
| ИНФОРМАЦИЯ | |
© Крюков В.А.
Курс лекций
"Распределенные
ОС"
© Крюков В.А.
Курс лекций
"Распределенные
ОС"
Обычно децентрализованные алгоритмы имеют следующие свойства:
Первые три пункта все говорят о недопустимости сбора всей информации для
принятия решения в одно место. Обеспечение синхронизации без централизации
требует подходов, отличных от используемых в традиционных ОС. Последний пункт
также очень важен - в распределенных системах достигнуть согласия относительно
времени совсем непросто. Важность наличия единого времени можно оценить на
примере программы make в ОС UNIX. Главные теоретические проблемы - отсутствие
глобальных часов и невозможность зафиксировать глобальное состояние (для анализа
ситуации - обнаружения дедлоков, для организации промежуточного запоминания).
Аппаратные часы (скорее таймер - счетчик временных сигналов и регистр с начальным значением счетчика) основаны на кварцевом генераторе и могут в разных ЭВМ различаться по частоте.
В 1978 году Лэмпорт (Lamport) показал, что синхронизация времени возможна, и предложил алгоритм для такой синхронизации. При этом он указал, что абсолютной синхронизации не требуется. Если два процесса не взаимодействуют, то единого времени им не требуется. Кроме того, в большинстве случаев согласованное время может не иметь ничего общего с астрономическим временем, которое объявляется по радио. В таких случаях можно говорить о логических часах.
Для синхронизации логических часов Lamport определил отношение "произошло до". Выражение a->b читается как "a произошло до b" и означает, что все процессы согласны, что сначала произошло событие "a", а затем "b". Это отношение может в двух случаях быть очевидным:
Отношение -> является транзитивным.
Если два события x и y случились в различных процессах, которые не обмениваются сообщениями, то отношения x->y и y->x являются неверными, а эти события называют одновременными.
Введем логическое время С таким образом, что если a->b, то C(a) < C(b)
Алгоритм:
| Логическое время без коррекции. | Логическое время с коррекцией. | |
| 0 | 0 | 0 | 0 | 0 | 0 | |||||
| 6 | >- | 8 | 10 | 6 | >- | 8 | 10 | |||
| 12 | 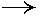 |
16 | 20 | 12 | |
16 | 20 | |||
| 18 | 24 | >- | 30 | 18 | 24 | >- | 30 | |||
| 24 | 32 | |
40 | 24 | 32 | |
40 | |||
| 30 | 40 | 50 | 30 | 40 | 50 | |||||
| 36 | 48 | -< | 60 | 36 | 48 | -< | 60 | |||
| 42 | 56 | 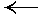 |
70 | 42 | 61 | |
70 | |||
| 48 | -< | 64 | 80 | 48 | -< | 69 | 80 | |||
| 54 | |
72 | 90 | 70 | |
77 | 90 | |||
| 60 | 80 | 100 | 76 | 85 | 100 |
Для целей упорядочения всех событий удобно потребовать, чтобы их времена никогда не совпадали. Это можно сделать, добавляя в качестве дробной части к времени уникальный номер процесса (40.1, 40.2). Однако логических часов недостаточно для многих применений (системы управления в реальном времени).
После изобретения в 17 веке механических часов время измерялось астрономически. Интервал между двумя последовательными достижениями солнцем наивысшей точки на небе называется солнечным днем. Солнечная секунда равняется 1/86400(24*3600) части солнечного дня.
В 1940-х годах было установлено, что период вращения земли не постоянен - земля замедляет вращение из-за приливов и атмосферы. Геологи считают, что 300 миллионов лет назад в году было 400 дней. Происходят и изменения длительности дня по другим причинам. Поэтому стали вычислять за длительный период среднюю солнечную секунду.
С изобретением в 1948 году атомных часов появилась возможность точно измерять время независимо от колебаний солнечного дня. В настоящее время 50 лабораторий в разных точках земли имеют часы, базирующиеся на частоте излучения Цезия-133. Среднее значение является международным атомным временем (TAI), исчисляемым с 1 июля 1958 года.
Отставание TAI от солнечного времени компенсируется становится добавлением секунды тогда, когда разница больше 800 мксек. Это скорректированное время, называеемое UTC (Universal Coordinated Time), заменило прежний стандарт (Среднее время по Гринвичу - астрономическое время). При объявлении о добавлении секунды к UTC электрические компании меняют частоту с 60 Hz на 61 Hz (c 50 на 51) на период времени в 60 (50) секунд. Для обеспечения точного времени сигналы WWV передаются коротковолновым передатчиком (Fort Collins, Colorado) в начале каждой секунды UTC. Есть и другие службы времени.
Две проблемы - часы не должны ходить назад (надо ускорять или замедлять их для проведения коррекции) и ненулевое время прохождения сообщения о времени (можно многократно замерять время прохождения и брать среднее).
Многие распределенные алгоритмы требуют, чтобы один из процессов выполнял функции координатора, инициатора или некоторую другую специальную роль. Выбор такого специального процесса будем называть выбором координатора. При этом очень часто бывает не важно, какой именно процесс будет выбран. Можно считать, что обычно выбирается процесс с самым большим уникальным номером. Могут применяться разные алгоритмы, имеющие одну цель - если процедура выборов началась, то она должна закончиться согласием всех процессов относительно нового координатора.
Алгоритм "задиры"
Если процесс обнаружит, что координатор очень
долго не отвечает, то инициирует выборы. Процесс P проводит выборы
следующим образом:
В любой момент процесс может получить сообщение "ВЫБОРЫ" от одного из коллег с меньшим номером. В этом случае он посылает ответ "OK", чтобы сообщить, что он жив и берет проведение выборов на себя, а затем начинает выборы (если к этому моменту он уже их не вел). Следовательно, все процессы прекратят выборы, кроме одного - нового координатора. Он извещает всех о своей победе и вступлении в должность сообщением "КООРДИНАТОР".
Если процесс выключился из работы, а затем захотел восстановить свое участие, то он проводит выборы (отсюда и название алгоритма).
Алгоритм основан на использовании кольца (физического или логического), но без маркера. Каждый процесс знает следующего за ним в круговом списке. Когда процесс обнаруживает отсутствие координатора, он посылает следующему за ним процессу сообщение "ВЫБОРЫ" со своим номером. Если следующий процесс не отвечает, то сообщение посылается процессу, следующему за ним, и т.д., пока не найдется работающий процесс. Каждый работающий процесс добавляет в список работающих свой номер и переправляет сообщение дальше по кругу. Когда процесс обнаружит в списке свой собственный номер (круг пройден), он меняет тип сообщения на "КООРДИНАТОР" и оно проходит по кругу, извещая всех о списке работающих и координаторе (процессе с наибольшим номером в списке). После прохождения круга сообщение удаляется.
Все процессы запрашивают у координатора разрешение на вход в критическую секцию и ждут этого разрешения. Координатор обслуживает запросы в порядке поступления. Получив разрешение процесс входит в критическую секцию. При выходе из нее он сообщает об этом координатору. Количество сообщений на одно прохождение критической секции - 3.
Недостатки алгоритма - обычные недостатки централизованного алгоритма (крах координатора или его перегрузка сообщениями).
Все процессы составляют логическое кольцо, когда каждый знает, кто следует за ним. По кольцу циркулирует маркер, дающий право на вход в критическую секцию. Получив маркер (посредством сообщения точка-точка) процесс либо входит в критическую секцию (если он ждал разрешения) либо переправляет маркер дальше. После выхода из критической секции маркер переправляется дальше, повторный вход в секцию при том же маркере не разрешается.
Проблемы:
Все процессы представлены в виде сбалансированного двоичного дерева. Каждый процесс имеет очередь запросов от себя и соседних процессов (1-го, 2-х или 3-х) и указатель в направлении владельца маркера.
Вход в критическую секцию:
Если есть маркер, то процесс выполняет
КС.
Если нет маркера, то процесс:
Поведение процесса при приеме сообщений:
Процесс, не находящийся внутри КС
должен реагировать на сообщения двух видов -"МАРКЕР" и "ЗАПРОС".
А) Пришло сообщение "МАРКЕР"
Б) Пришло сообщение "ЗАПРОС".
Выход из критической секции.
Если очередь запросов пуста, то при выходе
ничего не делается, иначе - перейти к пункту М1.
Алгоритм носит имя Ricart-Agrawala и является улучшением алгоритма, который предлжил Lamport.
Требуется глобальное упорядочение всех событий в системе по времени.
Вход в критическую секцию:
Когда процесс желает войти в критическую
секцию, он посылает всем процессам сообщение-запрос, содержащее имя критической
секции, номер процесса и текущее время. После посылки запроса процесс ждет, пока
все дадут ему разрешение. После получения от всех разрешения, он входит в
критическую секцию.
Поведение процесса при приеме запроса:
Когда процесс получает
сообщение-запрос, в зависимости от своего состояния по отношению к указанной
критической секции он действует одним из следующих способов.
Выход из критической секции:
После выхода из секции он посылает сообщение
"OK" всем процессам, запросы от которых он запомнил, а затем стирает все
запомненные запросы.
Количество сообщений на одно прохождение секции - 2(n-1), где n - число
процессов. Кроме того, одна критическая точка заменилась на n точек (если
какой-то процесс перестанет функционировать, то отсутствие разрешения от него
всех остановит). И, наконец, если в централизованном алгоритме есть опасность
перегрузки координатора, то в этом алгоритме перегрузка любого процесса приведет
к тем же последствиям. Некоторые улучшения алгоритма (например, ждать разрешения
не от всех, а от большинства) требуют наличия неделимых широковещательных
рассылок сообщений.
Маркер содержит:
Вход в критическую секцию:
Поведение процесса при приеме запроса:
Выход из критической секции процесса Pk:
Измерение производительности
Введем следующие три метрики.
При оценке производительности интересны две ситуации:
Для некоторых метрик интересно оценить наилучшее и наихудшее значение
(которые часто достигаются при низкой или высокой загрузки).
Сравнение алгоритмов.
При оценке времен исходим из коммуникационной
среды, в которой время одного сообщения (Т) равно времени
широковещательного сообщения.
|
Все алгоритмы не устойчивы к крахам процессов (децентрализованные даже более
чувствительны к ним, чем централизованный). Они в таком виде не годятся для
отказоустойчивых систем.
4.4 Координация процессов
 Содержание
курса Содержание
курса
| Далее: Лекция
5. |
© Лаборатория Параллельных Информационных
Технологий, НИВЦ МГУ![]()