов, операционных режимов и т.д., но программные средства по-прежнему основывались на ограниченных возможностях символьного ввода/вывода.
С появлением многоуровневых сетевых протоколов, таких как TCP/IP (US Defense Advanced Research Project Agency's Transmission Control Protocol/Internet Protocol), SNA (IBM's System Network Architecture), OSI (Open Systems Internetworking), X.25 и др. стало понятно, что в ОС UNIX требуется некоторая общая основа организации сетевых средств, основанных на многоуровневых протоколах. Для решения этой проблемы было реализовано несколько механизмов, обладающих примерно одинаковыми возможностями, но не совместимых между собой, поскольку каждый из них являлся результатом некоторого индивидуального проекта.
Общей проблемой ОС UNIX было то, что слабая развитость подсистемы ввода/вывода требовала решения задачи проектирования и включения в систему нового драйвера при каждом подключении нового устройства. Хотя зачастую уже существовал программный код, обладающий хотя бы частью функций, требуемых в новом драйвере, отсутствовала возможность использования этого существующего кода.
Во многом эта проблема была решена компанией AT&T, которая предложила и реализовала механизм потоков (STREAMS), обеспечивающий гибкие и модульные возможности для реализации драйверов устройств и коммуникационных протоколов. Потоки были впервые реализованы Деннисом Ритчи в 1984 году и были включены в пакет Networking Support Facilities (NSU) UNIX System V Release 3.
В UNIX System V Release 3 потоки были включены как основа реализации существующего символьного ввода/вывода. Однако в Release 4 в реализацию потоков были включены интерфейс драйвера устройства (DDI - Device Driver Interface) и интерфейс между драйвером и ядром (DKI - Device Kernel Interface), которые в совокупности одновременно обеспечивают возможности по взаимодействию драйвера устройства с ядром системы и простоту повторного использования имеющегося исходного кода драйверов. С использованием механизма потоков были переписаны практически все символьные драйверы, полностью переработаны подсистема управления терминалами и механизм программных каналов (pipes).
Если не вдаваться в детали, Streams представляют собой связанный набор средств общего назначения, включающий системные вызовы и подпрограммы, а также ресурсы ядра. В совокупности эти средства обеспечивают стандартный интерфейс символьного ввода/вывода внутри ядра, а также между ядром и соответствующими драйверами устройств, предоставляя гибкие и развитые возможности разработки и реализации коммуникационных сервисов. При этом механизм потоков не навязывает какой-либо конкретной архитектуры сети и/или конкретных протоколов. Как и любой другой драйвер устройства, потоковый драйвер представляется специальным файлом файловой системы со стандартным набором операций: open, close, read, write и ioctl. Простейшая форма организации потокового интерфейса показана на рисунке 2.4.
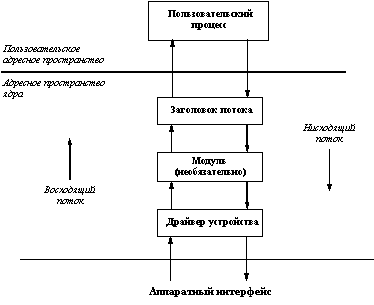
Рис. 2.4. Простая форма потокового интерфейса
Когда пользовательский процесс открывает потоковое устройство, пользуясь системным вызовом open, ядро связывает с драйвером заголовок потока. После этого пользовательский процесс общается с заголовком потока так, как если бы он представлял собой обычный драйвер устройства. Другими словами, заголовок потока отвечает за обработку всех системных вызовов, производимых пользовательским процессом по отношению к потоковому драйверу. Если процесс выполняет запись в устройство (системный вызов write), заголовок потока передает данные драйверу устройства в нисходящем направлении. Аналогично, при реализации чтения из устройства (системный вызов read) драйвер устройства передает данные заголовку потока в восходящем направлении.
В описанной схеме данные между заголовком потока и драйвером устройства передаются в неизменяемом виде без какой-либо промежуточной обработки. Однако можно добиться того, чтобы данные подвергались обработке при передаче их в любом направлении, если включить в поток между заголовком и драйвером устройства один или несколько потоковых модулей. Потоковый модуль является обработчиком данных, выполняющим определенный набор функций над данными по мере их прохождения по потоку. Простейшими примерами потокового модуля являются разного рода перекодировщики символьной информации. Более сложным примером является потоковый модуль, осуществляющий разборку нисходящих данных в пакеты для их передачи по сети и сборку восходящих данных с удалением служебной информации пакетов.
Каждый потоковый модуль является, вообще говоря, независимым от присутствия в потоке других модулей, обрабатывающих данные. Данные могут подвергаться обработке произвольным числом потоковых модулей, пока в конце концов не достигнут драйвера устройств при движении в нисходящем направлении или заголовка потока при движении в восходящем направлении. Для передачи данных от заголовка к драйверу или модулю, от одного модуля другому и от драйвера или модуля к заголовку потока используется механизм сообщений. Каждое сообщение представляет собой набор блоков сообщения, каждый из которых состоит из заголовка, блока данных и буфера данных.
TCP/IP (Transmission Control Protocol/Internet Protocol) представляет собой семейство протоколов, основным назначением которых является обеспечение возможности полезного сосуществования компьютерных сетей, основанных на разных технологиях. В 1969 году Агентство перспективных исследовательских проектов министерства обороны США (DARPA - Department of Defense Advanced Research Project Agency) поддержало и финансировало проект, посвященный поиску общей основы связи сетей с разной технологией. В результате выполнения этого проекта была образована единая виртуальная сеть, получившая название Internet. В Internet для связи независимых сетей, или доменов используется набор шлюзов. Каждый индивидуальный узел сети (Host) идентифицируется уникальным адресом, называемым адресом в Internet.
Для разрешения проблемы различий в форматах кадров, используемых в разных сетях, был определен универсальный формат пакета данных, называемого IP-датаграммой (Internet Protocol Datagram), состоящего из заголовка и порции данных и поэтому похожего на обычный сетевой кадр. Однако порция данных IP-датаграммы сама содержится внутри сетевого кадра, т.е. IP-датаграмма погружается в сетевой кадр конкретного формата и поэтому может передаваться в разных сетях, входящих в Internet. Все узлы, шлюзы и сети Internet должны быть в состоянии понимать IP-датаграммы.
Узлы, взаимодействующие в Internet, не устанавливают между собой физические соединения для целей индивидуального взаимодействия. Поэтому датаграммы не обрабатываются в каком-либо конкретном порядке. Напротив, каждая датаграмма обрабатывается независимо от других, что позволяет эффективно разделять ресурсы для всего множества (логически) связанных узлов. Но это, к сожалению, означает, что сервис, предоставляемый Internet, не является надежным, поскольку не гарантирует доставку пакетов в нужном порядке, отсутствие потерь датаграмм или отсутствие их дублирования.
Эту проблему решает протокол TCP (Transmission Control Protocol), обеспечивающий надежную доставку сообщений за счет подтверждений доставки датаграмм и их повторной передачи в случае надобности. Если узел, посылающий датаграмму, не получает подтверждение о ее доставке в течение установленного промежутка времени, то считается, что датаграмма не доставлена, и она посылается повторно.
Полное семейство протоколов, основанных на использовании IP-датаграмм, называется TCP/IP. Наиболее важными и базисными протоколами этого семейства (или стека, как его часто называют) являются кратко описанные выше протоколы IP и TCP. Мы не будем описывать остальные протоколы семейства TCP/IP. Для определенности все они перечислены в таблице 2.2. Большая часть коммуникационных средств ОС UNIX основывается на использовании протоколов стека TCP/IP.
Таблица 2.2.
Семейство протоколов TCP/IP
| Название протокола | Описание протокола | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| TCP | Протокол управления передачей (Transmission Control Protocol) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| UDP | Протокол пользовательских датаграмм (User Datagram Protocol) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ARP | Протокол разрешения адресов (Address Resolution Protocol) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| RARP | Протокол обратного разрешения адресов (Reverse Address Resolution Protocol) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| IP | Протокол Internet (Internet Protocol) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ICMP | Протокол управляющих сообщений Internet (Internet Control Message Protocol) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| FTP | Протокол пересылки файлов (File Transfer Protocol) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| TFTP | Простой протокол пересылки файлов (Trivial File Transfer Protocol) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
В UNIX System V Release 4 протокол TCP/IP реализован как набор потоковых модулей плюс дополнительный компонент TLI (Transport Level Interface - Интерфейс транспортного уровня). TLI является интерфейсом между прикладной программой и транспортным механизмом. Приложение, пользующееся интерфейсом TLI, получает возможность использовать TCP/IP.
Интерфейс TLI основан на использовании классической семиуровневой модели ISO/OSI, которая разделяет сетевые функции на семь областей, или уровней. Цель модели в обеспечении стандарта сетевой связи компьютеров независимо от производителя аппаратуры компьютеров и/или сети. Семь уровней модели можно кратко описать следующим образом.
Уровень 1: Физический уровень (Physical Level) - среда передачи (например, Ethernet). Уровень отвечает за передачу неструктурированных данных по сети.
Уровень 2: Канальный уровень (Data Link Layer) - уровень драйвера устройства, называемый также уровнем ARP/RARP в TCP/IP. Этот уровень, в частности, отвечает за преобразование данных при исправлении ошибок, происходящих на физическом уровне.
Уровень 3: Сетевой уровень (Network Level) - отвечает за выполнение промежуточных сетевых функций, таких как поиск коммуникационного маршрута при отсутствии возможности прямой связи между узлом-отправителем и узлом-получателем. В TCP/IP этот уровень соответствует протоколам IP и ICMP.
Уровень 4: Транспортный уровень (Transport Level) - уровень протоколов TCP/IP или UDP/IP семейства протоколов TCP/IP. Уровень отвечает за разборку сообщения на фрагменты (пакеты) при передаче и за сборку полного сообщения из пакетов при приеме таким образом, что на более старших уровнях модели эти процедуры вообще незаметны. Кроме того, на этом уровне выполняется посылка и обработка подтверждений и, при необходимости, повторная передача.
Уровень 5: Уровень сессий (Session Layer) - отвечает за управление переговорами взаимодействующих транспортных уровней. В NFS (Network File System - Сетевая файловая система, см. п. 2.8.1) этот уровень используется для реализации механизма вызовов удаленных процедур (RPC - Remote Procedure Calls, см. п. 2.7.4).
Уровень 6: Уровень представлений (Presentation Layer) - отвечает за управление представлением информации. В NFS на этом уровне реализуется механизм внешнего представления данных (XDR - External Data Representation), машинно-независимого представления, понятного для всех компьютеров, входящих в сеть.
Уровень 7: Уровень приложений - интерфейс с такими сетевыми приложениями, как telnet, rlogin, mail и т.д.
Интерфейс TLI соответствует трем старшим уровням этой модели (с пятого по седьмой) и позволяет прикладному процессу пользоваться сервисами сети (без необходимости знать о деталях транспортного и более низких уровней). В System V Release 4 TLI реализован на основе механизма потоков. Для доступа используются не специальные системные вызовы, а функции библиотеки /usr/lib/libnsl_s.a.
Механизм программных гнезд (Sockets) впервые был реализован в 1982 году в UNIX BSD 4.1 в качестве развитого средства межпроцессных взаимодействий. Это средство, вообще говоря, позволяет любому процессу обмениваться сообщениями с любым другим процессом, независимо от того, выполняются они на одном компьютере или на разных, соединенных сетью. Функционально механизм программных гнезд близок к возможностям TLI (пятого уровня в соответствии с моделью ISO/OSI).
Программные гнезда входят в число обязательных компонентов стандартной среды ОС UNIX, однако реализуются в разных системах по-разному. В BSD-ориентированных системах Sockets исторически реализуются в ядре ОС, и пользователям предоставляются пять специальных системных вызовов: socket, bind, listen, connect и accept (подробнее о функциях этих системных вызовов см. п. 3.4.5).
В UNIX System V Release 4 тоже поддерживается механизм программных гнезд, однако он реализован не внутри ядра системы, а в виде набора библиотечных функций (библиотеки /usr/lib/libsocket.a), которые написаны с использованием механизма TLI. Заметим, что это в очередной раз демонстрирует преимущества подхода открытых систем, который всегда поддерживался в мире ОС UNIX: при наличии четко определенных интерфейсов и развитых базовых средств прикладной программист и разработанные им программы не должны зависеть от конкретной реализации.
Тем не менее, разработчики и поставщики System V призывают не использовать механизм Sockets в новых программах, а опираться непосредственно на возможности TLI. По нашему мнению, это дело вкуса, поскольку существует так много давно написанных программ, использующих программные гнезда, что ни один поставщик ОС UNIX никогда не решится перестать поддерживать Sockets.
Основными идеями механизма вызова удаленных процедур (RPC - Remote Procedure Calls) являются следующие:
(а) Во многих случаях взаимодействие процессов носит ярко выраженный асимметричный характер. Один из процессов ("клиент") запрашивает у другого процесса ("сервера") некоторую услугу (сервис) и не продолжает свое выполнение до тех пор, пока эта услуга не будет выполнена (и пока процесс-клиент не получит соответствующие результаты). Видно, что семантически такой режим взаимодействия эквивалентен вызову процедуры, и естественно желание оформить его должным образом синтаксически.
(б) Как уже отмечалось, ОС UNIX по своей идеологии с самого начала была по-настоящему сетевой операционной системой. Свойства переносимости позволяют, в частности, предельно просто создавать "операционно однородные" сети, включающие разнородные компьютеры. Однако, остается проблема разного представления данных в компьютерах разной архитектуры (часто по-разному представляются числа с плавающей точкой, используется разный порядок размещения байтов в машинном слове и т.д.). Плохо, когда решение проблемы разных представлений данных возлагается на пользователей. Поэтому второй идеей RPC (многие считают, что это основная идея) является автоматическое обеспечение преобразования форматов данных при взаимодействии процессов, выполняющихся на разнородных компьютерах.
Впервые пакет RPC был реализован компанией Sun Microsystems в 1984 году в рамках ее продукта NFS (Network File System - сетевая файловая система, см. п. 2.8.1). Пакет был тщательно специфицирован с тем, чтобы пользовательский интерфейс и его функции не были зависимыми от применяемого транспортного механизма. Заметим, что в настоящее время Sun распространяет два варианта пакета - бесплатный (Public Domain), основанный на использовании программных гнезд, и коммерческий, базирующийся на механизме потоков (на самом деле, на интерфейсе TLI). В обоих случаях пакет реализуется как набор библиотечных функций. Например, в случае использования коммерческого варианта RPC в среде System V программы должны компоноваться с библиотекой /usr/lib/librpcsvc.a. Специальные системные вызовы для реализации RPC не поддерживаются.
Независимость от конкретного машинного представления данных обеспечивается отдельно специфицированным протоколом XDR (EXternal Data Representation - внешнее представление данных). Этот протокол определяет стандартный способ представления данных, скрывающий такие машинно-зависимые свойства, как порядок байтов в слове, требования к выравниванию начального адреса структуры, представление стандартных типов данных и т.д. По существу, XDR реализуется как независимый пакет, который используется не только в RPC, но и других продуктах (например, в NFS).
Основная идея распределенной файловой системы состоит в том, чтобы обеспечить совместный доступ к файлам локальной файловой системы для процессов, которые, вообще говоря, выполняются на других компьютерах. Эта идея может быть реализована многими разными способами, однако в среде ОС UNIX все известные подходы основываются на монтировании удаленной файловой системы к одному из каталогов локальной файловой системы. После выполнения этой процедуры файлы, хранимые в удаленной файловой системе, доступны процессам локального компьютера точно таким же образом, как если бы они хранились на локальном дисковом устройстве.
На рисунке 2.5 приведен пример, в котором два подкаталога удаленной файловой системы-сервера (share и X11) монтируются к двум (пустым) каталогам файловой системы-клиента.
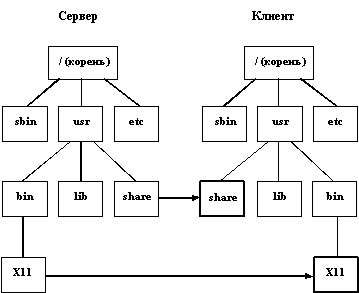
Рис. 2.5. Схема монтирования удаленной файловой системы
В принципе, такая схема обладает и достоинствами, и недостатками. К достоинствам, конечно, относится то, что при работе в сети можно экономить дисковое пространство, поддерживая совместно используемые информационные ресурсы только в одном экземпляре. Но, с другой стороны, пользователи удаленной файловой системы неизбежно будут работать с удаленными файлами существенно более медленно, чем с локальными. Кроме того, реальная возможность доступа к удаленному файлу критически зависит от работоспособности сервера и сети. Заметим, что распространенные в мире UNIX сетевые файловые системы NFS (Network File System - сетевая файловая система) и RFS (Remote File Sharing - совместное использование удаленных файлов) являются достаточно тщательно спроектированными и разработанными продуктами, во многом сглаживающими отмеченные недостатки.
Система NFS была разработана компанией Sun Microsystems как часть ее сетевого продукта ONC (Open Network Computing - открытая сетевая вычислительная обработка). В настоящее время NFS является официальным компонентом UNIX System V Release 4.
NFS разрабатывалась как система, пригодная к использованию не только на разных аппаратных, но и на разных операционных платформах. В настоящее время продукт NFS в соответствии со спецификациями и на основе программного кода Sun Microsystems выпускает более 200 производителей. Отметим, в частности, наличие популярного в России продукта PC-NFS, обеспечивающего клиентскую часть системы в среде MS-DOS. Кроме того, заметим, что имеются и свободно доступные (public domain), и коммерческие варианты NFS.
Первоначально NFS разрабатывалась в среде UNIX BSD 4.2, и для реализации системы потребовалось существенно переделать код системных вызовов файловой системы. При внедрении NFS в среду System V понадобилась значительная переделка ядра ОС. Отмечается, что большая часть изменений в ядре System V Release 4 была связана именно с NFS.
В архитектурном отношении в NFS выделяются три основные части: протокол, серверная часть и клиентская часть. Протокол NFS опирается на примитивы RPC, которые, в свою очередь, построены над протоколом XDR (см. п. 2.7.4). Клиентская часть NFS взаимодействует с серверной частью системы на основе механизма RPC.
Основным достоинством NFS является возможность использования в среде разных операционных систем. Возможным недостатком является то, что независимость от транспортных средств ограничена уровнем такой независимости, присущей RPC. В настоящее время де-факто это означает, что NFS можно использовать только в TCP/IP-ориентированных сетях. (Это еще вопрос - плохо ли это, поскольку стимулирует использование единообразных сетевых механизмов.)
Сетевая файловая система RFS была реализована компанией AT&T в рамках ее продукта UNIX System V Release 3. Функционально она выглядит подобно NFS, т.е. обеспечивает прозрачный доступ к удаленным файлам. Однако реализация системы абсолютно отлична. Основным недостатком RFS является то, что система реализуема только на компьютерах, работающих под управлением ОС UNIX (причем именно UNIX System V с номером выпуска не меньше, чем 3). Но с другой стороны, это решение позволило сохранить для пользователей RFS всю семантику файлов ОС UNIX. В частности (в отличие от NFS), в удаленной файловой системе могут находиться не только обычные файлы и каталоги, но и специальные файлы и именованные программные каналы. Более того, на удаленные файлы распространяются возможности блокировки файлов и/или диапазонов адресов внутри файлов.
Если NFS опирается на протокол RPC, то в RFS используется родной для AT&T протокол обмена сообщениями на основе потоков (другими словами, реализация RFS основана на использовании интерфейса TLI). (Кстати, в этом имеется большой смысл, поскольку механизм RPC во многих случаях является слишком ограничительным.)
Другим преимуществом RPC (тоже связанным с использованием TLI) является независимость системы от используемого транспортного механизма (если, конечно, этот механизм поддерживает спецификации семиуровневой модели ISO/OSI). Поэтому эту систему можно использовать в среде операционных систем, основывающихся на различных сетевых протоколах (ISO/OSI уважают практически все).
В этой вводной части курса мы (возможно, слишком поверхностно)
рассмотрели наиболее важные особенности ОС UNIX. В следующих частях
будут детально обсуждаться более технические и/или частные вопросы.