|
|
|
Close Help | ||||||||||||||
|
|
|
Close Help | ||||||||||||||
В этой части курса мы более подробно остановимся на базовых функциях ядра ОС UNIX. Основная цель этой части - ввести слушателя курса (и читателя этого документа) в основные идеи ядра ОС UNIX, т.е. показать, чем руководствовались разработчики системы при выборе базовых проектных решений. При этом мы не стремимся излагать технические детали организации ядра, поскольку (как это обычно бывает при попытках совместного идейно-технического изложения) мы утратили бы явное различие между принципиальными и техническими решениями.
Возможно, выбор тем этой части довольно субъективен. Не исключено, что кто-то другой обратил бы большее внимание на другие вопросы, связанные с функциями ядра операционной системы. Однако подчеркнем, что мы следуем классическому представлению о функциях ядра ОС, введенному еще профессором Дейкстрой. В соответствии с этим представлением, ядро любой ОС прежде всего отвечает за управление основной памятью компьютера и виртуальной памятью выполняемых процессов, за управление процессором и планирование распределения процессорных ресурсов между совместно выполняемыми процессами, за управление внешними устройствами и, наконец, за обеспечение базовых средств синхронизации и взаимодействия процессов. Именно эти вопросы мы рассмотрим в данной части курса применительно к ОС UNIX (иногда к UNIX вообще, а иногда к UNIX System V).
Основная (или как ее принято называть в отечественной литературе и документации, оперативная) память всегда была и остается до сих пор наиболее критическим ресурсом компьютеров. Если учесть, что большинство современных компьютеров обеспечивает 32-разрядную адресацию в пользовательских программах, и все большую силу набирает новое поколение 64-разрядных компьютеров, то становится понятным, что практически безнадежно рассчитывать, что когда-нибудь удастся оснастить компьютеры основной памятью такого объема, чтобы ее хватило для выполнения произвольной пользовательской программы, не говоря уже об обеспечении мультипрограммного режима, когда в основной памяти, вообще говоря, могут одновременно содержаться несколько пользовательских программ.
Поэтому всегда первичной функцией всех операционных систем (более точно, операционных систем, обеспечивающих режим мультипрограммирования) было обеспечение разделения основной памяти между конкурирующими пользовательскими процессами. Мы не будем здесь слишком сильно вдаваться в историю этого вопроса. Заметим лишь, что применявшаяся техника распространяется от статического распределения памяти (каждый процесс пользователя должен полностью поместиться в основной памяти, и система принимает к обслуживанию дополнительные пользовательские процессы до тех пор, пока все они одновременно помещаются в основной памяти), с промежуточным решением в виде "простого своппинга" (система по-прежнему располагает каждый процесс в основной памяти целиком, но иногда на основании некоторого критерия целиком сбрасывает образ некоторого процесса из основной памяти во внешнюю память и заменяет его в основной памяти образом некоторого другого процесса), до смешанных стратегий, основанных на использовании "страничной подкачки по требованию" и развитых механизмов своппинга.
Операционная система UNIX начинала свое существование с применения очень простых методов управления памятью (простой своппинг), но в современных вариантах системы для управления памятью применяется весьма изощренная техника.
Идея виртуальной памяти далеко не нова. Сейчас многие полагают, что в основе этой идеи лежит необходимость обеспечения (при поддержке операционной системы) видимости практически неограниченной (32- или 64-разрядной) адресуемой пользовательской памяти при наличии основной памяти существенно меньших размеров. Конечно, этот аспект очень важен. Но также важно понимать, что виртуальная память поддерживалась и на компьютерах с 16-разрядной адресацией, в которых объем основной памяти зачастую существенно превышал 64 Кбайта.
Вспомните хотя бы 16-разрядный компьютер PDP-11/70, к которому можно было подключить до 2 Мбайт основной памяти. Другим примером может служить выдающаяся отечественная ЭВМ БЭСМ-6, в которой при 15-разрядной адресации 6-байтовых (48-разрядных) машинных слов объем основной памяти был доведен до 256 Кбайт. Операционные системы этих компьютеров тем не менее поддерживали виртуальную память, основным смыслом которой являлось обеспечение защиты пользовательских программ одной от другой и предоставление операционной системе возможности динамически гибко перераспределять основную память между одновременно поддерживаемыми пользовательскими процессами.
Хотя известны и чисто программные реализации виртуальной памяти, это направление получило наиболее широкое развитие после получения соответствующей аппаратной поддержки. Идея аппаратной части механизма виртуальной памяти состоит в том, что адрес памяти, вырабатываемый командой, интерпретируется аппаратурой не как реальный адрес некоторого элемента основной памяти, а как некоторая структура, разные поля которой обрабатываются разным образом.
В наиболее простом и наиболее часто используемом случае страничной виртуальной памяти каждая виртуальная память (виртуальная память каждого процесса) и физическая основная память представляются состоящими из наборов блоков или страниц одинакового размера. Для удобства реализации размер страницы всегда выбирается равным числу, являющемуся степенью 2. Тогда, если общая длина виртуального адреса есть N (в последние годы это тоже всегда некоторая степень 2 - 16, 32, 64), а размер страницы есть 2M), то виртуальный адрес рассматривается как структура, состоящая из двух полей: первое поле занимает (N-M+1) разрядов адреса и задает номер страницы виртуальной памяти, второе поле занимает (M-1) разрядов и задает смещение внутри страницы до адресуемого элемента памяти (в большинстве случаев - байта). Аппаратная интерпретация виртуального адреса показана на рисунке 3.1.
Рисунок иллюстрирует механизм на концептуальном уровне, не вдаваясь в детали по поводу того, что из себя представляет и где хранится таблица страниц. Мы не будем рассматривать возможные варианты, а лишь заметим, что в большинстве современных компьютеров со страничной организацией виртуальной памяти все таблицы страниц хранятся в основной памяти, а быстрота доступа к элементам таблицы текущей виртуальной памяти достигается за счет наличия сверхбыстродействующей буферной памяти (кэша).
Для полноты изложения, но не вдаваясь в детали, заметим, что существуют две другие схемы организации виртуальной памяти: сегментная и сегментно-страничная. При сегментной организации виртуальный адрес по-прежнему состоит из двух полей - номера сегмента и смещения внутри сегмента. Отличие от страничной организации состоит в том, что сегменты виртуальной памяти могут быть разного размера. В элементе таблицы сегментов помимо физического адреса начала сегмента (если виртуальный сегмент содержится в основной памяти) содержится длина сегмента. Если размер смещения в виртуальном адресе выходит за пределы размера сегмента, возникает прерывание. Понятно, что компьютер с сегментной организацией виртуальной памяти можно использовать как компьютер со страничной организацией, если использовать сегменты одного размера.
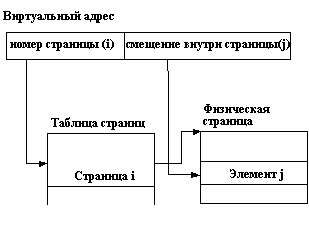
Рис. 3.1. Схема страничной организации виртуальной памяти
При сегментно-страничной организации виртуальной памяти происходит двухуровневая трансляция виртуального адреса в физический. В этом случае виртуальный адрес состоит из трех полей: номера сегмента виртуальной памяти, номера страницы внутри сегмента и смещения внутри страницы. Соответственно, используются две таблицы отображения - таблица сегментов, связывающая номер сегмента с таблицей страниц, и отдельная таблица страниц для каждого сегмента (рисунок 3.2).
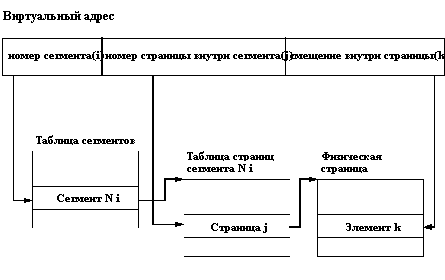
Рис. 3.2. Схема сегментно-страничной организации виртуальной памяти
Сегментно-страничная организация виртуальной памяти позволяла совместно использовать одни и те же сегменты данных и программного кода в виртуальной памяти разных задач (для каждой виртуальной памяти существовала отдельная таблица сегментов, но для совместно используемых сегментов поддерживались общие таблицы страниц).
В дальнейшем рассмотрении мы ограничимся проблемами управления страничной виртуальной памяти. С небольшими коррективами все обсуждаемые ниже методы и алгоритмы относятся и к сегментной, и сегментно-страничной организациям.
Как же достигается возможность наличия виртуальной памяти с размером, существенно превышающим размер оперативной памяти? В элементе таблицы страниц может быть установлен специальный флаг (означающий отсутствие страницы), наличие которого заставляет аппаратуру вместо нормального отображения виртуального адреса в физический прервать выполнение команды и передать управление соответствующему компоненту операционной системы. Английский термин "demand paging" (листание по требованию) достаточно точно характеризует функции, выполняемые этим компонентом. Когда программа обращается к виртуальной странице, отсутствующей в основной памяти, т.е. "требует" доступа к данным или программному коду, операционная система удовлетворяет это требование путем выделения страницы основной памяти, перемещения в нее копии страницы, находящейся во внешней памяти, и соответствующей модификации элемента таблицы страниц. После этого происходит "возврат из прерывания", и команда, по "требованию" которой выполнялись эти действия, продолжает свое выполнение.
Наиболее ответственным действием описанного процесса является выделение страницы основной памяти для удовлетворения требования доступа к отсутствующей в основной памяти виртуальной странице. Напомним, что мы рассматриваем ситуацию, когда размер каждой виртуальной памяти может существенно превосходить размер основной памяти. Это означает, что при выделении страницы основной памяти с большой вероятностью не удастся найти свободную (не приписанную к какой-либо виртуальной памяти) страницу. В этом случае операционная система должна в соответствии с заложенными в нее критериями (совокупность этих критериев принято называть "политикой замещения", а основанный на них алгоритм замещения - "алгоритмом подкачки") найти некоторую занятую страницу основной памяти, переместить в случае надобности ее содержимое во внешнюю память, должным образом модифицировать соответствующий элемент соответствующей таблицы страниц и после этого продолжить процесс удовлетворения доступа к странице.
Существует большое количество разнообразных алгоритмов подкачки. Объем этого курса не позволяет рассмотреть их подробно. Соответствующий материал можно найти в изданных на русском языке книгах по операционным системам Цикритзиса и Бернстайна, Дейтела и Краковяка. Однако, чтобы вернуться к описанию конкретных методов управления виртуальной памятью, применяемых в ОС UNIX, мы все же приведем некоторую краткую классификацию алгоритмов подкачки.
Во-первых, алгоритмы подкачки делятся на глобальные и локальные. При использовании глобальных алгоритмов операционная система при потребности замещения ищет страницу основной памяти среди всех страниц, независимо от их принадлежности к какой-либо виртуальной памяти. Локальные алгоритмы предполагают, что если возникает требование доступа к отсутствующей в основной памяти странице виртуальной памяти ВП1, то страница для замещения будет искаться только среди страниц основной памяти, приписанных к той же виртуальной памяти ВП1.
Наиболее распространенными традиционными алгоритмами (как в глобальном, так в локальном вариантах) являются алгоритмы FIFO (First In First Out) и LRU (Least Recently Used). При использовании алгоритма FIFO для замещения выбирается страница, которая дольше всего остается приписанной к виртуальной памяти. Алгоритм LRU предполагает, что замещать следует ту страницу, к которой дольше всего не происходили обращения. Хотя интуитивно кажется, что критерий алгоритма LRU является более правильным, известны ситуации, в которых алгоритм FIFO работает лучше (и, кроме того, он гораздо более дешево реализуется).
Заметим еще, что при использовании глобальных алгоритмов, вне зависимости от конкретного применяемого алгоритма, возможны и теоретически неизбежны критические ситуации, которые называются по-английски thrashing (несмотря на множество попыток, хорошего русского эквивалента так и не удалось придумать). Рассмотрим простой пример. Пусть на компьютере в мультипрограммном режиме выполняются два процесса - П1 в виртуальной памяти ВП1 и П2 в виртуальной памяти ВП2, причем суммарный размер ВП1 и ВП2 больше размеров основной памяти. Предположим, что в момент времени t1 в процессе П1 возникает требование виртуальной страницы ВС1. Операционная система обрабатывает соответствующее прерывание и выбирает для замещения страницу основной памяти С2, приписанную к виртуальной странице ВС2 виртуальной памяти ВП2 (т.е. в элементе таблицы страниц, соответствующем ВС2, проставляется флаг отсутствия страницы). Для полной обработки требования доступа к ВС1 в общем случае потребуется два обмена с внешней памятью (первый, чтобы записать текущее содержимое С2, второй - чтобы прочитать копию ВС1). Поскольку операционная система поддерживает мультипрограммный режим работы, то во время выполнения обменов доступ к процессору получит процесс П2, и он, вполне вероятно, может потребовать доступа к своей виртуальной странице ВС2 (которую у него только что отняли). Опять будет обрабатываться прерывание, и ОС может заменить некоторую страницу основной памяти С3, которая приписана к виртуальной странице ВС3 в ВП1. Когда закончатся обмены, связанные с обработкой требования доступа к ВС1, возобновится процесс П1, и он, вполне вероятно, потребует доступа к своей виртуальной странице ВС3 (которую у него только что отобрали). И так далее. Общий эффект состоит в том, что непрерывно работает операционная система, выполняя бесчисленные и бессмысленные обмены с внешней памятью, а пользовательские процессы П1 и П2 практически не продвигаются.
Понятно, что при использовании локальных алгоритмов ситуация thrashing, затрагивающая несколько процессов, невозможна. Однако в принципе возможна аналогичная ситуация внутри одной виртуальной памяти: ОС может каждый раз замещать ту страницу, к которой процесс обратится в следующий момент времени.
Единственным алгоритмом, теоретически гарантирующим отсутствие thrashing, является так называемый "оптимальный алгоритм Биледи" (по имени придумавшего его венгерского математика). Алгоритм заключается в том, что для замещения следует выбирать страницу, к которой в будущем наиболее долго не будет обращений. Понятно, что в динамической среде операционной системы точное знание будущего невозможно, и в этом контексте алгоритм Биледи представляет только теоретический интерес (хотя он с успехом применяется практически, например, в компиляторах для планирования использования регистров).
В 1968 году американский исследователь Питер Деннинг сформулировал принцип локальности ссылок (называемый принципом Деннинга) и выдвинул идею алгоритма подкачки, основанного на понятии рабочего набора. В некотором смысле предложенный им подход является практически реализуемой аппроксимацией оптимального алгоритма Биледи. Принцип локальности ссылок (недоказуемый, но подтверждаемый на практике) состоит в том, что если в период времени (T-t, T) программа обращалась к страницам (С1, С2, ..., Сn), то при надлежащем выборе t с большой вероятностью эта программа будет обращаться к тем же страницам в период времени (T, T+t). Другими словами, принцип локальности утверждает, что если не слишком далеко заглядывать в будущее, то можно хорошо его прогнозировать исходя из прошлого. Набор страниц (С1, С2, ..., Сn) называется рабочим набором программы (или, правильнее, соответствующего процесса) в момент времени T. Понятно, что с течением времени рабочий набор процесса может изменяться (как по составу страниц, так и по их числу). Идея алгоритма подкачки Деннинга (иногда называемого алгоритмом рабочих наборов) состоит в том, что операционная система в каждый момент времени должна обеспечивать наличие в основной памяти текущих рабочих наборов всех процессов, которым разрешена конкуренция за доступ к процессору. Мы не будем вдаваться в технические детали алгоритма, а лишь заметим следующее. Во-первых, полная реализация алгоритма Деннинга практически гарантирует отсутствие thrashing. Во-вторых, алгоритм реализуем (известна, по меньшей мере, одна его полная реализация, которая однако потребовала специальной аппаратной поддержки). В-третьих, полная реализация алгоритма Деннинга вызывает очень большие накладные расходы.
Поэтому на практике применяются облегченные варианты алгоритмов подкачки, основанных на идее рабочего набора. Один из таких вариантов применяется и в ОС UNIX (насколько нам известно, во всех версиях системы, относящихся к ветви System V). Мы кратко опишем этот вариант в п. 3.1.3.
Материал, приведенный в данном разделе, хотя и не отражает в полном объеме все проблемы и решения, связанные с управлением виртуальной памятью, достаточен для того, чтобы осознать важность и сложность соответствующих компонентов операционной системы. В любой операционной системе управление виртуальной памятью занимает центральное место. Когда-то Игорь Силин (основной разработчик известной операционной системы Дубна для БЭСМ-6) выдвинул тезис, известный в народе как "Тезис Силина": "Расходы, затраченные на управление виртуальной памятью, окупаются". Я думаю, что любой специалист в области операционных систем согласится с истинностью этого тезиса.
Понятно, что и разработчики ОС UNIX уделяли большое внимание поискам простых и эффективных механизмов управления виртуальной памятью (в области операционных систем абсолютно истинным является утверждение, что любое хорошее решение обязано быть простым). Но основной проблемой было то, что UNIX должен был быть мобильной операционной системой, легко переносимой на разные аппаратные платформы. Хотя на концептуальном уровне все аппаратные механизмы поддержки виртуальной памяти практически эквивалентны, реальные реализации часто весьма различаются. Невозможно создать полностью машинно-независимый компонент управления виртуальной памятью. С другой стороны, имеются существенные части программного обеспечения, связанного с управлением виртуальной памятью, для которых детали аппаратной реализации совершенно не важны. Одним из достижений ОС UNIX является грамотное и эффективное разделение средств управления виртуальной памятью на аппаратно-независимую и аппаратно-зависимую части. Коротко рассмотрим, что и каким образом удалось включить в аппаратно-независимую часть подсистемы управления виртуальной памятью ОС UNIX (ниже мы умышленно опускаем технические детали и упрощаем некоторые аспекты).
Основная идея состоит в том, что ОС UNIX опирается на некоторое собственное представление организации виртуальной памяти, которое используется в аппаратно-независимой части подсистемы управления виртуальной памятью и связывается с конкретной аппаратной реализацией с помощью аппаратно-зависимой части. В чем же состоит это абстрактное представление виртуальной памяти?
Во-первых, виртуальная память каждого процесса представляется в виде набора сегментов (рисунок 3.3).

Рис. 3.3. Сегментная структура виртуального адресного пространства
Как видно из рисунка, виртуальная память процесса ОС UNIX разбивается на сегменты пяти разных типов. Три типа сегментов обязательны для каждой виртуальной памяти, и сегменты этих типов присутствуют в виртуальной памяти в одном экземпляре для каждого типа. Сегмент программного кода содержит только команды. Реально в него помещается соответствующий сегмент выполняемого файла, который указывался в качестве параметра системного вызова exec для данного процесса. Сегмент программного кода не может модифицироваться в ходе выполнения процесса и потому возможно использование одного экземпляра кода для разных процессов.
Сегмент данных содержит инициализированные и неинициализированные статические переменные программы, выполняемой в данном процессе (на этом уровне изложения под статическими переменными лучше понимать области виртуальной памяти, адреса которых фиксируются в программе при ее загрузке и действуют на протяжении всего ее выполнения). Понятно, что поскольку речь идет о переменных, содержимое сегмента данных может изменяться в ходе выполнения процесса, следовательно, к сегменту должен обеспечиваться доступ и по чтению, и по записи. С другой стороны, поскольку мы говорим о собственных переменных данной программы, нельзя разрешить нескольким процессам совместно использовать один и тот же сегмент данных (по причине несогласованного изменения одних и тех же переменных разными процессами ни один из них не мог бы успешно завершиться).
Сегмент стека - это область виртуальной памяти, в которой размещаются автоматические переменные программы, явно или неявно в ней присутствующие. Этот сегмент, очевидно, должен быть динамическим (т.е. доступным и по чтению, и по записи), и он, также очевидно, должен быть частным (приватным) сегментом процесса.
Разделяемый сегмент виртуальной памяти образуется при подключении к ней сегмента разделяемой памяти (см. п. 3.4.1). По определению, такие сегменты предназначены для координированного совместного использования несколькими процессами. Поэтому разделяемый сегмент должен допускать доступ по чтению и по записи и может разделяться несколькими процессами.
Сегменты файлов, отображаемых в виртуальную память (см. п. 2.4.5), представляют собой разновидность разделяемых сегментов. Разница состоит в том, что если при необходимости освободить оперативную память страницы разделяемых сегментов копируются ("откачиваются") в специальную системную область подкачки (swapping space) на диске, то страницы сегментов файлов, отображаемых в виртуальную память, в случае необходимости откачиваются прямо на свое место в области внешней памяти, занимаемой файлом. Такие сегменты также допускают доступ и по чтению, и по записи и являются потенциально совместно используемыми.
На аппаратно-независимом уровне сегментная организация виртуальной памяти каждого процесса описывается структурой as, которая содержит указатель на список описателей сегментов, общий текущий размер виртуальной памяти (т.е. суммарный размер всех существующих сегментов), текущий размер физической памяти, которую процесс занимает в данный момент времени, и наконец, указатель на некоторую аппаратно-зависимую структуру, данные которой используются при отображении виртуальных адресов в физические. Описатель каждого сегмента (несколько огрубляя) содержит индивидуальные характеристики сегмента, в том числе, виртуальный адрес начала сегмента (каждый сегмент занимает некоторую непрерывную область виртуальной памяти), размер сегмента в байтах, список операций, которые можно выполнять над данным сегментом, статус сегмента (например, в каком режиме к нему возможен доступ, допускается ли совместное использование и т.д.), указатель на таблицу описателей страниц сегмента и т.д. Кроме того, описатель каждого сегмента содержит прямые и обратные ссылки по списку описателей сегментов данной виртуальной памяти и ссылку на общий описатель виртуальной памяти as.
На уровне страниц поддерживается два вида описательных структур. Для каждой страницы физической оперативной памяти существует описатель, входящий в один из трех списков. Первый список включает описатели страниц, не допускающих модификации или отображаемых в область внешней памяти какого-либо файла (например, страницы сегментов программного кода или страницы сегмента файла, отображаемого в виртуальную память). Для таких страниц не требуется пространство в области подкачки системы; они либо вовсе не требуют откачки (перемещения копии во внешнюю память), либо откачка производится в другое место. Второй список - это список описателей свободных страниц, т.е. таких страниц, которые не подключены ни к одной виртуальной памяти. Такие страницы свободны для использования и могут быть подключены к любой виртуальной памяти. Наконец, третий список страниц включает описатели так называемых анонимных страниц, т.е. таких страниц, которые могут изменяться, но для которых нет "родного" места во внешней памяти.
В любом описателе физической страницы сохраняются копии признаков обращения и модификации страницы, вырабатываемых конкретной используемой аппаратурой.
Для каждого сегмента поддерживается таблица отображения, связывающая адреса входящих в него виртуальных страниц с описателями соответствующих им физических страниц из первого или третьего списков описателей физических страниц для виртуальных страниц, присутствующих в основной памяти, или с адресами копий страниц во внешней памяти для виртуальных страниц, отсутствующих в основной памяти. (Правильнее сказать, что поддерживается отдельная таблица отображения для каждого частного сегмента и одна общая таблица отображения для каждого разделяемого сегмента.)
Введение подобной обобщенной модели организации виртуальной памяти и тщательное продумывание связи аппаратно-независимой и аппаратно-зависимой частей подсистемы управления виртуальной памятью позволило добиться того, что обращения к памяти, не требующие вмешательства операционной системы, производятся, как и полагается, напрямую с использованием конкретных аппаратных средств. Вместе с тем, все наиболее ответственные действия операционной системы, связанные с управлением виртуальной памятью, выполняются в аппаратно-независимой части с необходимыми взаимодействиями с аппаратно-зависимой частью.
Конечно, в результате сложность переноса той части ОС UNIX, которая относится к управлению виртуальной памятью, определяется сложностью написания аппаратно-зависимой части. Чем ближе архитектура аппаратуры, поддерживающей виртуальную память, к абстрактной модели виртуальной памяти ОС UNIX, тем проще перенос. Для справедливости заметим, что в подавляющем большинстве современных компьютеров аппаратура выполняет функции, существенно превышающие потребности модели UNIX, так что создание новой аппаратно-зависимой части подсистемы управления виртуальной памятью ОС UNIX в большинстве случаев не является чрезмерно сложной задачей.
Как мы упоминали в конце п. 3.1.1, в ОС UNIX используется некоторый облегченный вариант алгоритма подкачки, основанный на использовании понятия рабочего набора. Основная идея заключается в оценке рабочего набора процесса на основе использования аппаратно (а в некоторых реализациях - программно) устанавливаемых признаков обращения к страницам основной памяти. (Заметим, что в этом подразделе при описании алгоритма мы не различаем функции аппаратно-независимого и аппаратно-зависимого компонентов подсистемы управления виртуальной памятью.)
Периодически для каждого процесса производятся следующие действия. Просматриваются таблицы отображения всех сегментов виртуальной памяти этого процесса. Если элемент таблицы отображения содержит ссылку на описатель физической страницы, то анализируется признак обращения. Если признак установлен, то страница считается входящей в рабочий набор данного процесса, и сбрасывается в нуль счетчик старения данной страницы. Если признак не установлен, то к счетчику старения добавляется единица, а страница приобретает статус кандидата на выход из рабочего набора процесса. Если при этом значение счетчика достигает некоторого (различающегося в разных реализациях) критического значения, страница считается вышедшей из рабочего набора процесса, и ее описатель заносится в список страниц, которые можно откачать (если это требуется) во внешнюю память. По ходу просмотра элементов таблиц отображения в каждом из них признак обращения гасится.
Откачку страниц, не входящих в рабочие наборы процессов, производит специальный системный процесс-stealer. Он начинает работать, когда количество страниц в списке свободных страниц достигает установленного нижнего порога. Функцией этого процесса является анализ необходимости откачки страницы (на основе признака изменения) и запись копии страницы (если это требуется) в соответствующую область внешней памяти (т.е. либо в системную область подкачки - swapping space для анонимных страниц, либо в некоторый блок файловой системы для страницы, входящей в сегмент отображаемого файла).
Очевидно, рабочий набор любого процесса может изменяться во время его выполнения. Другими словами, возможна ситуация, когда процесс обращается к виртуальной странице, отсутствующей в основной памяти. В этом случае, как обычно, возникает аппаратное прерывание, в результате которого начинает работать операционная система. Дальнейший ход событий зависит от обстоятельств. Если список описателей свободных страниц не пуст, то из него выбирается некоторый описатель, и соответствующая страница подключается к виртуальной памяти процесса (конечно, после считывания из внешней памяти содержимого копии этой страницы, если это требуется).
Но если возникает требование страницы в условиях, когда список описателей свободных страниц пуст, то начинает работать механизм своппинга. Основной повод для применения другого механизма состоит в том, что простое отнятие страницы у любого процесса (включая тот, который затребовал бы страницу) потенциально вело бы к ситуации thrashing, поскольку разрушало бы рабочий набор некоторого процесса). Любой процесс, затребовавший страницу не из своего текущего рабочего набора, становится кандидатом на своппинг. Ему больше не предоставляются ресурсы процессора, и описатель процесса ставится в очередь к системному процессу-swapper. Конечно, в этой очереди может находиться несколько процессов. Процесс-swapper по очереди осуществляет полный своппинг этих процессов (т.е. откачку всех страниц их виртуальной памяти, которые присутствуют в основной памяти), помещая соответствующие описатели физических страниц в список свободных страниц, до тех пор, пока количество страниц в этом списке не достигнет установленного в системе верхнего предела. После завершения полного своппинга каждого процесса одному из процессов из очереди к процессу-swapper дается возможность попытаться продолжить свое выполнение (в расчете на то, что свободной памяти уже может быть достаточно).
Заметим, что мы описали наиболее сложный алгоритм, когда бы то ни было использовавшийся в ОС UNIX. В последней "фактически стандартной" версии ОС UNIX (System V Release 4) используется более упрощенный алгоритм. Это глобальный алгоритм, в котором вероятность thrashing погашается за счет своппинга. Используемый алгоритм называется NRU (Not Recently Used) или clock. Смысл алгоритма состоит в том, что процесс-stealer периодически очищает признаки обращения всех страниц основной памяти, входящих в виртуальную память процессов (отсюда название "clock"). Если возникает потребность в откачке (т.е. достигнут нижний предел размера списка описателей свободных страниц), то stealer выбирает в качестве кандидатов на откачку прежде всего те страницы, к которым не было обращений по записи после последней "очистки" и у которых нет признака модификации (т.е. те, которые можно дешевле освободить). Во вторую очередь выбираются страницы, которые действительно нужно откачивать. Параллельно с этим работает описанный выше алгоритм своппинга, т.е. если возникает требование страницы, а свободных страниц нет, то соответствующий процесс становится кандидатом на своппинг.
В заключение затронем еще одну важную тему, непосредственно связанную с управлением виртуальной памятью - копирование страниц при попытке записи (copy on write). Как мы отмечали в п. 2.1.7, при выполнении системного вызова fork() ОС UNIX образует процесс-потомок, являющийся полной копией своего предка. Тем не менее, у потомка своя собственная виртуальная память, и те сегменты, которые должны быть его частными сегментами, в принципе должны были бы полностью скопироваться. Однако, несмотря на то, что частные сегменты допускают доступ и по чтению, и по записи, ОС не знает, будет ли предок или потомок реально производить запись в каждую страницу таких сегментов. Поэтому было бы неразумно производить полное копирование частных сегментов во время выполнения системного вызова fork().
Поэтому в таких случаях используется техника копирования страниц при попытке записи. Несмотря на то, что в сегмент запись разрешена, для каждой его страницы устанавливается блокировка записи. Тем самым, во время попытки выполнения записи возникает прерывание, и ОС на основе анализа статуса соответствующего сегмента принимает решение о выделении новой страницы, копировании на нее содержимого оригинальной страницы и о включении этой новой страницы на место старой в виртуальную память либо процесса-предка, либо процесса-потомка (в зависимости от того, кто из них пытался писать).
На этом мы заканчиваем краткое описание механизма управления виртуальной памятью в ОС UNIX. Еще раз подчеркнем, что мы опустили множество важных технических деталей, стремясь продемонстрировать наиболее важные принципиальные решения.
В операционной системе UNIX традиционно поддерживается классическая схема мультипрограммирования. Система поддерживает возможность параллельного (или квази-параллельного в случае наличия только одного аппаратного процессора) выполнения нескольких пользовательских программ. Каждому такому выполнению соответствует процесс операционной системы. Каждый процесс выполняется в собственной виртуальной памяти, и, тем самым, процессы защищены один от другого, т.е. один процесс не в состоянии неконтроллируемым образом прочитать что-либо из памяти другого процесса или записать в нее. Однако контролируемые взаимодействия процессов допускаются системой, в том числе за счет возможности разделения одного сегмента памяти между виртуальной памятью нескольких процессов.
Конечно, не менее важно (а на самом деле, существенно более важно) защищать саму операционную систему от возможности ее повреждения каким бы то ни было пользовательским процессом. В ОС UNIX это достигается за счет того, что ядро системы работает в собственном "ядерном" виртуальном пространстве, к которому не может иметь доступа ни один пользовательский процесс.
Ядро системы предоставляет возможности (набор системных вызовов) для порождения новых процессов, отслеживания окончания порожденных процессов и т.д. С другой стороны, в ОС UNIX ядро системы - это полностью пассивный набор программ и данных. Любая программа ядра может начать работать только по инициативе некоторого пользовательского процесса (при выполнении системного вызова), либо по причине внутреннего или внешнего прерывания (примером внутреннего прерывания может быть прерывание из-за отсутствия в основной памяти требуемой страницы виртуальной памяти пользовательского процесса; примером внешнего прерывания является любое прерывание процессора по инициативе внешнего устройства). В любом случае считается, что выполняется ядерная часть обратившегося или прерванного процесса, т.е. ядро всегда работает в контексте некоторого процесса.
В последние годы в связи с широким распространением так называемых симметричных мультипроцессорных архитектур компьютеров (Symmetric Multiprocessor Architectures - SMP) в ОС UNIX был внедрен механизм легковесных процессов (light-weight processes), или нитей, или потоков управления (threads). Говоря по-простому, нить - это процесс, выполняющийся в виртуальной памяти, используемой совместно с другими нитями того же "тяжеловесного" (т.е. обладающего отдельной виртуальной памятью) процесса. В принципе, легковесные процессы использовались в операционных системах много лет назад. Уже тогда стало ясно, что программирование с неконтролируемым использованием общей памяти приносит больше хлопот и неприятностей, чем пользы, по причине необходимости использования явных примитивов синхронизации.
Однако, до настоящего времени в практику программистов так и не были внедрены более безопасные методы параллельного программирования, а реальные возможности мультипроцессорных архитектур для обеспечения распараллеливания нужно было как-то использовать. Поэтому опять в обиход вошли легковесные процессы, которые теперь получили название threads (нити). Наиболее важно (с нашей точки зрения) то, что для внедрения механизма нитей потребовалась существенная переделка ядра. Разные производители аппаратуры и программного обеспечения стремились как можно быстрее выставить на рынок продукт, пригодный для эффективного использования на SMP-платформах. Поэтому версии ОС UNIX опять несколько разошлись.
Все эти вопросы мы обсудим более подробно в данном разделе.
Каждому процессу соответствует контекст, в котором он выполняется. Этот контекст включает содержимое пользовательского адресного пространства - пользовательский контекст (т.е. содержимое сегментов программного кода, данных, стека, разделяемых сегментов и сегментов файлов, отображаемых в виртуальную память), содержимое аппаратных регистров - регистровый контекст (регистр счетчика команд, регистр состояния процессора, регистр указателя стека и регистры общего назначения), а также структуры данных ядра (контекст системного уровня), связанные с этим процессом. Контекст процесса системного уровня в ОС UNIX состоит из "статической" и "динамических" частей. Для каждого процесса имеется одна статическая часть контекста системного уровня и переменное число динамических частей.
Статическая часть контекста процесса системного уровня включает следующее:
и т.д.
Динамическая часть контекста процесса - это один или несколько стеков, которые используются процессом при его выполнении в режиме ядра. Число ядерных стеков процесса соответствует числу уровней прерывания, поддерживаемых конкретной аппаратурой.
Основной проблемой организации многопользовательского (правильнее сказать, мультипрограммного) режима в любой операционной системе является организация планирования "параллельного" выполнения нескольких процессов. Операционная система должна обладать четкими критериями для определения того, какому готовому к выполнению процессу и когда предоставить ресурс процессора.
Исторически ОС UNIX является системой разделения времени, т.е. система должна прежде всего "справедливо" разделять ресурсы процессора(ов) между процессами, относящимися к разным пользователям, причем таким образом, чтобы время реакции каждого действия интерактивного пользователя находилось в допустимых пределах. Однако в последнее время возрастает тенденция к использованию ОС UNIX в приложениях реального времени, что повлияло и на алгоритмы планирования. Ниже мы опишем общую (без технических деталей) схему планирования разделения ресурсов процессора(ов) между процессами в UNIX System V Release 4.
Наиболее распространенным алгоритмом планирования в системах разделения времени является кольцевой режим (round robin). Основной смысл алгоритма состоит в том, что время процессора делится на кванты фиксированного размера, а процессы, готовые к выполнению, выстраиваются в кольцевую очередь. У этой очереди имеются два указателя - начала и конца. Когда процесс, выполняющийся на процессоре, исчерпывает свой квант процессорного времени, он снимается с процессора, ставится в конец очереди, а ресурсы процессора отдаются процессу, находящемуся в начале очереди. Если выполняющийся на процессоре процесс откладывается (например, по причине обмена с некоторым внешнем устройством) до того, как он исчерпает свой квант, то после повторной активизации он становится в конец очереди (не смог доработать - не вина системы). Это прекрасная схема разделения времени в случае, когда все процессы одновременно помещаются в оперативной памяти.
Однако ОС UNIX всегда была рассчитана на то, чтобы обслуживать больше процессов, чем можно одновременно разместить в основной памяти. Другими словами, часть процессов, потенциально готовых выполняться, размещалась во внешней памяти (куда образ памяти процесса попадал в результате своппинга). Поэтому требовалась несколько более гибкая схема планирования разделения ресурсов процессора(ов). В результате было введено понятие приоритета. В ОС UNIX значение приоритета определяет, во-первых, возможность процесса пребывать в основной памяти и на равных конкурировать за процессор. Во-вторых, от значения приоритета процесса, вообще говоря, зависит размер временного кванта, который предоставляется процессу для работы на процессоре при достижении своей очереди. В-третьих, значение приоритета, влияет на место процесса в общей очереди процессов к ресурсу процессора(ов).
Схема разделения времени между процессами с приоритетами в общем случае выглядит следующим образом. Готовые к выполнению процессы выстраиваются в очередь к процессору в порядке уменьшения своих приоритетов. Если некоторый процесс отработал свой квант процессорного времени, но при этом остался готовым к выполнению, то он становится в очередь к процессору впереди любого процесса с более низким приоритетом, но вслед за любым процессом, обладающим тем же приоритетом. Если некоторый процесс активизируется, то он также ставится в очередь вслед за процессом, обладающим тем же приоритетом. Весь вопрос в том, когда принимать решение о своппинге процесса, и когда возвращать в оперативную память процесс, содержимое памяти которого было ранее перемещено во внешнюю память.
Традиционное решение ОС UNIX состоит в использовании динамически изменяющихся приоритетов. Каждый процесс при своем образовании получает некоторый устанавливаемый системой статический приоритет, который в дальнейшем может быть изменен с помощью системного вызова nice (см. п. 3.1.3). Этот статический приоритет является основой начального значения динамического приоритета процесса, являющегося реальным критерием планирования. Все процессы с динамическим приоритетом не ниже порогового участвуют в конкуренции за процессор (по схеме, описанной выше). Однако каждый раз, когда процесс успешно отрабатывает свой квант на процессоре, его динамический приоритет уменьшается (величина уменьшения зависит от статического приоритета процесса). Если значение динамического приоритета процесса достигает некоторого нижнего предела, он становится кандидатом на откачку (своппинг) и больше не конкурирует за процессор.
Процесс, образ памяти которого перемещен во внешнюю память, также обладает динамическим приоритетом. Этот приоритет не дает процессу право конкурировать за процессор (да это и невозможно, поскольку образ памяти процесса не находится в основной памяти), но он изменяется, давая в конце концов процессу возможность вновь вернуться в основную память и принять участие в конкуренции за процессор. Правила изменения динамического приоритета для процесса, перемещенного во внешнюю память, в принципе, очень просты. Чем дольше образ процесса находится во внешней памяти, тем более высок его динамический приоритет (конкретное значение динамического приоритета, конечно, зависит от его статического приоритета). Конечно, раньше или позже значение динамического приоритета такого процесса перешагнет через некоторый порог, и тогда система принимает решение о необходимости возврата образа процесса в основную память. После того, как в результате своппинга будет освобождена достаточная по размерам область основной памяти, процесс с приоритетом, достигшим критического значения, будет перемещен в основную память и будет в соответствии со своим приоритетом конкурировать за процессор.
Как вписываются в эту схему процессы реального времени? Прежде всего, нужно разобраться, что понимается под концепцией "реального времени" в ОС UNIX. Известно, что существуют по крайней мере два понимания термина - " мягкое реальное время (soft realtime)" и " жесткое реальное время (hard realtime)".
Жесткое реальное время означает, что каждое событие (внутреннее или внешнее), происходящее в системе (обращение к ядру системы за некоторой услугой, прерывание от внешнего устройства и т.д.), должно обрабатываться системой за время, не превосходящее верхнего предела времени, отведенного для таких действий. Режим жесткого реального времени требует задания четких временных характеристик процессов, и эти временные характеристики должны определять поведение планировщика распределения ресурсов процессора(ов) и основной памяти.
Режим мягкого реального времени, в отличие от этого, предполагает, что некоторые процессы (процессы реального времени) получают права на получение ресурсов основной памяти и процессора(ов), существенно превосходящие права процессов, не относящихся к категории процессов реального времени. Основная идея состоит в том, чтобы дать возможность процессу реального времени опередить в конкуренции за вычислительные ресурсы любой другой процесс, не относящийся к категории процессов реального времени. Отслеживание проблем конкуренции между различными процессами реального времени относится к функциям администратора системы и выходит за пределы этого курса.
В своих самых последних вариантах ОС UNIX поддерживает концепцию мягкого реального времени. Это делается способом, не выходящим за пределы основополагающего принципа разделения времени. Как мы отмечали выше, имеется некоторый диапазон значений статических приоритетов процессов. Некоторый поддиапазон этого диапазона включает значения статических приоритетов процессов реального времени. Процессы, обладающие динамическими приоритетами, основанными на статических приоритетах процессов реального времени, обладают следующими особенностями:
Тем самым своеобразным, но логичным образом в современных вариантах ОС UNIX одновременно реализована как возможность разделения времени для интерактивных процессов, так и возможность мягкого реального времени для процессов, связанных с реальным управлением поведением объектов в реальном времени.
Как свойственно операционной системе UNIX вообще, имеются две возможности управления процессами - с использованием командного языка (того или другого варианта Shell) и с использованием языка программирования с непосредственным использованием системных вызовов ядра операционной системы. Возможности командных языков мы будем обсуждать в пятой части этого курса, а пока сосредоточимся на базовых возможностях управления процессами на пользовательском уровне, предоставляемых ядром системы.
Прежде всего обрисуем общую схему возможностей пользователя, связанных с управлением процессами. Каждый процесс может образовать полностью идентичный подчиненный процесс с помощью системного вызова fork() и дожидаться окончания выполнения своих подчиненных процессов с помощью системного вызова wait. Каждый процесс в любой момент времени может полностью изменить содержимое своего образа памяти с помощью одной из разновидностей системного вызова exec (сменить образ памяти в соответствии с содержимым указанного файла, хранящего образ процесса (выполняемого файла)). Каждый процесс может установить свою собственную реакцию на "сигналы", производимые операционной системой в соответствие с внешними или внутренними событиями. Наконец, каждый процесс может повлиять на значение своего статического (а тем самым и динамического) приоритета с помощью системного вызова nice.
Для создания нового процесса используется системный вызов fork. В среде программирования нужно относиться к этому системному вызову как к вызову функции, возвращающей целое значение - идентификатор порожденного процесса, который затем может использоваться для управления (в ограниченном смысле) порожденным процессом. Реально, все процессы системы UNIX, кроме начального, запускаемого при раскрутке системы, образуются при помощи системного вызова fork.
Вот что делает ядро системы при выполнении системного вызова fork:
Понятно, что после создания процесса предок и потомок начинают жить своей собственной жизнью, произвольным образом изменяя свой контекст. В частности, и предок, и потомок могут выполнить какой-либо из вариантов системного вызова exec (см. ниже), приводящего к полному изменению контекста процесса.
Чтобы процесс-предок мог синхронизовать свое выполнение с выполнением своих процессов-потомков, существует системный вызов wait. Выполнение этого системного вызова приводит к приостановке выполнения процесса до тех пор, пока не завершится выполнение какого-либо из процессов, являющихся его потомками. В качестве прямого параметра системного вызова wait указывается адрес памяти (указатель), по которому должна быть возвращена информация, описывающая статус завершения очередного процесса-потомка, а ответным (возвратным) параметром является PID (идентификатор процесса) завершившегося процесса-потомка.
Сигнал - это способ информирования процесса со стороны ядра о происшествии некоторого события. Смысл термина "сигнал" состоит в том, что сколько бы однотипных событий в системе не произошло, по поводу каждой такой группы событий процессу будет подан ровно один сигнал. Т.е. сигнал означает, что определяемое им событие произошло, но не несет информации о том, сколько именно произошло однотипных событий.
Примерами сигналов (не исчерпывающими все возможности) являются следующие:
Для установки реакции на поступление определенного сигнала используется системный вызов
oldfunction = signal(signum, function),
где signum - это номер сигнала, на поступление которого устанавливается реакция (все возможные сигналы пронумерованы, каждому номеру соответствует собственное символическое имя; соответствующая информация содержится в документации к каждой конкретной системе UNIX), а function - адрес указываемой пользователем функции, которая должна быть вызвана системой при поступлении указанного сигнала данному процессу. Возвращаемое значение oldfunction - это адрес функции для реагирования на поступление сигнала signum, установленный в предыдущем вызове signal. Вместо адреса функции во входных параметрах можно задать 1 или 0. Задание единицы приводит к тому, что далее для данного процесса поступление сигнала с номером signum будет игнорироваться (это допускается не для всех сигналов). Если в качестве значения параметра function указан нуль, то после выполнения системного вызова signal первое же поступление данному процессу сигнала с номером signum приведет к завершению процесса (будет проинтерпретировано аналогично выполнению системного вызова exit, см. ниже).
Система предоставляет возможность для пользовательских процессов явно генерировать сигналы, направляемые другим процессам. Для этого используется системный вызов
kill(pid, signum)
(Этот системный вызов называется "kill", потому что наиболее часто применяется для того, чтобы принудительно закончить указанный процесс.) Параметр signum задает номер генерируемого сигнала (в системном вызове kill можно указывать не все номера сигналов). Параметр pid имеет следующие смысл:
Для завершения процесса по его собственной инициативе используется системный вызов
exit(status),
где status - это целое число, возвращаемое процессу-предку для его информирования о причинах завершения процесса-потомка (как описывалось выше, для получения информации о статусе завершившегося процесса-потомка в процессе-предке используется системный вызов wait). Системный вызов называется exit (т.е. "выход", поскольку считается, что любой пользовательский процесс запускается ядром системы (собственно, так оно и есть), и завершение пользовательского процесса - это окончательный выход из него в ядро.
Системный вызов exit может задаваться явно в любой точке процесса, но может быть и неявным. В частности, при программировании на языке Си возврат из функции main приводит к выполнению неявно содержащегося в программе системного вызова exit с некоторым предопределенным статусом. Кроме того, как отмечалось выше, можно установить такую реакцию на поступающие в процесс сигналы, когда приход определенного сигнала будет интерпретироваться как неявный вызов exit. В этом случае в качестве значения статуса указывается номер сигнала.
Возможности управления процессами, которые мы обсудили до этого момента, позволяют образовать новый процесс, являющийся полной копией процесса-предка (системный вызов fork); дожидаться завершения любого образованного таким образом процесса (системный вызов wait); порождать сигналы и реагировать на них (системные вызовы kill и signal); завершать процесс по его собственной инициативе (системный вызов exit). Однако пока остается непонятным, каким образом можно выполнить в образованном процессе произвольную программу. Понятно, что в принципе этого можно было бы добиться с помощью системного вызова fork, если образ памяти процесса-предка заранее построен так, что содержит все потенциально требуемые программы. Но, конечно, этот способ не является рациональным (хотя бы потому, что заведомо приводит к перерасходу памяти).
Для выполнения произвольной программы в текущем процессе используются системные вызовы семейства exec. Разные варианты exec слегка различаются способом задания параметров. Здесь мы не будем вдаваться в детали (за ними лучше обращаться к документации по конкретной реализации). Рассмотрим некоторый обобщенный случай системного вызова
exec(filename, argv, argc, envp)
Вот что происходит при выполнении этого системного вызова. Берется файл с именем filename (может быть указано полное или сокращенное имя файла). Этот файл должен быть выполняемым файлом, т.е. представлять собой законченный образ виртуальной памяти. Если это на самом деле так, то ядро ОС UNIX производит реорганизацию виртуальной памяти процесса, обратившегося к системному вызову exec, уничтожая в нем старые сегменты и образуя новые сегменты, в которые загружаются соответствующие разделы файла filename. После этого во вновь образованном пользовательском контексте вызывается функция main, которой, как и полагается, передаются параметры argv и argc, т.е. некоторый набор текстовых строк, заданных в качестве параметра системного вызова exec. Через параметр envp обновленный процесс может обращаться к переменным своего окружения.
Следует заметить, что при выполнении системного вызова exec не образуется новый процесс, а лишь меняется содержимое виртуальной памяти существующего процесса. Другими словами, меняется только пользовательский контекст процесса.
Полезные возможности ОС UNIX для общения родственных или независимо образованных процессов рассматриваются ниже в разделе 3.4.
Понятие "легковесного процесса" (light-weight process), или, как принято называть его в современных вариантах ОС UNIX, "thread" (нить, поток управления) давно известно в области операционных систем. Интуитивно понятно, что концепции виртуальной памяти и потока команд, выполняющегося в этой виртуальной памяти, в принципе, ортогональны. Ни из чего не следует, что одной виртуальной памяти должен соответствовать один и только один поток управления. Поэтому, например, в ОС Multics (раздел 1.1) допускалось (и являлось принятой практикой) иметь произвольное количество процессов, выполняемых в общей (разделяемой) виртуальной памяти.
Понятно, что если несколько процессов совместно пользуются некоторыми ресурсами, то при доступе к этим ресурсам они должны синхронизоваться (например, с использованием семафоров, см. п. 3.4.2). Многолетний опыт программирования с использованием явных примитивов синхронизации показал, что этот стиль "параллельного" программирования порождает серьезные проблемы при написании, отладке и сопровождении программ (наиболее трудно обнаруживаемые ошибки в программах обычно связаны с синхронизацией). Это явилось одной из причин того, что в традиционных вариантах ОС UNIX понятие процесса жестко связывалось с понятием отдельной и недоступной для других процессов виртуальной памяти. Каждый процесс был защищен ядром операционной системы от неконтролируемого вмешательства других процессов. Многие годы авторы ОС UNIX считали это одним из основных достоинств системы (впрочем, это мнение существует и сегодня).
Однако, связывание процесса с виртуальной памятью порождает, по крайней мере, две проблемы. Первая проблема связана с так называемыми системами реального времени. Такие системы, как правило, предназначены для одновременного управления несколькими внешними объектами и наиболее естественно представляются в виде совокупности "параллельно" (или "квази-параллельно") выполняемых потоков команд (т.е. взаимодействующих процессов). Однако, если с каждым процессом связана отдельная виртуальная память, то смена контекста процессора (т.е. его переключение с выполнения одного процесса на выполнение другого процесса) является относительно дорогостоящей операцией. Поэтому традиционный подход ОС UNIX препятствовал использованию системы в приложениях реального времени.
Второй (и может быть более существенной) проблемой явилось появление так называемых симметричных мультипроцессорных компьютерных архитектур (SMP - Symmetric Multiprocessor Architectures). В таких компьютерах физически присутствуют несколько процессоров, которые имеют одинаковые по скорости возможности доступа к совместно используемой основной памяти. Появление подобных машин на мировом рынке, естественно, поставило проблему их эффективного использования. Понятно, что при применении традиционного подхода ОС UNIX к организации процессов от наличия общей памяти не очень много толка (хотя при наличии возможностей разделяемой памяти (см. п. 3.4.1) об этом можно спорить). К моменту появления SMP выяснилось, что технология программирования все еще не может предложить эффективного и безопасного способа реального параллельного программирования. Поэтому пришлось вернуться к явному параллельному программированию с использованием параллельных процессов в общей виртуальной (а тем самым, и основной) памяти с явной синхронизацией.
Что же понимается под "нитью" (thread)? Это независимый поток управления, выполняемый в контексте некоторого процесса. Фактически, понятие контекста процесса, которое мы обсуждали в п. 3.1.1, изменяется следующим образом. Все, что не относится к потоку управления (виртуальная память, дескрипторы открытых файлов и т.д.), остается в общем контексте процесса. Вещи, которые характерны для потока управления (регистровый контекст, стеки разного уровня и т.д.), переходят из контекста процесса в контекст нити. Общая картина показана на рисунке 3.4.
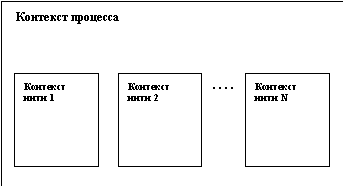
Рис. 3.4. Соотношение контекста процесса и контекстов нитей
Как видно из этого рисунка, все нити процесса выполняются в его контексте, но каждая нить имеет свой собственный контекст. Контекст нити, как и контекст процесса, состоит из пользовательской и ядерной составляющих. Пользовательская составляющая контекста нити включает индивидуальный стек нити. Поскольку нити одного процесса выполняются в общей виртуальной памяти (все нити процесса имеют равные права доступа к любым частям виртуальной памяти процесса), стек (сегмент стека) любой нити процесса в принципе не защищен от произвольного (например, по причине ошибки) доступа со стороны других нитей. Ядерная составляющая контекста нити включает ее регистровый контекст (в частности, содержимое регистра счетчика команд) и динамически создаваемые ядерные стеки.
Приведенное краткое обсуждение понятия нити кажется достаточным для того, чтобы понять, что внедрение в ОС UNIX механизма легковесных процессов требует существенных переделок ядра системы. (Всегда трудно внедрить в программу средства, для поддержки которых она не была изначально приспособлена.)
Хотя концептуально реализации механизма нитей в разных современных вариантах практически эквивалентны (да и что особенное можно придумать по поводу легковесных процессов?), технически и, к сожалению, в отношении интерфейсов эти реализации различаются. Мы не ставим здесь перед собой цели описать в деталях какую-либо реализацию, однако постараемся в общих чертах охарактеризовать разные подходы.
Начнем с того, что разнообразие механизмов нитей в современных вариантах ОС UNIX само по себе представляет проблему. Сейчас достаточно трудно говорить о возможности мобильного параллельного программирования в среде UNIX-ориентированных операционных систем. Если программист хочет добиться предельной эффективности (а он должен этого хотеть, если для целей его проекта приобретен дорогостоящий мультипроцессор), то он вынужден использовать все уникальные возможности используемой им операционной системы.
Для всех очевидно, что сегодняшняя ситуация далека от идеальной. Однако, по-видимому, ее было невозможно избежать, поскольку поставщики мультипроцессорных симметричных архитектур должны были как можно раньше предоставить своим покупателям возможности эффективного программирования, и времени на согласование решений просто не было (любых поставщиков прежде всего интересует объем продаж, а проблемы будущего оставляются на будущее).
Применяемые в настоящее время подходы зависят от того, насколько внимательно разработчики ОС относились к проблемам реального времени. (Возвращаясь к введению этого раздела, еще раз отметим, что здесь мы имеем в виду "мягкое" реальное время, т.е. программно-аппаратные системы, которые обеспечивают быструю реакцию на внешние события, но время реакции не установлено абсолютно строго.) Типичная система реального времени состоит из общего монитора, который отслеживает общее состояние системы и реагирует на внешние и внутренние события, и совокупности обработчиков событий, которые, желательно параллельно, выполняют основные функции системы.
Понятно, что от возможностей реального распараллеливания функций обработчиков зависят общие временные показатели системы. Если, например, при проектировании системы замечено, что типичной картиной является "одновременное" поступление в систему N внешних событий, то желательно гарантировать наличие реальных N устройств обработки, на которых могут базироваться обработчики. На этих наблюдениях основан подход компании Sun Microsystems.
В системе Solaris (правильнее говорить SunOS 4.x, поскольку Solaris в терминологии Sun представляет собой не операционную систему, а расширенную операционную среду) принят следующий подход. При запуске любого процесса можно потребовать резервирования одного или нескольких процессоров мультипроцессорной системы. Это означает, что операционная система не предоставит никакому другому процессу возможности выполнения на зарезервированном(ых) процессоре(ах). Независимо от того, готова ли к выполнению хотя бы одна нить такого процесса, зарезервированные процессоры не будут использоваться ни для чего другого.
Далее, при образовании нити можно закрепить ее за одним или несколькими процессорами из числа зарезервированных. В частности, таким образом в принципе можно привязать нить к некоторому фиксированному процессору. В общем случае некоторая совокупность потоков управления привязывается к некоторой совокупности процессоров так, чтобы среднее время реакции системы реального времени удовлетворяло внешним критериям. Очевидно, что это "ассемблерный" стиль программирования (слишком много перекладывается на пользователя), но зато он открывает широкие возможности перед разработчиками систем реального времени (которые, правда, после этого зависят не только от особенностей конкретной операционной системы, но и от конкретной конфигурации данной компьютерной установки). Подход Solaris преследует цели удовлетворить разработчиков систем "мягкого" (а, возможно, и "жесткого") реального времени, и поэтому фактически дает им в руки средства распределения критических вычислительных ресурсов.
В других подходах в большей степени преследуется цель равномерной балансировки загрузки мультипроцессора. В этом случае программисту не предоставляются средства явной привязки процессоров к процессам или нитям. Система допускает явное распараллеливание в пределах общей виртуальной памяти и "обещает", что по мере возможностей все процессоры вычислительной системы будут загружены равномерно. Этот подход обеспечивает наиболее эффективное использование общих вычислительных ресурсов мультипроцессора, но не гарантирует корректность выполнения систем реального времени (если не считать возможности установления специальных приоритетов реального времени, которые упоминались в п. 3.1.2).
Отметим существование еще одной аппаратно-программной проблемы, связанной с нитями (и не только с ними). Проблема связана с тем, что в существующих симметричных мультипроцессорах обычно каждый процессор обладает собственной сверхбыстродействующей буферной памятью (кэшем). Идея кэша, в общих чертах, состоит в том, чтобы обеспечить процессору очень быстрый (без необходимости выхода на шину доступа к общей оперативной памяти) доступ к наиболее актуальным данным. В частности, если программа выполняет запись в память, то это действие не обязательно сразу отображается в соответствующем элементе основной памяти; до поры до времени измененный элемент данных может содержаться только в локальном кэше того процессора, на котором выполняется программа. Конечно, это противоречит идее совместного использования виртуальной памяти нитями одного процесса (а также идее использования памяти, разделяемой между несколькими процессами, см. п. 3.4.1).
Это очень сложная проблема, относящаяся к области проблем "когерентности кэшей". Теоретически имеется много подходов к ее решению (например, аппаратное распознавание необходимости выталкивания записи из кэша с синхронным объявлением недействительным содержания всех кэшей, включающих тот же элемент данных). Однако на практике такие сложные действия не применяются, и обычным приемом является отмена режима кэширования в том случае, когда на разных процессорах мультипроцессорной системы выполняются нити одного процесса или процессы, использующие разделяемую память.
После введения понятия нити трансформируется само понятие процесса. Теперь лучше (и правильнее) понимать процесс ОС UNIX как некоторый контекст, включающий виртуальную память и другие системные ресурсы (включая открытые файлы), в котором выполняется, по крайней мере, один поток управления (нить), обладающий своим собственным (более простым) контекстом. Теперь ядро знает о существовании этих двух уровней контекстов и способно сравнительно быстро изменять контекст нити (не изменяя общего контекста процесса) и так же, как и ранее, изменять контекст процесса.
Последнее замечание относится к синхронизации выполнения нитей одного процесса (точнее было бы говорить о синхронизации доступа нитей к общим ресурсам процесса - виртуальной памяти, открытым файлам и т.д.). Конечно, можно пользоваться (сравнительно) традиционными средствами синхронизации (например, семафорами, см. п. 3.4.2). Однако оказывается, что система может предоставить для синхронизации нитей одного процесса более дешевые средства (поскольку все нити работают в общем контексте процесса). Обычно эти средства относятся к классу средств взаимного исключения (т.е. к классу семафоро-подобных средств). К сожалению, и в этом отношении к настоящему времени отсутствует какая-либо стандартизация.
Мы уже обсуждали проблемы организации ввода/вывода в ОС UNIX в п. 2.6.2. В этом разделе мы хотим рассмотреть этот вопрос немного более подробно, разъяснив некоторые технические детали. При этом нужно отдавать себе отчет, что в любом случае мы остаемся на концептуальном уровне. Если вам требуется написать драйвер некоторого внешнего устройства для некоторого конкретного варианта ОС UNIX, то неизбежно придется внимательно читать документацию. Тем не менее знание общих принципов будет полезно.
Традиционно в ОС UNIX выделяются три типа организации ввода/вывода и, соответственно, три типа драйверов. Блочный ввод/вывод главным образом предназначен для работы с каталогами и обычными файлами файловой системы, которые на базовом уровне имеют блочную структуру. В пп. 2.4.5 и 3.1.2 указывалось, что на пользовательском уровне теперь возможно работать с файлами, прямо отображая их в сегменты виртуальной памяти. Эта возможность рассматривается как верхний уровень блочного ввода/вывода. На нижнем уровне блочный ввод/вывод поддерживается блочными драйверами. Блочный ввод/вывод, кроме того, поддерживается системной буферизацией (см. п. 3.3.1).
Символьный ввод/вывод служит для прямого (без буферизации) выполнения обменов между адресным пространством пользователя и соответствующим устройством. Общей для всех символьных драйверов поддержкой ядра является обеспечение функций пересылки данных между пользовательскими и ядерным адресными пространствами.
Наконец, потоковый ввод/вывод (который мы не будем рассматривать в этом курсе слишком подробно по причине обилия технических деталей) похож на символьный ввод/вывод, но по причине наличия возможности включения в поток промежуточных обрабатывающих модулей обладает существенно большей гибкостью.
Традиционным способом снижения накладных расходов при выполнении обменов с устройствами внешней памяти, имеющими блочную структуру, является буферизация блочного ввода/вывода. Это означает, что любой блок устройства внешней памяти считывается прежде всего в некоторый буфер области основной памяти, называемой в ОС UNIX системным кэшем, и уже оттуда полностью или частично (в зависимости от вида обмена) копируется в соответствующее пользовательское пространство.
Принципами организации традиционного механизма буферизации является, во-первых, то, что копия содержимого блока удерживается в системном буфере до тех пор, пока не возникнет необходимость ее замещения по причине нехватки буферов (для организации политики замещения используется разновидность алгоритма LRU, см. п. 3.1.1). Во-вторых, при выполнении записи любого блока устройства внешней памяти реально выполняется лишь обновление (или образование и наполнение) буфера кэша. Действительный обмен с устройством выполняется либо при выталкивании буфера вследствие замещения его содержимого, либо при выполнении специального системного вызова sync (или fsync), поддерживаемого специально для насильственного выталкивания во внешнюю память обновленных буферов кэша.
Эта традиционная схема буферизации вошла в противоречие с развитыми в современных вариантах ОС UNIX средствами управления виртуальной памятью и в особенности с механизмом отображения файлов в сегменты виртуальной памяти (см. пп. 2.4.5 и 3.1.2). (Мы не будем подробно объяснять здесь суть этих противоречий и предложим читателям поразмышлять над этим.) Поэтому в System V Release 4 появилась новая схема буферизации, пока используемая параллельно со старой схемой.
Суть новой схемы состоит в том, что на уровне ядра фактически воспроизводится механизм отображения файлов в сегменты виртуальной памяти. Во-первых, напомним о том, что ядро ОС UNIX действительно работает в собственной виртуальной памяти. Эта память имеет более сложную, но принципиально такую же структуру, что и пользовательская виртуальная память. Другими словами, виртуальная память ядра является сегментно-страничной, и наравне с виртуальной памятью пользовательских процессов поддерживается общей подсистемой управления виртуальной памятью. Из этого следует, во-вторых, что практически любая функция, обеспечиваемая ядром для пользователей, может быть обеспечена одними компонентами ядра для других его компонентов. В частности, это относится и к возможностям отображения файлов в сегменты виртуальной памяти.
Новая схема буферизации в ядре ОС UNIX главным образом основывается на том, что для организации буферизации можно не делать почти ничего специального. Когда один из пользовательских процессов открывает не открытый до этого времени файл, ядро образует новый сегмент и подключает к этому сегменту открываемый файл. После этого (независимо от того, будет ли пользовательский процесс работать с файлом в традиционном режиме с использованием системных вызовов read и write или подключит файл к сегменту своей виртуальной памяти) на уровне ядра работа будет производиться с тем ядерным сегментом, к которому подключен файл на уровне ядра. Основная идея нового подхода состоит в том, что устраняется разрыв между управлением виртуальной памятью и общесистемной буферизацией (это нужно было бы сделать давно, поскольку очевидно, что основную буферизацию в операционной системе должен производить компонент управления виртуальной памятью).
Почему же нельзя отказаться от старого механизма буферизации? Все дело в том, что новая схема предполагает наличие некоторой непрерывной адресации внутри объекта внешней памяти (должен существовать изоморфизм между отображаемым и отображенным объектами). Однако, при организации файловых систем ОС UNIX достаточно сложно распределяет внешнюю память, что в особенности относится к i-узлам. Поэтому некоторые блоки внешней памяти приходится считать изолированными, и для них оказывается выгоднее использовать старую схему буферизации (хотя, возможно, в завтрашних вариантах UNIX и удастся полностью перейти к унифицированной новой схеме).
Для доступа (т.е. для получения возможности последующего выполнения операций ввода/вывода) к файлу любого вида (включая специальные файлы) пользовательский процесс должен выполнить предварительное подключение к файлу с помощью одного из системных вызовов open, creat, dup или pipe. Программные каналы и соответствующие системные вызовы мы рассмотрим в п. 3.4.3, а пока несколько более подробно, чем в п. 2.3.3, рассмотрим другие "инициализирующие" системные вызовы.
Последовательность действий системного вызова open (pathname, mode) следующая:
Системные вызовы open и creat (почти) функционально эквивалентны. Любой существующий файл можно открыть с помощью системного вызова creat, и любой новый файл можно создать с помощью системного вызова open. Однако, применительно к системному вызову creat мы должны подчеркнуть, что в случае своего естественного применения (для создания файла) этот системный вызов создает новый элемент соответствующего каталога (в соответствии с заданным значением pathname), а также создает и соответствующим образом инициализирует новый i-узел.
Наконец, системный вызов dup (duplicate - скопировать) приводит к образованию нового дескриптора уже открытого файла. Этот специфический для ОС UNIX системный вызов служит исключительно для целей перенаправления ввода/вывода (см. п. 2.1.8). Его выполнение состоит в том, что в u-области системного пространства пользовательского процесса образуется новый описатель открытого файла, содержащий вновь образованный дескриптор файла (целое число), но ссылающийся на уже существующую общесистемную структуру file и содержащий те же самые признаки и флаги, которые соответствуют открытому файлу-образцу.
Другими важными системными вызовами являются системные вызовы read и write. Системный вызов read выполняется следующим образом:
Операция записи выполняется аналогичным образом, но меняет содержимое буфера буферного пула.
Системный вызов close приводит к тому, что драйвер обрывает связь с соответствующим пользовательским процессом и (в случае последнего по времени закрытия устройства) устанавливает общесистемный флаг "драйвер свободен".
Наконец, для специальных файлов поддерживается еще один "специальный" системный вызов ioctl. Это единственный системный вызов, который обеспечивается для специальных файлов и не обеспечивается для остальных разновидностей файлов. Фактически, системный вызов ioctl позволяет произвольным образом расширить интерфейс любого драйвера. Параметры ioctl включают код операции и указатель на некоторую область памяти пользовательского процесса. Всю интерпретацию кода операции и соответствующих специфических параметров проводит драйвер.
Естественно, что поскольку драйверы главным образом предназначены для управления внешними устройствами, программный код драйвера должен содержать соответствующие средства для обработки прерываний от устройства. Вызов индивидуальной программы обработки прерываний в драйвере происходит из ядра операционной системы. Подобным же образом в драйвере может быть объявлен вход "timeout", к которому обращается ядро при истечении ранее заказанного драйвером времени (такой временной контроль является необходимым при управлении не слишком интеллектуальными устройствами).
Общая схема интерфейсной организации драйверов показана на рисунке 3.5. Как показывает этот рисунок, с точки зрения интерфейсов и общесистемного управления различаются два вида драйверов - символьные и блочные. С точки зрения внутренней организации выделяется еще один вид драйверов - потоковые (stream) драйверы (мы уже упоминали о потоках в п. 2.7.1). Однако по своему внешнему интерфейсу потоковые драйверы не отличаются от символьных.

Рис. 3.5. Интерфейсы и входные точки драйверов
Блочные драйверы предназначаются для обслуживания внешних устройств с блочной структурой (магнитных дисков, лент и т.д.) и отличаются от прочих тем, что они разрабатываются и выполняются с использованием системной буферизации. Другими словами, такие драйверы всегда работают через системный буферный пул. Как видно на рисунке 3.5, любое обращение к блочному драйверу для чтения или записи всегда проходит через предварительную обработку, которая заключается в попытке найти копию нужного блока в буферном пуле.
В случае, если копия требуемого блока не находится в буферном пуле или если по какой-либо причине требуется заменить содержимое некоторого обновленного буфера, ядро ОС UNIX обращается к процедуре strategy соответствующего блочного драйвера. Strategy обеспечивает стандартный интерфейс между ядром и драйвером. С использованием библиотечных подпрограмм, предназначенных для написания драйверов, процедура strategy может организовывать очереди обменов с устройством, например, с целью оптимизации движения магнитных головок на диске. Все обмены, выполняемые блочным драйвером, выполняются с буферной памятью. Перепись нужной информации в память соответствующего пользовательского процесса производится программами ядра, заведующими управлением буферами.
Символьные драйверы главным образом предназначены для обслуживания устройств, обмены с которыми выполняются посимвольно, либо строками символов переменного размера. Типичным примером символьного устройства является простой принтер, принимающий один символ за один обмен.
Символьные драйверы не используют системную буферизацию. Они напрямую копируют данные из памяти пользовательского процесса при выполнении операций записи или в память пользовательского процесса при выполнении операций чтения, используя собственные буфера.
Следует отметить, что имеется возможность обеспечить символьный интерфейс для блочного устройства. В этом случае блочный драйвер использует дополнительные возможности процедуры strategy, позволяющие выполнять обмен без применения системной буферизации. Для драйвера, обладающего одновременно блочным и символьным интерфейсами, в файловой системе заводится два специальных файла, блочный и символьный. При каждом обращении драйвер получает информацию о том, в каком режиме он используется.
Как отмечалось в п. 2.7.1, основным назначением механизма потоков (streams) является повышение уровня модульности и гибкости драйверов со сложной внутренней логикой (более всего это относится к драйверам, реализующим развитые сетевые протоколы). Спецификой таких драйверов является то, что большая часть программного кода не зависит от особенностей аппаратного устройства. Более того, часто оказывается выгодно по-разному комбинировать части программного кода.
Все это привело к появлению потоковой архитектуры драйверов, которые представляют собой двунаправленный конвейер обрабатывающих модулей. В начале конвейера (ближе всего к пользовательскому процессу) находится заголовок потока, к которому прежде всего поступают обращения по инициативе пользователя. В конце конвейера (ближе всего к устройству) находится обычный драйвер устройства. В промежутке может располагаться произвольное число обрабатывающих модулей, каждый из которых оформляется в соответствии с обязательным потоковым интерфейсом.
Каждый процесс в ОС UNIX выполняется в собственной виртуальной памяти, т.е. если не предпринимать дополнительных усилий, то даже процессы-близнецы, образованные в результате выполнения системного вызова fork(), на самом деле полностью изолированы один от другого (если не считать того, что процесс-потомок наследует от процесса-предка все открытые файлы). Тем самым, в ранних вариантах ОС UNIX поддерживались весьма слабые возможности взаимодействия процессов, даже входящих в общую иерархию порождения (т.е. имеющих общего предка).
Очень слабые средства поддерживались и для взаимной синхронизации процессов. Практически, все ограничивалось возможностью реакции на сигналы, и наиболее распространенным видом синхронизации являлась реакция процесса-предка на сигнал о завершении процесса-потомка.
По-видимому, применение такого подхода являлось реакцией на чрезмерно сложные механизмы взаимодействия и синхронизации параллельных процессов, существовавшие в исторически предшествующей UNIX ОС Multics. Напомним (см. раздел 1.1), что в ОС Multics поддерживалась сегментно-страничная организация виртуальной памяти, и в общей виртуальной памяти могло выполняться несколько параллельных процессов, которые, естественно, могли взаимодействовать через общую память. За счет возможности включения одного и того же сегмента в разную виртуальную память аналогичная возможность взаимодействий существовала и для процессов, выполняемых не в общей виртуальной памяти.
Для синхронизации таких взаимодействий процессов поддерживался общий механизм семафоров, позволяющий, в частности, организовывать взаимное исключение процессов в критических участках их выполнения (например, при взаимно-исключающем доступе к разделяемой памяти). Этот стиль параллельного программирования в принципе обеспечивает большую гибкость и эффективность, но является очень трудным для использования. Часто в программах появляются трудно обнаруживаемые и редко воспроизводимые синхронизационные ошибки; использование явной синхронизации, не связанной неразрывно с теми объектами, доступ к которым синхронизуется, делает логику программ трудно постижимой, а текст программ - трудно читаемым.
Понятно, что стиль ранних вариантов ОС UNIX стимулировал существенно более простое программирование. В наиболее простых случаях процесс-потомок образовывался только для того, чтобы асинхронно с основным процессом выполнить какое-либо простое действие (например, запись в файл). В более сложных случаях процессы, связанные иерархией родства, создавали обрабатывающие "конвейеры" с использованием техники программных каналов (pipes). Эта техника особенно часто применяется при программировании на командных языках (см. раздел 5.2).
Долгое время отцы-основатели ОС UNIX считали, что в той области, для которой предназначался UNIX (разработка программного обеспечения, подготовка и сопровождение технической документации и т.д.) этих возможностей вполне достаточно. Однако постепенное распространение системы в других областях и сравнительная простота наращивания ее возможностей привели к тому, что со временем в разных вариантах ОС UNIX в совокупности появился явно избыточный набор системных средств, предназначенных для обеспечения возможности взаимодействия и синхронизации процессов, которые не обязательно связаны отношением родства (в мире ОС UNIX эти средства обычно называют IPC от Inter-Process Communication Facilities). С появлением UNIX System V Release 4.0 (и более старшей версии 4.2) все эти средства были узаконены и вошли в фактический стандарт ОС UNIX современного образца.
Нельзя сказать, что средства IPC ОС UNIX идеальны хотя бы в каком-нибудь отношении. При разработке сложных асинхронных программных комплексов (например, систем реального времени) больше всего неудобств причиняет избыточность средств IPC. Всегда возможны несколько вариантов реализации, и очень часто невозможно найти критерии выбора. Дополнительную проблему создает тот факт, что в разных вариантах системы средства IPC реализуются по-разному, зачастую одни средства реализованы на основе использования других средств. Поэтому эффективность реализации различается, из-за чего усложняется разработка мобильных асинхронных программных комплексов.
Тем не менее, знать возможности IPC, безусловно, нужно, если относиться к ОС UNIX как к серьезной производственной операционной системе. В этом разделе мы рассмотрим основные стандартизованные возможности в основном на идейном уровне, не вдаваясь в технические детали.
Порядок рассмотрения не отражает какую-либо особую степень важности или предпочтительности конкретного средства. Мы начинаем с пакета средств IPC, которые появились в UNIX System V Release 3.0. Этот пакет включает:
Эти механизмы объединяются в единый пакет, потому что соответствующие системные вызовы обладают близкими интерфейсами, а в их реализации используются многие общие подпрограммы. Вот основные общие свойства всех трех механизмов:
Перейдем к более детальному изучению конкретных механизмов этого семейства.
Для работы с разделяемой памятью используются четыре системных вызова:
После того, как сегмент разделяемой памяти подключен к виртуальной памяти процесса, этот процесс может обращаться к соответствующим элементам памяти с использованием обычных машинных команд чтения и записи, не прибегая к использованию дополнительных системных вызовов.
Синтаксис системного вызова shmget выглядит следующим образом:
shmid = shmget(key, size, flag);
Параметр size определяет желаемый размер сегмента в байтах. Далее работа происходит по общим правилам. Если в таблице разделяемой памяти находится элемент, содержащий заданный ключ, и права доступа не противоречат текущим характеристикам обращающегося процесса, то значением системного вызова является дескриптор существующего сегмента (и обратившийся процесс так и не узнает реального размера сегмента, хотя впоследствии его все-таки можно узнать с помощью системного вызова shmctl). В противном случае создается новый сегмент с размером не меньше установленного в системе минимального размера сегмента разделяемой памяти и не больше установленного максимального размера. Создание сегмента не означает немедленного выделения под него основной памяти. Это действие откладывается до выполнения первого системного вызова подключения сегмента к виртуальной памяти некоторого процесса. Аналогично, при выполнении последнего системного вызова отключения сегмента от виртуальной памяти соответствующая основная память освобождается.
Подключение сегмента к виртуальной памяти выполняется путем обращения к системному вызову shmat:
virtaddr = shmat(id, addr, flags);
Здесь id - это ранее полученный дескриптор сегмента, а addr - желаемый процессом виртуальный адрес, который должен соответствовать началу сегмента в виртуальной памяти. Значением системного вызова является реальный виртуальный адрес начала сегмента (его значение не обязательно совпадает со значением прямого параметра addr). Если значением addr является нуль, ядро выбирает наиболее удобный виртуальный адрес начала сегмента. Кроме того, ядро старается обеспечить (но не гарантирует) выбор такого стартового виртуального адреса сегмента, который обеспечивал бы отсутствие перекрывающихся виртуальных адресов данного разделяемого сегмента, сегмента данных и сегмента стека процесса (два последних сегмента могут расширяться).
Для отключения сегмента от виртуальной памяти используется системный вызов shmdt:
shmdt(addr);
где addr - это виртуальный адрес начала сегмента в виртуальной памяти, ранее полученный от системного вызова shmat. Естественно, система гарантирует (на основе использования таблицы сегментов процесса), что указанный виртуальный адрес действительно является адресом начала (разделяемого) сегмента в виртуальной памяти данного процесса.
Системный вызов shmctl:
shmctl(id, cmd, shsstatbuf);
содержит прямой параметр cmd, идентифицирующий требуемое конкретное действие, и предназначен для выполнения различных функций. Видимо, наиболее важной является функция уничтожения сегмента разделяемой памяти. Уничтожение сегмента производится следующим образом. Если к моменту выполнения системного вызова ни один процесс не подключил сегмент к своей виртуальной памяти, то основная память, занимаемая сегментом, освобождается, а соответствующий элемент таблицы разделяемых сегментов объявляется свободным. В противном случае в элементе таблицы сегментов выставляется флаг, запрещающий выполнение системного вызова shmget по отношению к этому сегменту, но процессам, успевшим получить дескриптор сегмента, по-прежнему разрешается подключать сегмент к своей виртуальной памяти. При выполнении последнего системного вызова отключения сегмента от виртуальной памяти операция уничтожения сегмента завершается.
Механизм семафоров, реализованный в ОС UNIX, является обобщением классического механизма семафоров общего вида, предложенного более 25 лет тому назад известным голландским специалистом профессором Дейкстрой. Заметим, что целесообразность введения такого обобщения достаточно сомнительна. Обычно наоборот использовался облегченный вариант семафоров Дейкстры - так называемые двоичные семафоры. Мы не будем здесь углубляться в общую теорию синхронизации на основе семафоров, но заметим, что достаточность в общем случае двоичных семафоров доказана (известен алгоритм реализации семафоров общего вида на основе двоичных). Конечно, аналогичные рассуждения можно было бы применить и к варианту семафоров, примененному в ОС UNIX.
Семафор в ОС UNIX состоит из следующих элементов:
Для работы с семафорами поддерживаются три системных вызова:
Системный вызов semget имеет следующий синтаксис:
id = semget(key, count, flag);
где прямые параметры key и flag и возвращаемое значение системного вызова имеют тот же смысл, что для других системных вызовов семейства "get", а параметр count задает число семафоров в наборе семафоров, обладающих одним и тем же ключом. После этого индивидуальный семафор идентифицируется дескриптором набора семафоров и номером семафора в этом наборе. Если к моменту выполнения системного вызова semget набор семафоров с указанным ключом уже существует, то обращающийся процесс получит соответствующий дескриптор, но так и не узнает о реальном числе семафоров в группе (хотя позже это все-таки можно узнать с помощью системного вызова semctl).
Основным системным вызовом для манипулирования семафором является semop:
oldval = semop(id, oplist, count);
где id - это ранее полученный дескриптор группы семафоров, oplist - массив описателей операций над семафорами группы, а count - размер этого массива. Значение, возвращаемое системным вызовом, является значением последнего обработанного семафора. Каждый элемент массива oplist имеет следующую структуру:
Если проверка прав доступа проходит нормально, и указанные в массиве oplist номера семафоров не выходят за пределы общего размера набора семафоров, то системный вызов выполняется следующим образом. Для каждого элемента массива oplist значение соответствующего семафора изменяется в соответствии со значением поля "операция".
Основным поводом для введения массовых операций над семафорами было стремление дать программистам возможность избегать тупиковых ситуаций в связи с семафорной синхронизацией. Это обеспечивается тем, что системный вызов semop, каким бы длинным он не был (по причине потенциально неограниченной длины массива oplist) выполняется как атомарная операция, т.е. во время выполнения semop ни один другой процесс не может изменить значение какого-либо семафора.
Наконец, среди флагов-параметров системного вызова semop может содержаться флаг с символическим именем IPC_NOWAIT, наличие которого заставляет ядро ОС UNIX не блокировать текущий процесс, а лишь сообщать в ответных параметрах о возникновении ситуации, приведшей бы к блокированию процесса при отсутствии флага IPC_NOWAIT. Мы не будем обсуждать здесь возможности корректного завершения работы с семафорами при незапланированном завершении процесса; заметим только, что такие возможности обеспечиваются.
Системный вызов semctl имеет формат
semctl(id, number, cmd, arg);
где id - это дескриптор группы семафоров, number - номер семафора в группе, cmd - код операции, а arg - указатель на структуру, содержимое которой интерпретируется по-разному, в зависимости от операции. В частности, с помощью semctl можно уничтожить индивидуальный семафор в указанной группе. Однако детали этого системного вызова настолько громоздки, что мы рекомендуем в случае необходимости обращаться к технической документации используемого варианта операционной системы.
Для обеспечения возможности обмена сообщениями между процессами этот механизм поддерживается следующими системными вызовами:
Системный вызов msgget обладает стандартным для семейства "get" системных вызовов синтаксисом:
msgqid = msgget(key, flag);
Ядро хранит сообщения в виде связного списка (очереди), а дескриптор очереди сообщений является индексом в массиве заголовков очередей сообщений. В дополнение к информации, общей для всех механизмов IPC в UNIX System V, в заголовке очереди хранятся также:
Как обычно, при выполнении системного вызова msgget ядро ОС UNIX либо создает новую очередь сообщений, помещая ее заголовок в таблицу очередей сообщений и возвращая пользователю дескриптор вновь созданной очереди, либо находит элемент таблицы очередей сообщений, содержащий указанный ключ, и возвращает соответствующий дескриптор очереди. На рисунке 3.6 показаны структуры данных, используемые для организации очередей сообщений.
Рис. 3.6. Структуры данных, используемые для организации очередей сообщений
Для посылки сообщения используется системный вызов msgsnd:
msgsnd(msgqid, msg, count, flag);
где msg - это указатель на структуру, содержащую определяемый пользователем целочисленный тип сообщения и символьный массив - собственно сообщение; count задает размер сообщения в байтах, а flag определяет действия ядра при выходе за пределы допустимых размеров внутренней буферной памяти.
Для того, чтобы ядро успешно поставило указанное сообщение в указанную очередь сообщений, должны быть выполнены следующие условия: обращающийся процесс должен иметь соответствующие права по записи в данную очередь сообщений; длина сообщения не должна превосходить установленный в системе верхний предел; общая длина сообщений (включая вновь посылаемое) не должна превосходить установленный предел; указанный в сообщении тип сообщения должен быть положительным целым числом. В этом случае обратившийся процесс успешно продолжает свое выполнение, оставив отправленное сообщение в буфере очереди сообщений. Тогда ядро активизирует (пробуждает) все процессы, ожидающие поступления сообщений из данной очереди.
Если же оказывается, что новое сообщение невозможно буферизовать в ядре по причине превышения верхнего предела суммарной длины сообщений, находящихся в одной очереди сообщений, то обратившийся процесс откладывается (усыпляется) до тех пор, пока очередь сообщений не разгрузится процессами, ожидающими получения сообщений. Чтобы избежать такого откладывания, обращающийся процесс должен указать в числе параметров системного вызова msgsnd значение флага с символическим именем IPC_NOWAIT (как в случае использования семафоров), чтобы ядро выдало свидетельствующий об ошибке код возврата системного вызова mgdsng в случае невозможности включить сообщение в указанную очередь.
Для приема сообщения используется системный вызов msgrcv:
count = msgrcv(id, msg, maxcount, type, flag);
Здесь msg - это указатель на структуру данных в адресном пространстве пользователя, предназначенную для размещения принятого сообщения; maxcount задает размер области данных (массива байтов) в структуре msg; значение type специфицирует тип сообщения, которое желательно принять; значение параметра flag указывает ядру, что следует предпринять, если в указанной очереди сообщений отсутствует сообщение с указанным типом. Возвращаемое значение системного вызова задает реальное число байтов, переданных пользователю.
Выполнение системного вызова, как обычно, начинается с проверки правомочности доступа обращающегося процесса к указанной очереди. Далее, если значением параметра type является нуль, ядро выбирает первое сообщение из указанной очереди сообщений и копирует его в заданную пользовательскую структуру данных. После этого корректируется информация, содержащаяся в заголовке очереди (число сообщений, суммарный размер и т.д.). Если какие-либо процессы были отложены по причине переполнения очереди сообщений, то все они активизируются. В случае, если значение параметра maxcount оказывается меньше реального размера сообщения, ядро не удаляет сообщение из очереди и возвращает код ошибки. Однако, если задан флаг MSG_NOERROR, то выборка сообщения производится, и в буфер пользователя переписываются первые maxcount байтов сообщения.
Путем задания соответствующего значения параметра type пользовательский процесс может потребовать выборки сообщения некоторого конкретного типа. Если это значение является положительным целым числом, ядро выбирает из очереди сообщений первое сообщение с таким же типом. Если же значение параметра type есть отрицательное целое число, то ядро выбирает из очереди первое сообщение, значение типа которого меньше или равно абсолютному значению параметра type.
Во всех случаях, если в указанной очереди отсутствуют сообщения, соответствующие спецификации параметра type, ядро откладывает (усыпляет) обратившийся процесс до появления в очереди требуемого сообщения. Однако, если в параметре flag задано значение флага IPC_NOWAIT, то процесс немедленно оповещается об отсутствии сообщения в очереди путем возврата кода ошибки.
Системный вызов
msgctl(id, cmd, mstatbuf);
служит для опроса состояния описателя очереди сообщений, изменения его состояния (например, изменения прав доступа к очереди) и для уничтожения указанной очереди сообщений (детали мы опускаем).
Как мы уже неоднократно отмечали, традиционным средством взаимодействия и синхронизации процессов в ОС UNIX являются программные каналы (pipes). Теоретически программный канал позволяет взаимодействовать любому числу процессов, обеспечивая дисциплину FIFO (first-in-first-out). Другими словами, процесс, читающий из программного канала, прочитает те данные, которые были записаны в программный канал наиболее давно. В традиционной реализации программных каналов для хранения данных использовались файлы. В современных версиях ОС UNIX для реализации программных каналов применяются другие средства IPC (в частности, очереди сообщений).
Различаются два вида программных каналов - именованные и неименованные. Именованный программный канал может служить для общения и синхронизации произвольных процессов, знающих имя данного программного канала и имеющих соответствующие права доступа. Неименованным программным каналом могут пользоваться только создавший его процесс и его потомки (необязательно прямые).
Для создания именованного программного канала (или получения к нему доступа) используется обычный файловый системный вызов open. Для создания же неименованного программного канала существует специальный системный вызов pipe (исторически более ранний). Однако после получения соответствующих дескрипторов оба вида программных каналов используются единообразно с помощью стандартных файловых системных вызовов read, write и close.
Системный вызов pipe имеет следующий синтаксис:
pipe(fdptr);
где fdptr - это указатель на массив из двух целых чисел, в который после создания неименованного программного канала будут помещены дескрипторы, предназначенные для чтения из программного канала (с помощью системного вызова read) и записи в программный канал (с помощью системного вызова write). Дескрипторы неименованного программного канала - это обычные дескрипторы файлов, т.е. такому программному каналу соответствуют два элемента таблицы открытых файлов процесса. Поэтому при последующем использовании системных вызовов read и write процесс совершенно не обязан отличать случай использования программных каналов от случая использования обычных файлов (собственно, на этом и основана идея перенаправления ввода/вывода и организации конвейеров).
Для создания именованных программных каналов (или получения доступа к уже существующим каналам) используется обычный системный вызов open. Основным отличием от случая открытия обычного файла является то, что если именованный программный канал открывается на запись, и ни один процесс не открыл тот же программный канал для чтения, то обращающийся процесс блокируется (усыпляется) до тех пор, пока некоторый процесс не откроет данный программный канал для чтения (аналогично обрабатывается открытие для чтения). Повод для использования такого режима работы состоит в том, что, вообще говоря, бессмысленно давать доступ к программному каналу на чтение (запись) до тех пор, пока некоторый другой процесс не обнаружит готовности писать в данный программный канал (соответственно читать из него). Понятно, что если бы эта схема была абсолютной, то ни один процесс не смог бы начать работать с заданным именованным программным каналом (кто-то должен быть первым). Поэтому в числе флагов системного вызова open имеется флаг NO_DELAY, задание которого приводит к тому, что именованный программный канал открывается независимо от наличия соответствующего партнера.
Запись данных в программный канал и чтение данных из программного канала (независимо от того, именованный он или неименованный) выполняются с помощью системных вызовов read и write. Отличие от случая использования обычных файлов состоит лишь в том, что при записи данные помещаются в начало канала, а при чтении выбираются (освобождая соответствующую область памяти) из конца канала. Как всегда, возможны ситуации, когда при попытке записи в программный канал оказывается, что канал переполнен, и тогда обращающийся процесс блокируется, пока канал не разгрузится (если только не указан флаг нежелательности блокировки в числе параметров системного вызова write), или когда при попытке чтения из программного канала оказывается, что канал пуст (или в нем отсутствует требуемое количество байтов информации), и тогда обращающийся процесс блокируется, пока канал не загрузится соответствующим образом (если только не указан флаг нежелательности блокировки в числе параметров системного вызова read).
Окончание работы процесса с программным каналом (независимо от того, именованный он или неименованный) производится с помощью системного вызова close. В основном, действия ядра при закрытии программного канала аналогичны действиям при закрытии обычного файла. Однако имеется отличие в том, что при выполнении последнего закрытия канала по записи все процессы, ожидающие чтения из программного канала (т.е. процессы, обратившиеся к ядру с системным вызовом read и отложенные по причине недостатка данных в канале), активизируются с возвратом кода ошибки из системного вызова. (Это совершенно оправданно в случае неименованных программных каналов: если достоверно известно, что больше нечего читать, то зачем заставлять далее ждать чтения. Для именованных программных каналов это решение не является очевидным, но соответствует общей политике ОС UNIX о раннем предупреждении процессов.)
Операционная система UNIX с самого начала проектировалась как сетевая ОС в том смысле, что должна была обеспечивать явную возможность взаимодействия процессов, выполняющихся на разных компьютерах, соединенных сетью передачи данных. Главным образом, эта возможность базировалась на обеспечении файлового интерфейса для устройств (включая сетевые адаптеры) на основе понятия специального файла. Другими словами, два или более процессов, располагающихся на разных компьютерах, могли договориться о способе взаимодействия на основе использования возможностей соответствующих сетевых драйверов.
Эти базовые возможности были в принципе достаточными для создания сетевых утилит; в частности, на их основе был создан исходный в ОС UNIX механизм сетевых взаимодействий uucp. Однако организация сетевых взаимодействий пользовательских процессов была затруднительна главным образом потому, что при использовании конкретной сетевой аппаратуры и конкретного сетевого протокола требовалось выполнять множество системных вызовов ioctl, что делало программы зависимыми от специфической сетевой среды. Требовался поддерживаемый ядром механизм, позволяющий скрыть особенности этой среды и позволить единообразно взаимодействовать процессам, выполняющимся на одном компьютере, в пределах одной локальной сети или разнесенным на разные компьютеры территориально распределенной сети. Первое решение этой проблемы было предложено и реализовано в UNIX BSD 4.1 в 1982 г. (вводную информацию см. в п. 2.7.3).
На уровне ядра механизм программных гнезд поддерживается тремя составляющими: компонентом уровня программных гнезд (независящим от сетевого протокола и среды передачи данных), компонентом протокольного уровня (независящим от среды передачи данных) и компонентом уровня управления сетевым устройством (см. рисунок 3.7).
Рис. 3.7. Одна из возможных конфигураций программных гнезд
Допустимые комбинации протоколов и драйверов задаются при конфигурации системы, и во время работы системы их менять нельзя. Легко видеть, что по своему духу организация программных гнезд близка к идее потоков (см. пп. 2.7.1 и 3.4.6), поскольку основана на разделении функций физического управления устройством, протокольных функций и функций интерфейса с пользователями. Однако это менее гибкая схема, поскольку не допускает изменения конфигурации "на ходу".
Взаимодействие процессов на основе программных гнезд основано на модели "клиент-сервер". Процесс-сервер "слушает (listens)" свое программное гнездо, одну из конечных точек двунаправленного пути коммуникаций, а процесс-клиент пытается общаться с процессом-сервером через другое программное гнездо, являющееся второй конечной точкой коммуникационного пути и, возможно, располагающееся на другом компьютере. Ядро поддерживает внутренние соединения и маршрутизацию данных от клиента к серверу.
Программные гнезда с общими коммуникационными свойствами, такими как способ именования и протокольный формат адреса, группируются в домены. Наиболее часто используемыми являются "домен системы UNIX" для процессов, которые взаимодействуют через программные гнезда в пределах одного компьютера, и "домен Internet" для процессов, которые взаимодействуют в сети в соответствии с семейством протоколов TCP/IP (см. п. 2.7.2).
Выделяются два типа программных гнезд - гнезда с виртуальным соединением (в начальной терминологии stream sockets) и датаграммные гнезда (datagram sockets). При использовании программных гнезд с виртуальным соединением обеспечивается передача данных от клиента к серверу в виде непрерывного потока байтов с гарантией доставки. При этом до начала передачи данных должно быть установлено соединение, которое поддерживается до конца коммуникационной сессии. Датаграммные программные гнезда не гарантируют абсолютной надежной, последовательной доставки сообщений и отсутствия дубликатов пакетов данных - датаграмм. Но для использования датаграммного режима не требуется предварительное дорогостоящее установление соединений, и поэтому этот режим во многих случаях является предпочтительным. Система по умолчанию сама обеспечивает подходящий протокол для каждой допустимой комбинации "домен-гнездо". Например, протокол TCP используется по умолчанию для виртуальных соединений, а протокол UDP - для датаграммного способа коммуникаций (информация об этих протоколах представлена в п. 2.7.2).
Для работы с программными гнездами поддерживается набор специальных библиотечных функций (в UNIX BSD это системные вызовы, однако, как мы отмечали в п. 2.7.3, в UNIX System V они реализованы на основе потокового интерфейса TLI). Рассмотрим кратко интерфейсы и семантику этих функций.
Для создания нового программного гнезда используется функция socket:
sd = socket(domain, type, protocol);
где значение параметра domain определяет домен данного гнезда, параметр type указывает тип создаваемого программного гнезда (с виртуальным соединением или датаграммное), а значение параметра protocol определяет желаемый сетевой протокол. Заметим, что если значением параметра protocol является нуль, то система сама выбирает подходящий протокол для комбинации значений параметров domain и type, это наиболее распространенный способ использования функции socket. Возвращаемое функцией значение является дескриптором программного гнезда и используется во всех последующих функциях. Вызов функции close(sd) приводит к закрытию (уничтожению) указанного программного гнезда.
Для связывания ранее созданного программного гнезда с именем используется функция bind:
bind(sd, socknm, socknlen);
Здесь sd - дескриптор ранее созданного программного гнезда, socknm - адрес структуры, которая содержит имя (идентификатор) гнезда, соответствующее требованиям домена данного гнезда и используемого протокола (в частности, для домена системы UNIX имя является именем объекта в файловой системе, и при создании программного гнезда действительно создается файл), параметр socknlen содержит длину в байтах структуры socknm (этот параметр необходим, поскольку длина имени может весьма различаться для разных комбинаций "домен-протокол").
С помощью функции connect процесс-клиент запрашивает систему связаться с существующим программным гнездом (у процесса-сервера):
connect(sd, socknm, socknlen);
Смысл параметров такой же, как у функции bind, однако в качестве имени указывается имя программного гнезда, которое должно находиться на другой стороне коммуникационного канала. Для нормального выполнения функции необходимо, чтобы у гнезда с дескриптором sd и у гнезда с именем socknm были одинаковые домен и протокол. Если тип гнезда с дескриптором sd является датаграммным, то функция connect служит только для информирования системы об адресе назначения пакетов, которые в дальнейшем будут посылаться с помощью функции send; никакие действия по установлению соединения в этом случае не производятся.
Функция listen предназначена для информирования системы о том, что процесс-сервер планирует установление виртуальных соединений через указанное гнездо:
listen(sd, qlength);
Здесь sd - это дескриптор существующего программного гнезда, а значением параметра qlength является максимальная длина очереди запросов на установление соединения, которые должны буферизоваться системой, пока их не выберет процесс-сервер.
Для выборки процессом-сервером очередного запроса на установление соединения с указанным программным гнездом служит функция accept:
nsd = accept(sd, address, addrlen);
Параметр sd задает дескриптор существующего программного гнезда, для которого ранее была выполнена функция listen; address указывает на массив данных, в который должна быть помещена информация, характеризующая имя программного гнезда клиента, со стороны которого поступает запрос на установление соединения; addrlen - адрес, по которому находится длина массива address. Если к моменту выполнения функции accept очередь запросов на установление соединений пуста, то процесс-сервер откладывается до поступления запроса. Выполнение функции приводит к установлению виртуального соединения, а ее значением является новый дескриптор программного гнезда, который должен использоваться при работе через данное соединение. По адресу addrlen помещается реальный размер массива данных, которые записаны по адресу address. Процесс-сервер может продолжать "слушать" следующие запросы на установление соединения, пользуясь установленным соединением.
Для передачи и приема данных через программные гнезда с установленным виртуальным соединением используются функции send и recv:
count = send(sd, msg, length, flags);
count = recv(sd, buf, length, flags);
В функции send параметр sd задает дескриптор существующего программного гнезда с установленным соединением; msg указывает на буфер с данными, которые требуется послать; length задает длину этого буфера. Наиболее полезным допустимым значением параметра flags является значение с символическим именем MSG_OOB, задание которого означает потребность во внеочередной посылке данных. "Внеочередные" сообщения посылаются помимо нормального для данного соединения потока данных, обгоняя все непрочитанные сообщения. Потенциальный получатель данных может получить специальный сигнал и в ходе его обработки немедленно прочитать внеочередные данные. Возвращаемое значение функции равняется числу реально посланных байтов и в нормальных ситуациях совпадает со значением параметра length.
В функции recv параметр sd задает дескриптор существующего программного гнезда с установленным соединением; buf указывает на буфер, в который следует поместить принимаемые данные; length задает максимальную длину этого буфера. Наиболее полезным допустимым значением параметра flags является значение с символическим именем MSG_PEEK, задание которого приводит к переписи сообщения в пользовательский буфер без его удаления из системных буферов. Возвращаемое значение функции является числом байтов, реально помещенных в buf.
Заметим, что в случае использования программных гнезд с виртуальным соединением вместо функций send и recv можно использовать обычные файловые системные вызовы read и write. Для программных гнезд они выполняются абсолютно аналогично функциям send и recv. Это позволяет создавать программы, не зависящие от того, работают ли они с обычными файлами, программными каналами или программными гнездами.
Для посылки и приема сообщений в датаграммном режиме используются функции sendto и recvfrom:
count = sendto(sd, msg, length, flags, socknm, socknlen);
count = recvfrom(sd, buf, length, flags, socknm, socknlen);
Смысл параметров sd, msg, buf и lenght аналогичен смыслу одноименных параметров функций send и recv. Параметры socknm и socknlen функции sendto задают имя программного гнезда, в которое посылается сообщение, и могут быть опущены, если до этого вызывалась функция connect. Параметры socknm и socknlen функции recvfrom позволяют серверу получить имя пославшего сообщение процесса-клиента.
Наконец, для немедленной ликвидации установленного соединения используется системный вызов shutdown:
shutdown(sd, mode);
Вызов этой функции означает, что нужно немедленно остановить коммуникации либо со стороны посылающего процесса, либо со стороны принимающего процесса, либо с обеих сторон (в зависимости от значения параметра mode). Действия функции shutdown отличаются от действий функции close тем, что, во-первых, выполнение последней "притормаживается" до окончания попыток системы доставить уже отправленные сообщения. Во-вторых, функция shutdown разрывает соединение, но не ликвидирует дескрипторы ранее соединенных гнезд. Для окончательной их ликвидации все равно требуется вызов функции close.
Замечание: приведенная в этом пункте информация может несколько отличаться от требований реально используемой вами системы. В основном это относится к символическим именам констант. Постоянная беда пользователей ОС UNIX состоит в том, что от версии к версии меняются символические имена и имена системных структурных типов.
Здесь нам почти нечего добавить к материалу, приведенному в п. 2.7.1. На
основе использования механизма потоковых сетевых драйверов в UNIX
System V создана библиотека TLI (Transport Layer Interface),
обеспечивающая транспортный сервис на основе стека протоколов TCP/IP.
Возможности этого пакета превышают описанные выше возможности
программных гнезд и, конечно, позволяют организовывать разнообразные
виды коммуникации процессов. Однако многообразие и сложность набора
функций библиотеки TLI не позволяют нам в подробностях описать их в
рамках этого курса. Кроме того, TLI относится, скорее, не к теме ОС
UNIX, а к теме реализаций семиуровневой модели ISO/OSI. Поэтому в случае
необходимости мы рекомендуем пользоваться технической документацией по
используемому варианту ОС UNIX или читать специальную литературу,
посвященную сетевым возможностям современных версий UNIX.